飞腾ARM芯片-FT2500的性能测试
飞腾ARM芯片-FT2500的性能测试
ARM
ARM公司最早是由赫尔曼·豪泽(Hermann Hauser)和工程师Chris Curry在1978年创立(早期全称是 Acorn RISC Machine),后来改名为现在的ARM公司(Advanced RISC Machine)
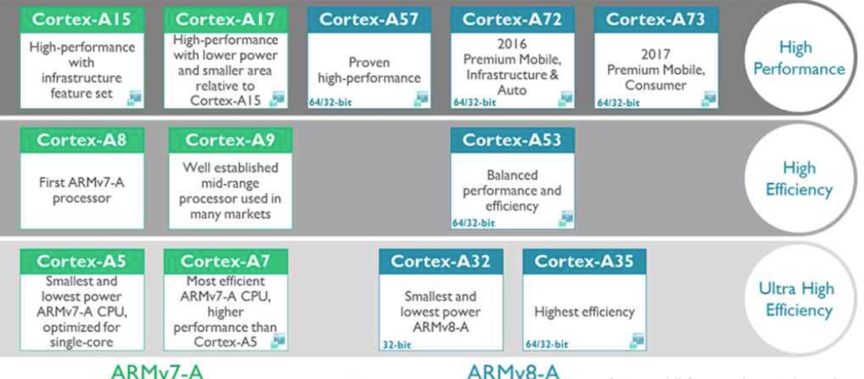
ARM 芯片厂家
查看厂家
#cat /proc/cpuinfo |grep implementer
CPU implementer : 0x70
#cat /sys/devices/system/cpu/cpu0/regs/identification/midr_el1
0x00000000701f6633 // 70 表示厂家
vendor id对应厂家
| Vendor Name | Vendor ID |
|---|---|
| ARM | 0x41 |
| Broadcom | 0x42 |
| Cavium | 0x43 |
| DigitalEquipment | 0x44 |
| HiSilicon | 0x48 |
| Infineon | 0x49 |
| Freescale | 0x4D |
| NVIDIA | 0x4E |
| APM | 0x50 |
| Qualcomm | 0x51 |
| Marvell | 0x56 |
| Intel | 0x69 |
| 飞腾 | 0x70 |
飞腾ARM芯片介绍
飞腾处理器,又称银河飞腾处理器,是由中国人民解放军国防科学技术大学研制的一系列嵌入式数字信号处理器(DSP)和中央处理器(CPU)芯片。[1]这个处理器系列的研发,是由国防科技大的邢座程教授[2]带领的团队负责研发。[3]其商业化推广则是由中国电子信息产业集团有限公司旗下的天津飞腾信息技术有限公司负责。
飞腾公司在早期,考察了SPARC、MIPS、ALPHA架构,这三种指令集架构都可以以极其低廉的价格(据说SPARC的授权价只有99美元,ALPHA不要钱)获得授权,飞腾选择了SPARC架构进行了CPU的研发。
2012年ARM正式推出了自己的第一个64位指令集处理器架构ARMv8,进入服务器等新的领域。此后飞腾放弃了SPARC,拿了ARMv8指令集架构的授权,全面转向了ARM阵营,芯片roadmap如下:
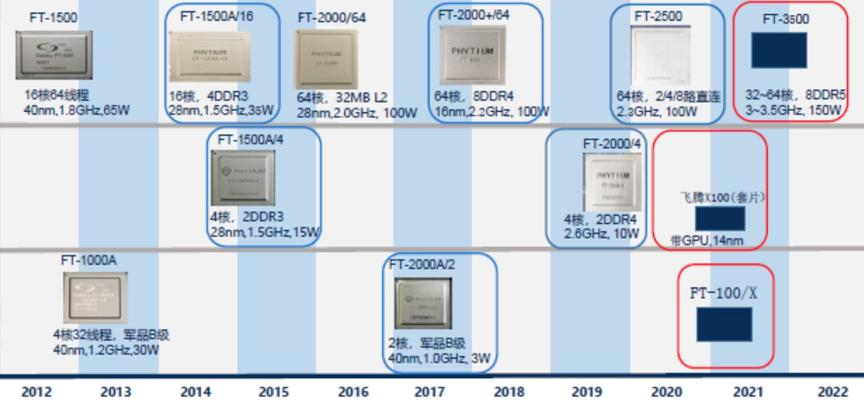
测试芯片详细信息
2020 年 7 月 23 日,飞腾发布新一代高可扩展多路服务器芯片腾云 S2500,采用 16nm 工艺, 主频 2.0~2.2Ghz,拥有 64 个 FTC663 内核,片内集成 64MB 三级 Cache,支持 8 个 DDR4-3200 存 储通道,功耗 150W。
基于 ARM 架构,兼具高可拓展性和低功耗,扩展支持 2 路到 8 路直连。与主流架构 X86 相比, ARM 架构具备低功耗、低发热和低成本的优势,ARM 单核的面积仅为 X86 核的 1/7,同样芯片尺寸下可以继承更多核心数,可以通过增加核心数提高性能,在性能快速提升下,也能保持较低的功耗,符合云计算场景下并行计算上高并发和高效率的要求,也能有效控制服务器的能耗和成本支出。腾云 S2500 增加了 4 个直连接口,总带宽 800Gbps,支持 2 路、4 路和 8 路直连,具备高可 拓展性,可以形成 128 核到 512 核的计算机系统,带动算力提升。
飞腾(FT2500), ARMv8架构,主频2.1G,服务器两路,每路64个物理core,没有超线程,总共16个numa,每个numa 8个core
1 | #dmidecode -t processor |

cpu详细信息:
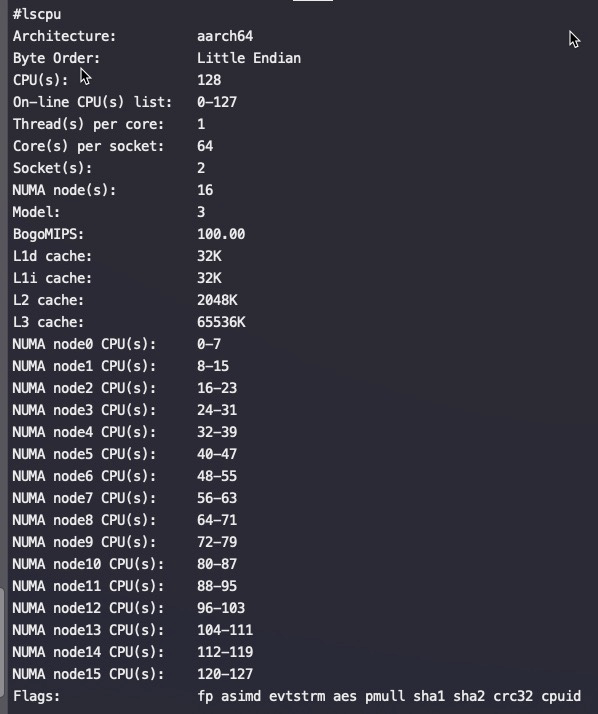
飞腾芯片,按如下distance绑核基本没区别!展示出来的distance是假的一样
FT2500芯片集成的 64 个处理器核心,划分为 8 个 Panel,每个 Panel 中有两个 Cluster (每个 Cluster 包含 4 个处理器核心及共享的 2M 二级 cache)、两个本地目录控 制部件(DCU)、一个片上网络路由器节点(Cell)和一个紧密耦合的访存控制 器(MCU)。Panel 之间通过片上网络接口连接,一致性维护报文、数据报文、 调测试报文、中断报文等统一从同一套网络接口进行路由和通信
一个Panel的实现是FTC663版本,采用四发射乱序超标量流水线结构,兼容 ARMv8 指令集,支持 EL0~EL3 多个特权级。流水线分为取指、译码、分派、执 行和写回五个阶段,采用顺序取指、乱序执行、顺序提交的多发射执行机制,取 值宽度、译码宽度、分派宽度均是 4 条指令,共有 9 个执行部件(或者称为 9 条功能流水线),分别是 4 个整数部件、2 个浮点部件、1 个 load 部件、1 个 load/store 部件和 1 个系统管理指令执行部件。浮点流水线能够合并执行双路浮点 SIMD 指 令,实现每拍可以执行 4 条双精度浮点操作的峰值性能。
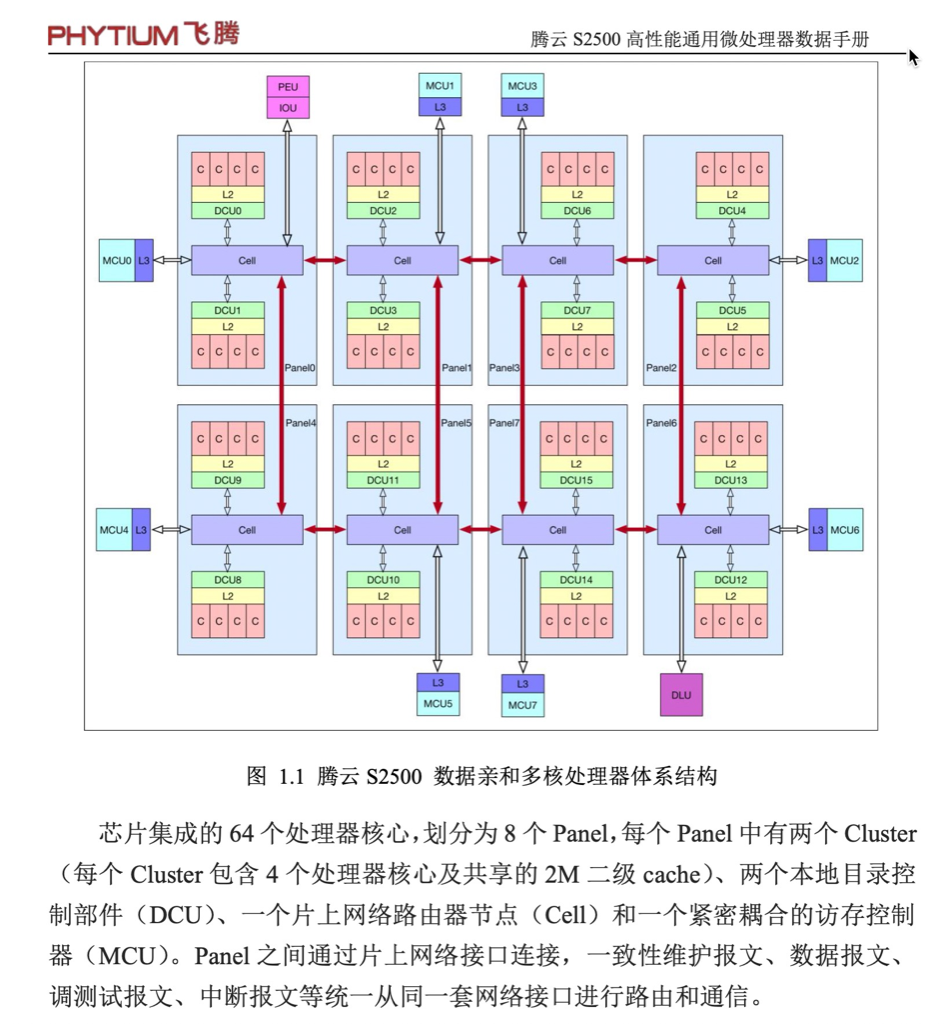
猜测FT2500 64core用的是一个Die, 但是core之间的连接是Ring Bus,而Ring Bus下core太多后延迟会快速增加,所以一个Die 内部做了8个小的Ring Bus,每个Ring Bus下8个core。
飞腾官方提供的测试结果
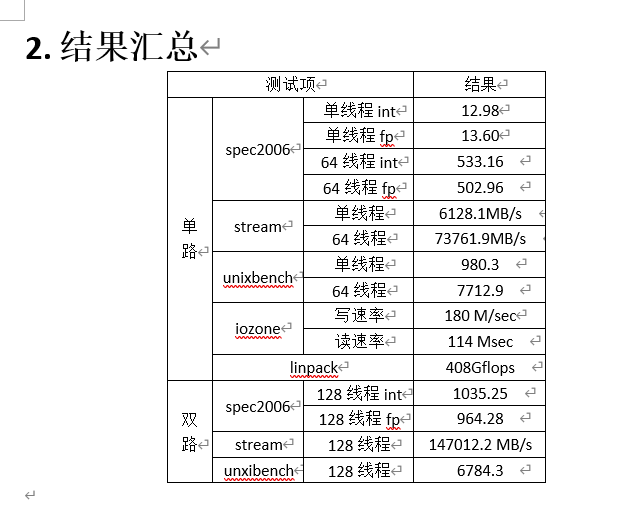
飞腾2500 和 鲲鹏9200 参数对比
FT2000与FT2500差异
下表是FT2000和FT2500产品规格对比表,和芯片的单核内部结构变化较少,多了L3,主频提高了,其他基本没有变化。
| 特征 | FT-2000+/64 | FT-2500 |
|---|---|---|
| 指令 | 兼容 ARM V8 指令集 FTC662 内核 | 兼容 ARM V8 指令集FTC663 内核 |
| Core数 | 64个 | 64个 |
| 频率 | 2.2GHZ/2.0GHZ/1.8GHZ | 2.0~2.3GHz |
| 体系架构 | NUMA | NUMA |
| RAS | 无 | 支持 |
| 加解密 | 无 | ASE128、SHA1、SHA2-256、PMULL |
| L1 Cache | 每个核独占32KB指令Cache与32KB数据Cache | 每个核独占32K指令Cache与32K数据Cache |
| L2 Cache | 共32MB,每4个核共享2MB | 共32MB,每4个核共享2MB |
| L3 Cache | 无 | 64MB |
| LMU数量 | 8个 | 8个 |
| 支持最大容量 | 1TB | 1TB*socket数量 |
| 支持最大频率 | 3200MHZ | 支持3200MHZ |
| 外接设备 | 支持带 ECC 的 DDR4 DIMM,支持 RDIMM、UDIMM、SODIMM、 LR-DIMM,电压 1.2V | 支持带 ECC 的 DDR4 DIMM,支持 RDIMM、UDIMM、SODIMM、LR-DIMM,电压 1.2V |
| 镜像存储 | 无 | 每两个MCU互为备份 |
| PCIe | PCIE3.02 个 x16 和 1 个 x1每个 x16 可拆分成 2 个 x8,支持翻转 | PCIE3.01 个 x16 和 1 个 x1x16 可拆分成 2 个 x8,支持翻转 |
| SPI | 支持 4 个片选,单片最大支持容量为 512MB,电压 1.8V | 支持 4 个片选,单片最大支持容量为 512MB,电压 1.8V |
| UART | 4个 UART,其中 1 个为 9 线全功能串口,3 个为 3 线调试串口 | 4个 UART,其中 1 个为 9 线全功能串口,3 个为 3 线调试串口 |
| GPIO | 4 个 8 位 GPIO 接口,GPIOA[0:7],GPIOB[0:7],GPIOC[0:7], GPIOD[0:7] | 4 个 8 位 GPIO 接口,GPIOA[0:7],GPIOB[0:7],GPIOC[0:7], GPIOD[0:7] |
| LPC | 1 个 LPC 接口,兼容 Intel Low Pin Count 协议, 电压 1.8V | 1 个 LPC 接口,兼容 Intel Low Pin Count 协议, 电压 1.8V |
| I2C | 2 个 I2C master 控制器 | 2 个 I2C master /Slave控制器,2个slave控制器 |
| 直连 | 无 | 四个直连通路,每路X4个lane,每条lane速率为25Gbps,支持2路、4路、8路 |
飞腾ARM芯片性能测试数据
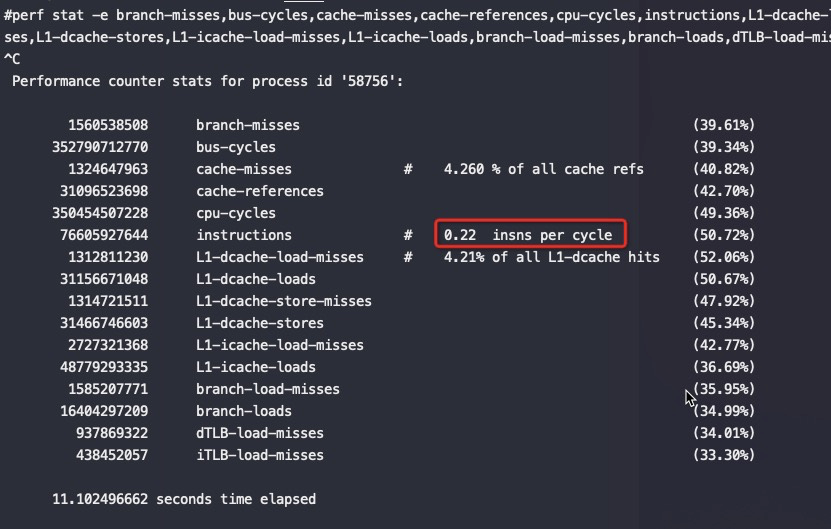
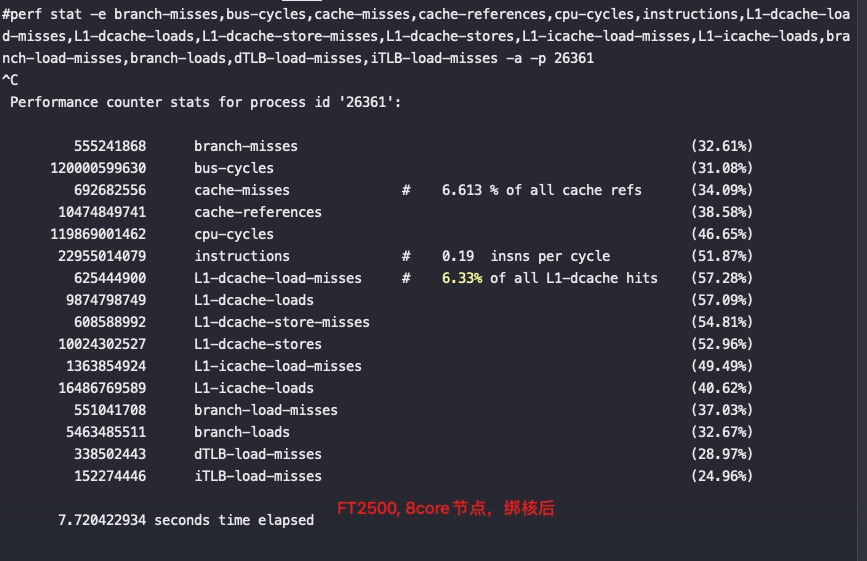
以下测试场景基本都是运行CPU和网络瓶颈的业务逻辑,绑核前IPC只有0.08
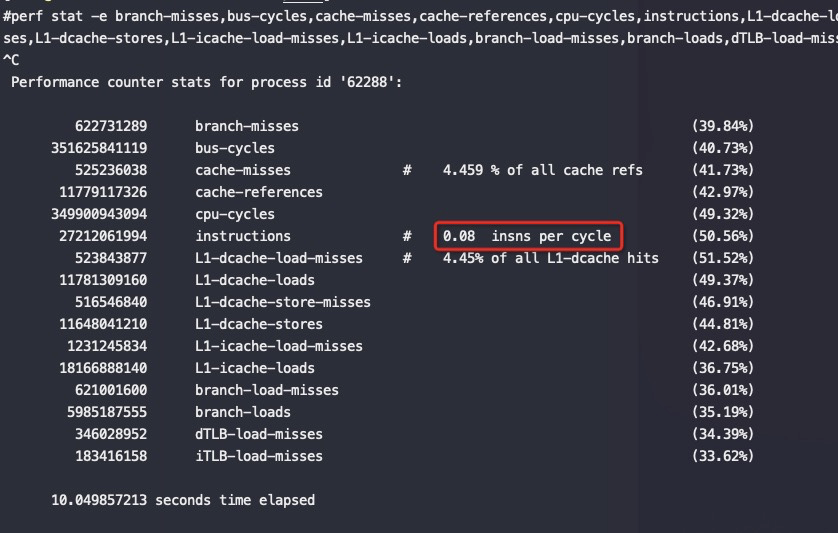
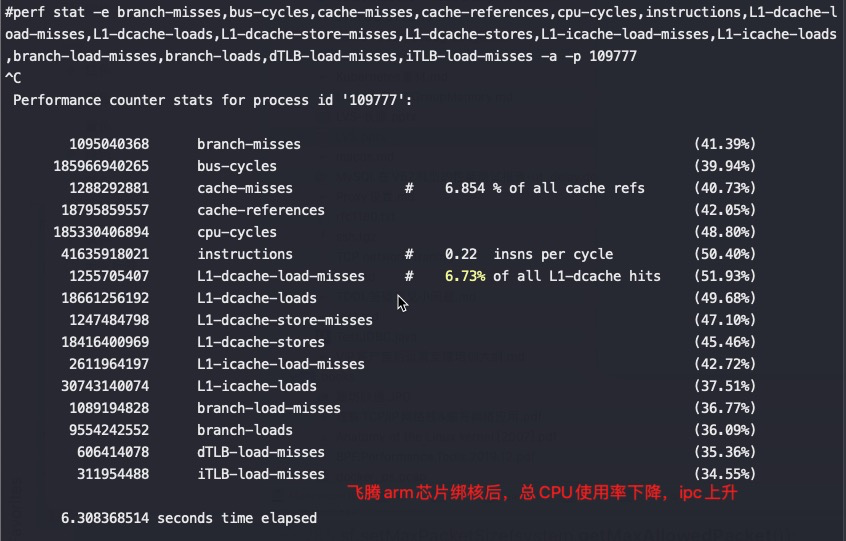
绑核后对性能提升非常明显:
点查场景:
如上是绑48-63号核
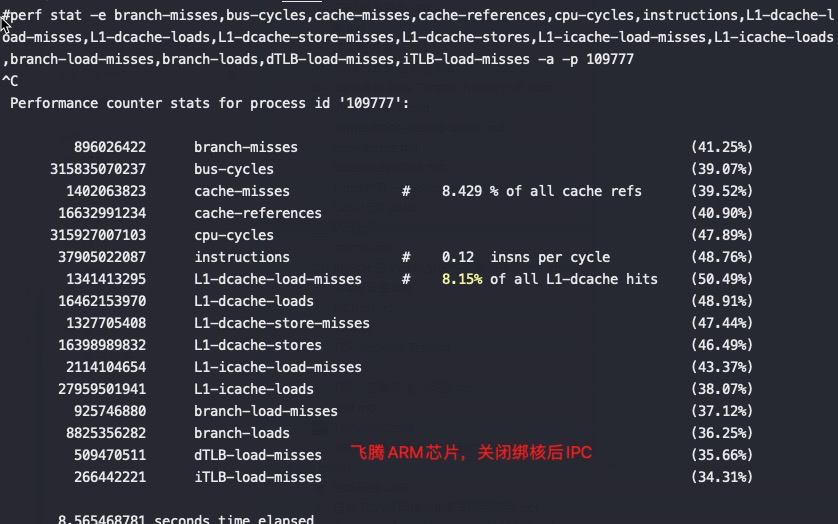
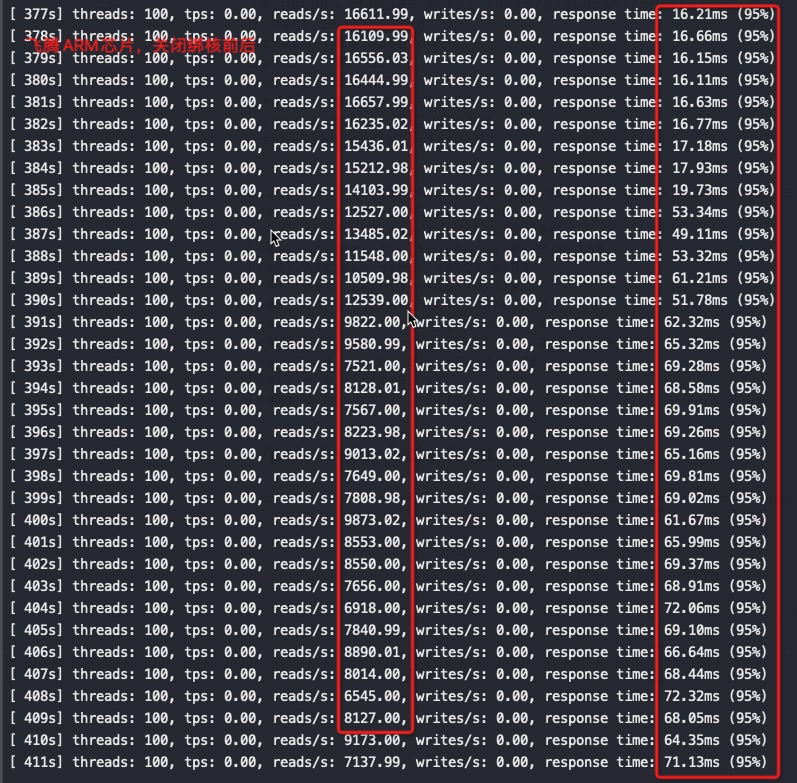
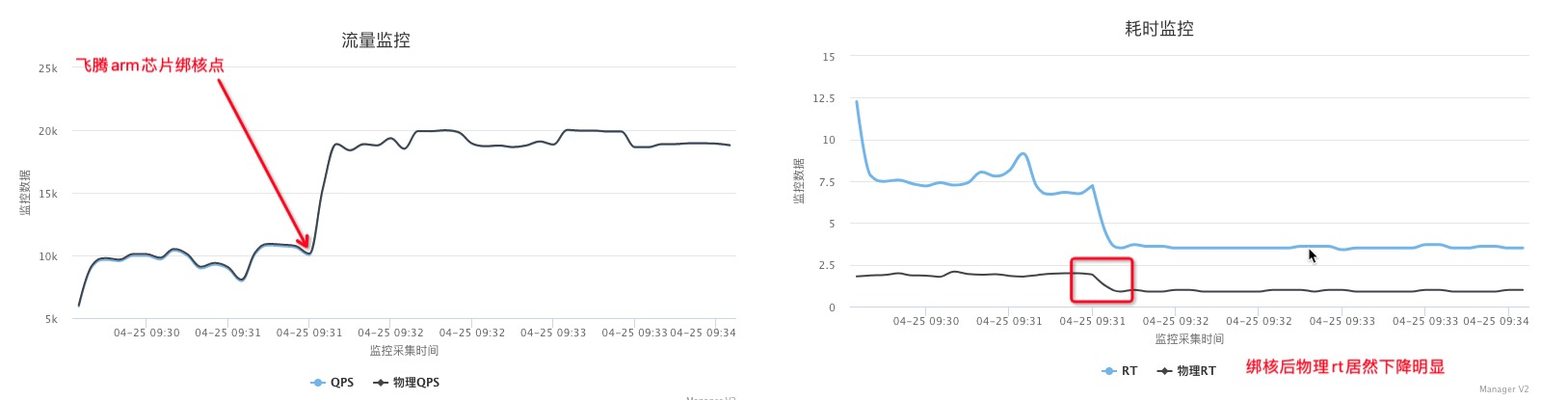
绑不同的核性能差异比较大,比如同样绑第一个socket最后16core和绑第二个socket最后16core,第二个socket的最后16core性能要好25-30%—这是因为网卡软中断,如果将软中断绑定到0-4号cpu后差异基本消失,因为网卡队列设置的是60,基本跑在前60core上,也就是第一个socket上。
点查场景绑核和不绑核性能能差1倍, 将table分表后,物理rt稳定了(截图中物理rt下降是因为压力小了–待证)
点查场景压测16个core的节点
一个节点16core,16个core绑定到14、15号NUMA上,然后压测
1 | #perl numa-maps-summary.pl </proc/79694/numa_maps //16core |
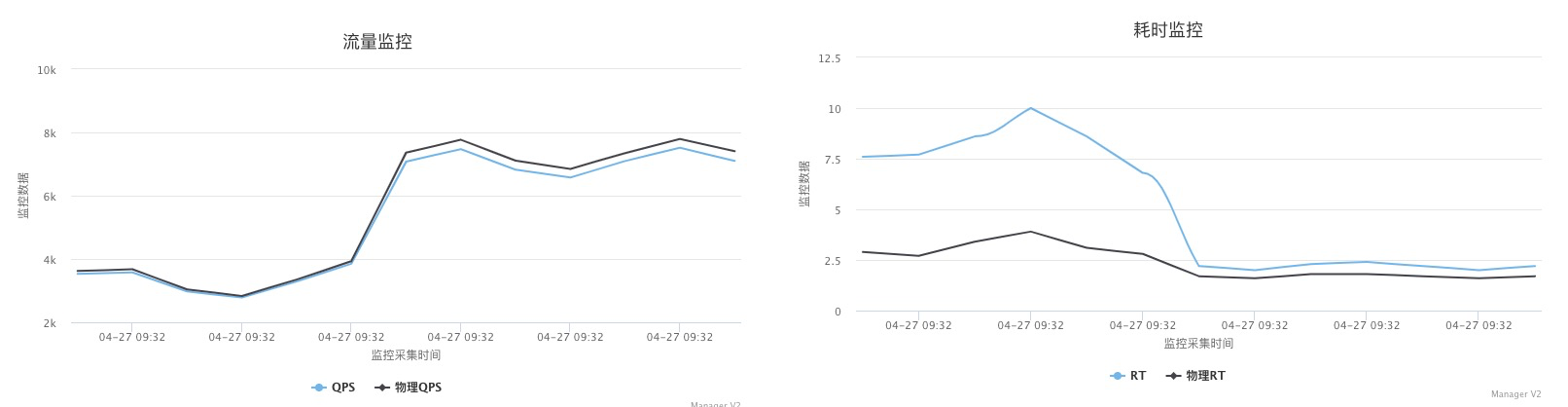
点查场景压测8个core的节点
因为每个NUMA才8个core,所以测试一下8core的节点绑核前后性能对比。实际结果看起来和16core节点绑核性能提升差不多。
绑核前后对比:绑核后QPS翻倍,绑核后的服务rt从7.5降低到了2.2,rt下降非常明显,可以看出主要是绑核前跨numa访问慢。实际这个测试是先跑的不绑核,内存分布在所有NUMA上,没有重启再绑核就直接测试了,所以性能提升不明显,因为内存已经跨NUMA分配完毕了。
1 | perl numa-maps-summary.pl </proc/33727/numa_maps //绑定8core后,在如下内存分配下QPS能到11000,但是抖动略大,应该是一个numa内存不够了 |
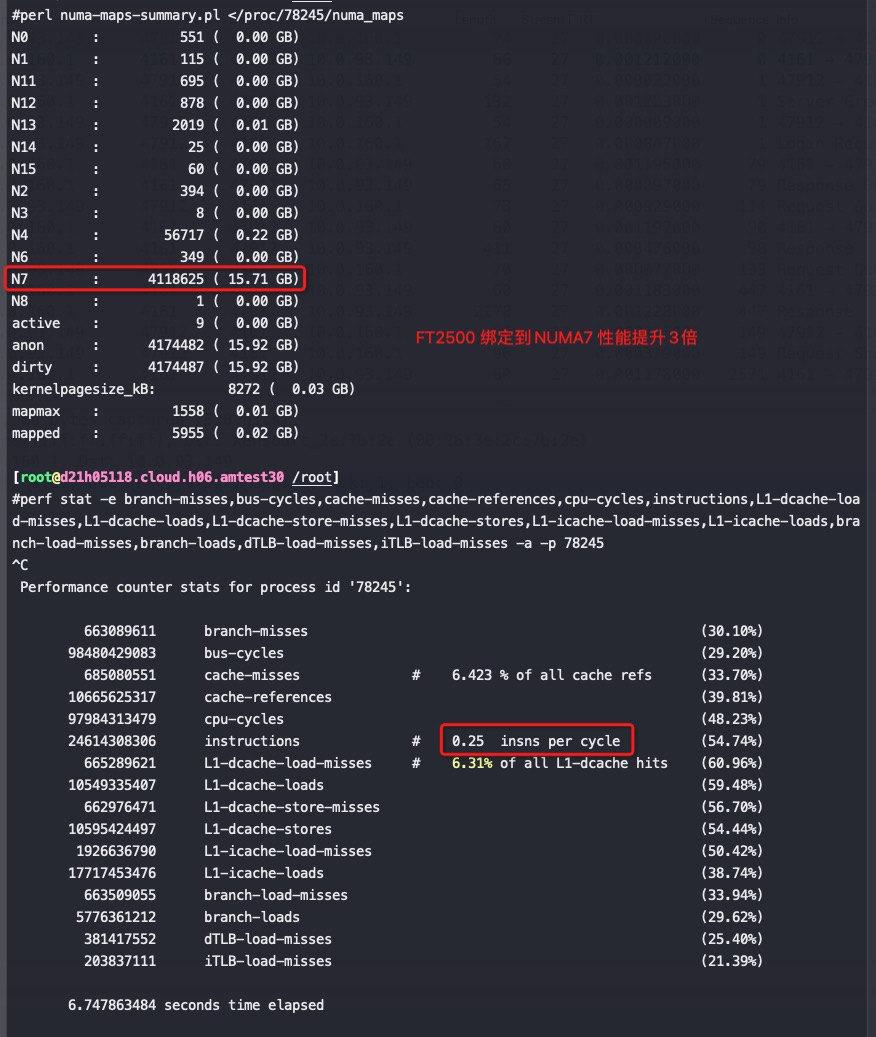
绑核前的IPC:
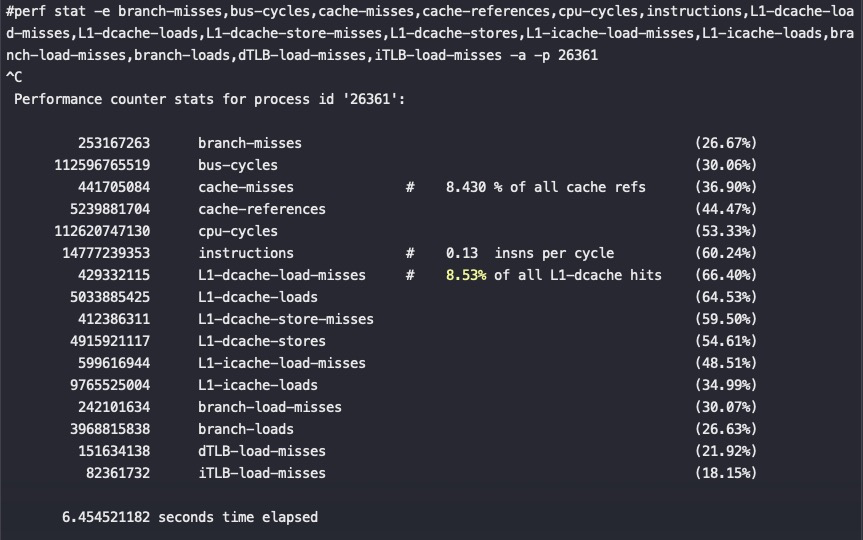
绑核后的IPC:
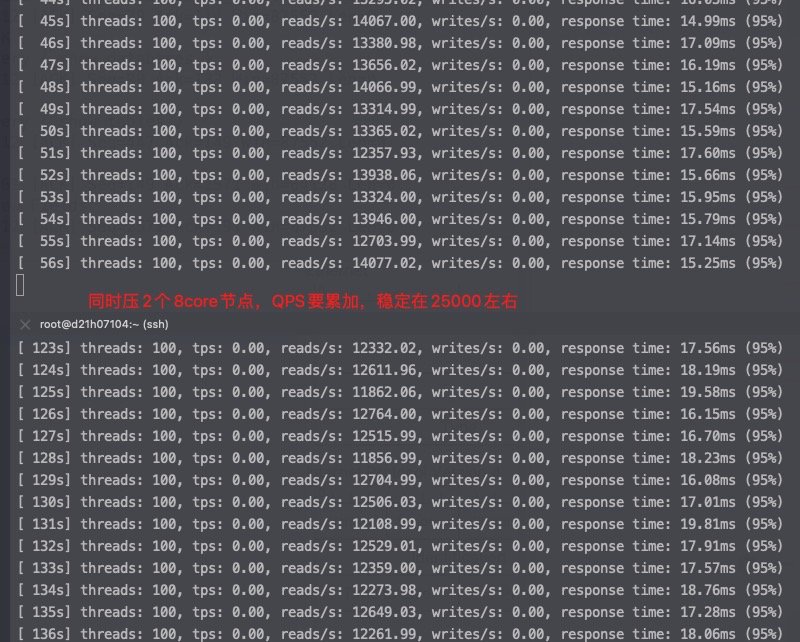
如果是两个8core对一个16core在都最优绑核场景下从上面的数据来看能有40-50%的性能提升,并且RT抖动更小,这两个8core绑定在同一个Socket下,验证是否争抢,同时可以看到绑核后性能可以随着加节点线性增加
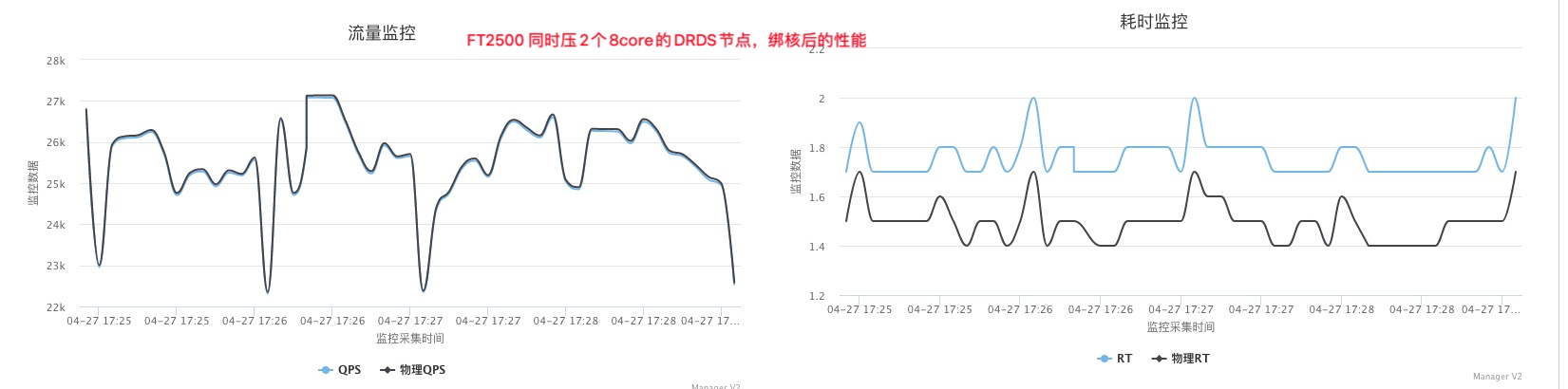
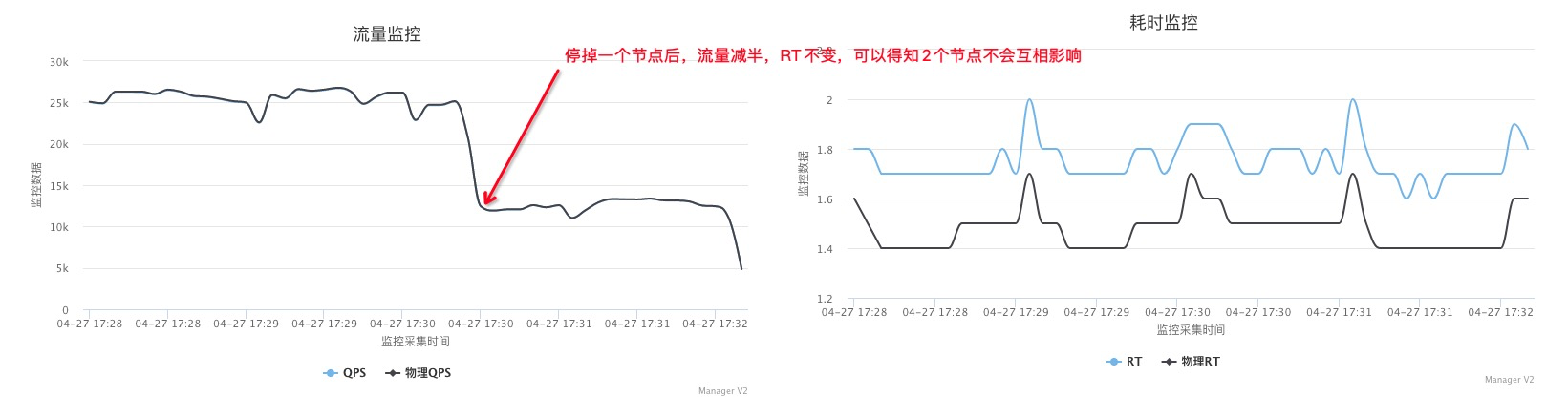
结论:不绑核一个FT2500的core点查只有500 QPS,绑核后能到1500QPS, 在Intel 8263下一个core能到6000以上(开日志、没开协程)
MySQL 数据库场景绑核
通过同一台物理上6个Tomcat节点,总共96个core,压6台MySQL,MySQL基本快打挂了。sysbench 点查,32个分表,增加Tomcat节点进来物理rt就增加,从最初的的1.2ms加到6个Tomcat节点后变成8ms。
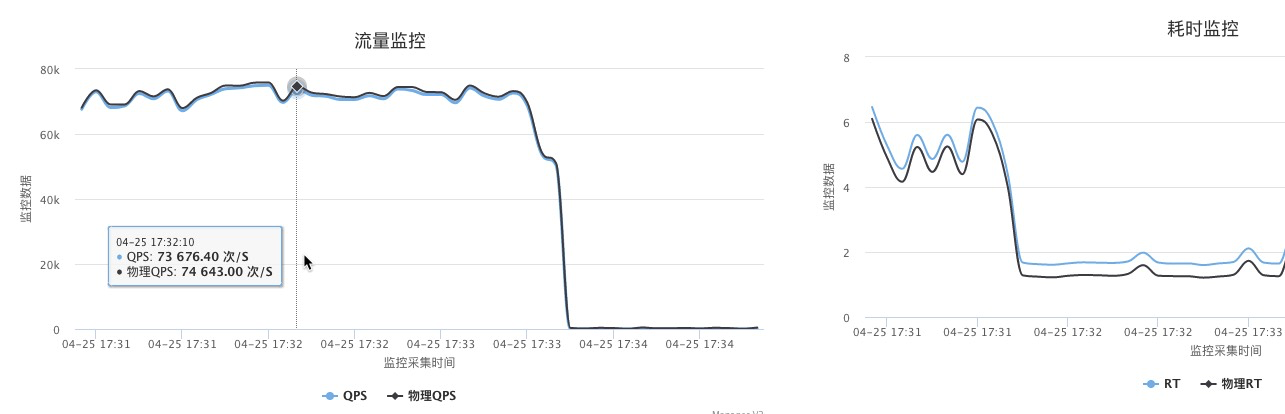
MySQL没绑好核,BIOS默认关闭了NUMA,外加12个MySQL分布在物理机上不均匀,3个节点3个MySQL,剩下的物理机上只有一个MySQL实例。
MySQL每个实例32core,管控默认已经做了绑核,但是如果两个MySQL绑在了一个socket上竞争会很激烈,ipc比单独的降一半。
比如这三个MySQL,qps基本均匀,上面两个cpu高,但是没效率,每个MySQL绑了32core,上面两个绑在一个socket上,下面的MySQL绑在另一个socket上,第一个socket还有网络软中断在争抢cpu,飞腾环境下性能真要冲高还有很大空间。
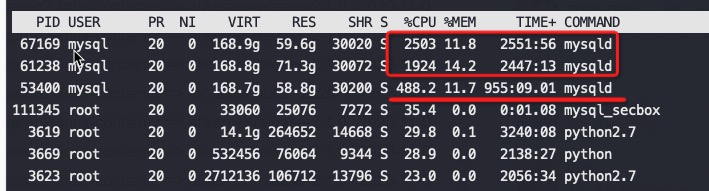
1 | 第二个MySQL IPC只有第三个的30%多点,这就是为什么CPU高这么多,但是QPS差不多 |
12个MySQL流量基本均匀:
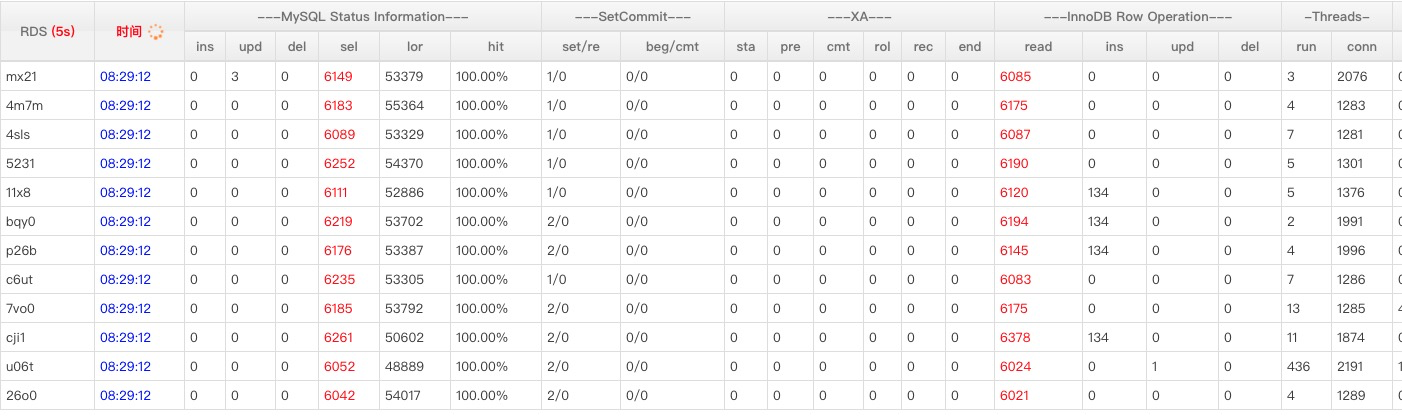
numa太多,每个numa下core比较少
导致跨numa高概率发生,如下是在正常部署下的测试perf 数据,可以看到IPC极低,才0.08,同样的场景在其他家芯片都能打到0.6
执行绑核,将一个进程限制在2个numa内,因为进程需要16core,理论上用8core的进程性能会更好
可以看到IPC从0.08提升到了0.22,实际能到0.27,对应的业务测试QPS也是原来的4倍。
用numactl 在启动的时候绑定cpu在 node0、1上,优先使用node0、1的内存,不够再用其它node的内存
1 | numactl --cpunodebind 0,1 --preferred 0,1 /u01/xcluster80/bin/mysqld_safe --defaults-file=/polarx/xcluster3308/my.cnf --basedir=/u01/xcluster80_current --datadir=/polarx/xcluster3308/data --plugin-dir=/u01/xcluster80/lib/plugin --user=mysql --log-error=/polarx/xcluster3308/log/alert.log --open-files-limit=615350 --pid-file=/polarx/xcluster3308/run/mysql.pid --socket=/polarx/xcluster3308/run/mysql.sock --cluster-info=11.158.239.200:11308@1 --mysqlx-port=13308 --port=3308 |
网卡队列调整
这批机器默认都是双网卡做bond,但是两块网卡是HA,默认网卡队列是60,基本都跑在前面60个core上
将MySQL网卡队列从60个改成6个后MySQL性能提升大概10%
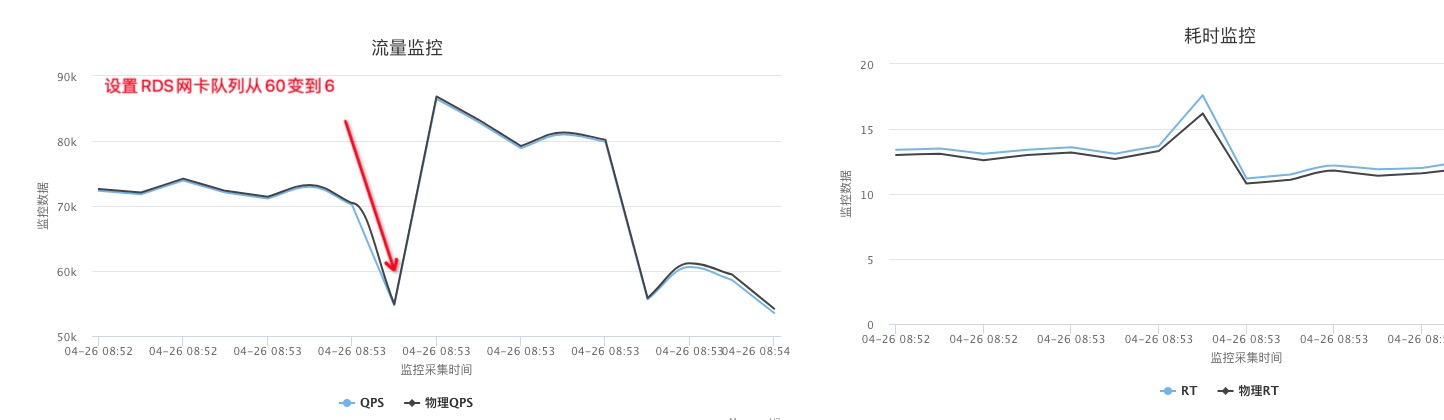
默认第一个MySQL都绑在0-31号核上,其实改少队列加大了0-5号core的压力,但是实际数据表现要好。
比较其它
绑核的时候还要考虑磁盘、网卡在哪个socket上,相对来说node和磁盘、网卡在同一个socket下性能要好一些。
左边的mysqld绑定在socket1的64core上,磁盘、网卡都在socket1上;右边的mysqld绑定在0-31core上,网卡在socket0上,但是磁盘在socket1上
右边这个刚好是跨socket访问磁盘,不知道是不是巧合log_flush排位比较高
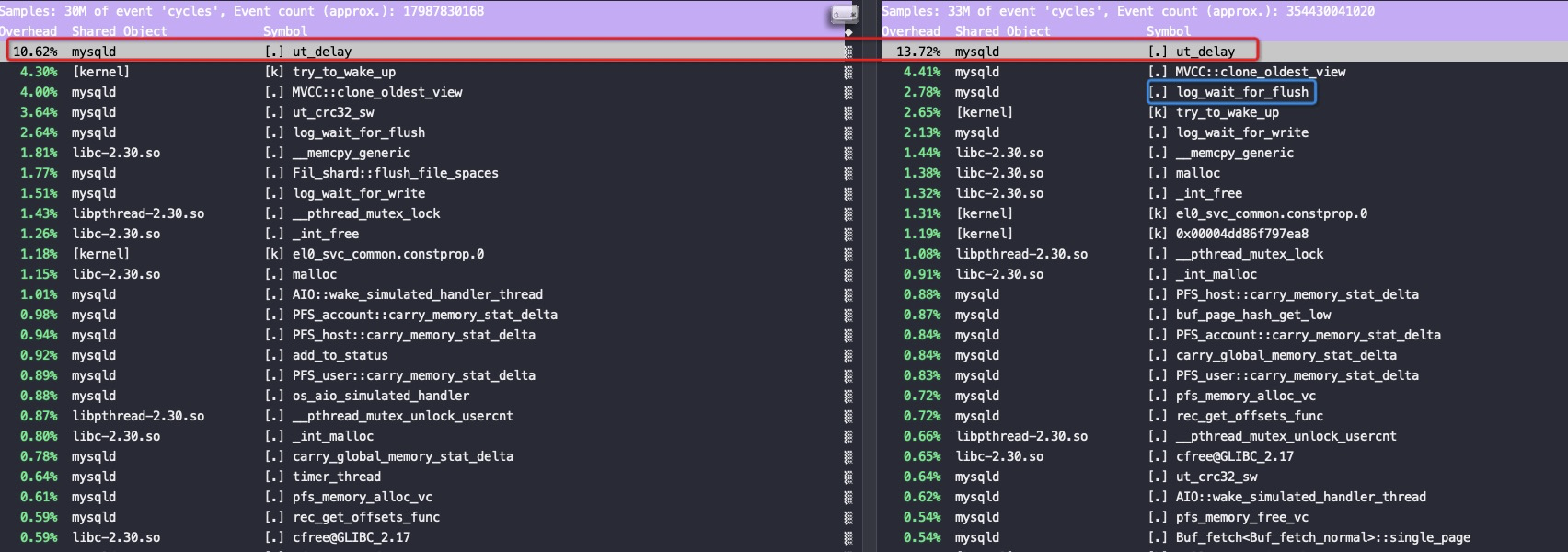
此时对应的IPC:
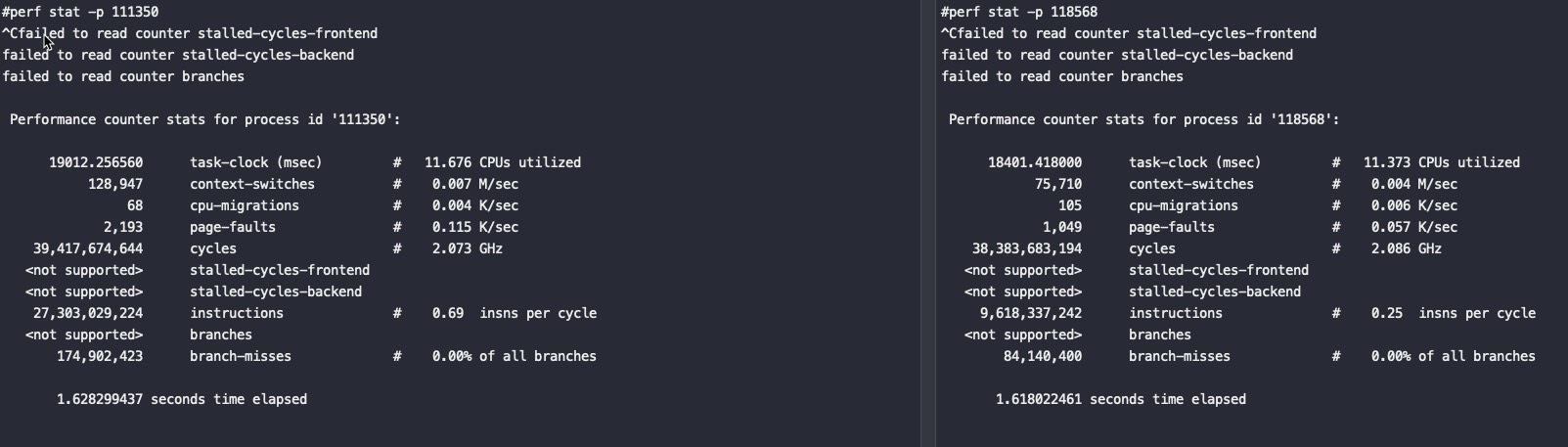
如果上面两个进程在没有刷日志的场景下时候对应的IPC两者基本一样:
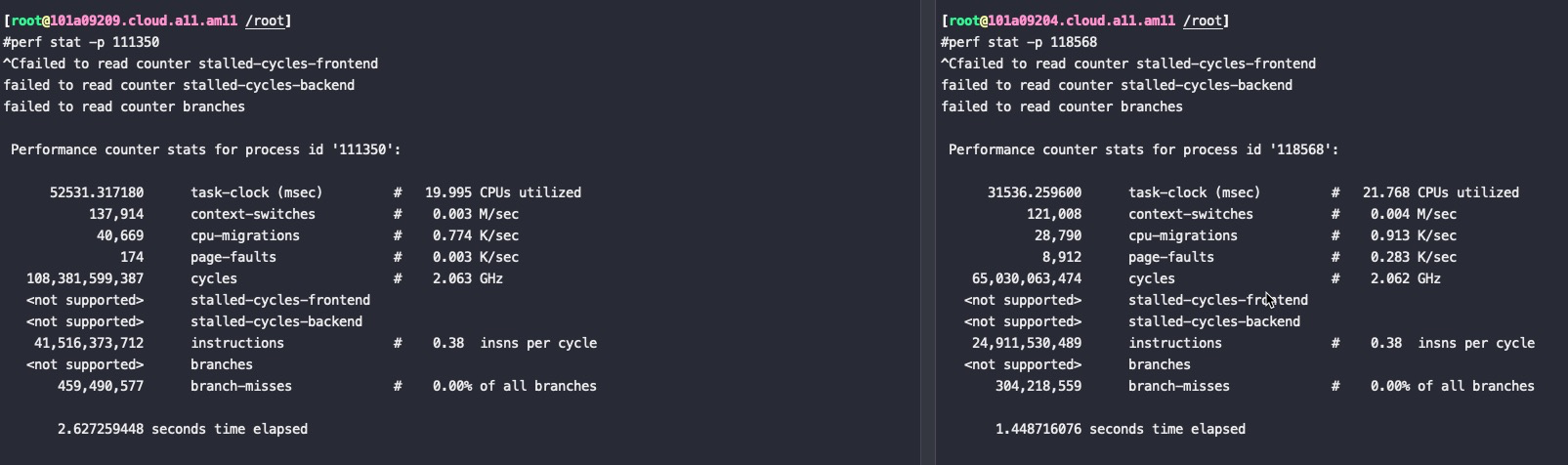
结论
FT2500比同主频Intel x86芯片差了快一个数量级的性能,在对FT2500上的业务按node绑核后性能提升了几倍,但是离Intel x86还有很大的距离
用循环跑多个nop指令在飞腾2500下IPC只能跑到1,据说这是因为nop指令被扔掉了,所以一直在跑跳转循环判断;
对寄存器变量进行++运算,IPC是0.5;
用如下代码能将IPC跑到2.49,也是我能跑出来的最高IPC了,去掉nop那行,IPC是1.99
1 | register unsigned i=0; |
系列文章
[CPU 性能和Cache Line](/2021/05/16/CPU Cache Line 和性能/)
[Perf IPC以及CPU性能](/2021/05/16/Perf IPC以及CPU利用率/)
[Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的](/2019/12/16/Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的/)