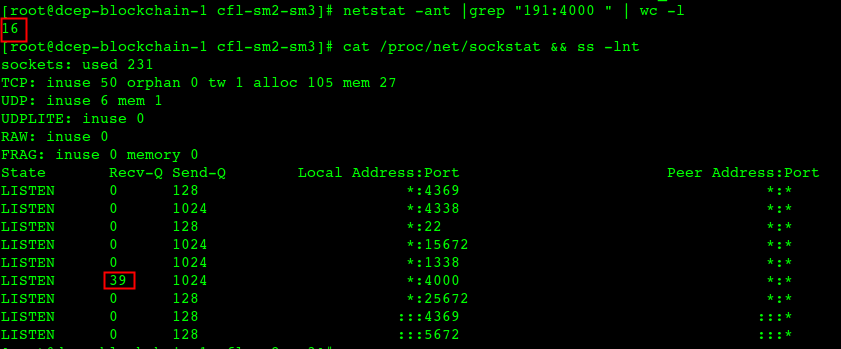
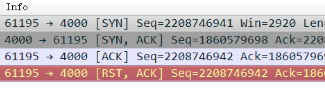
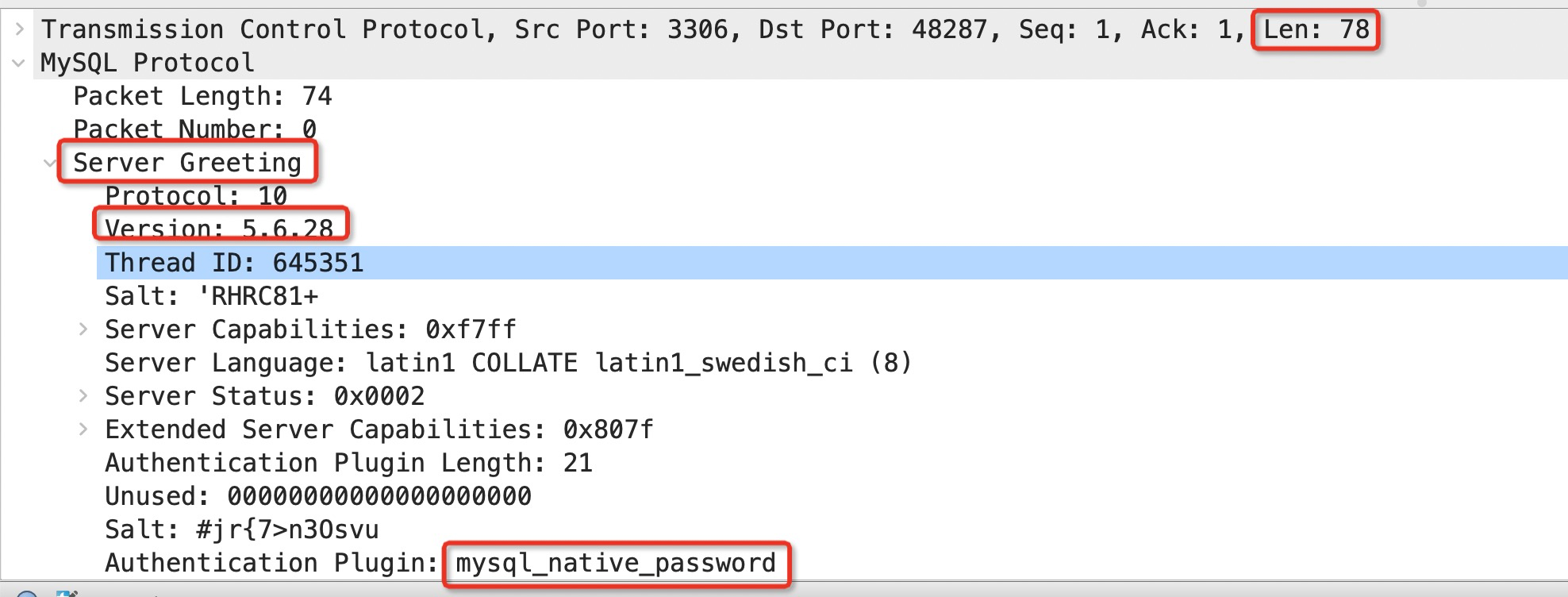
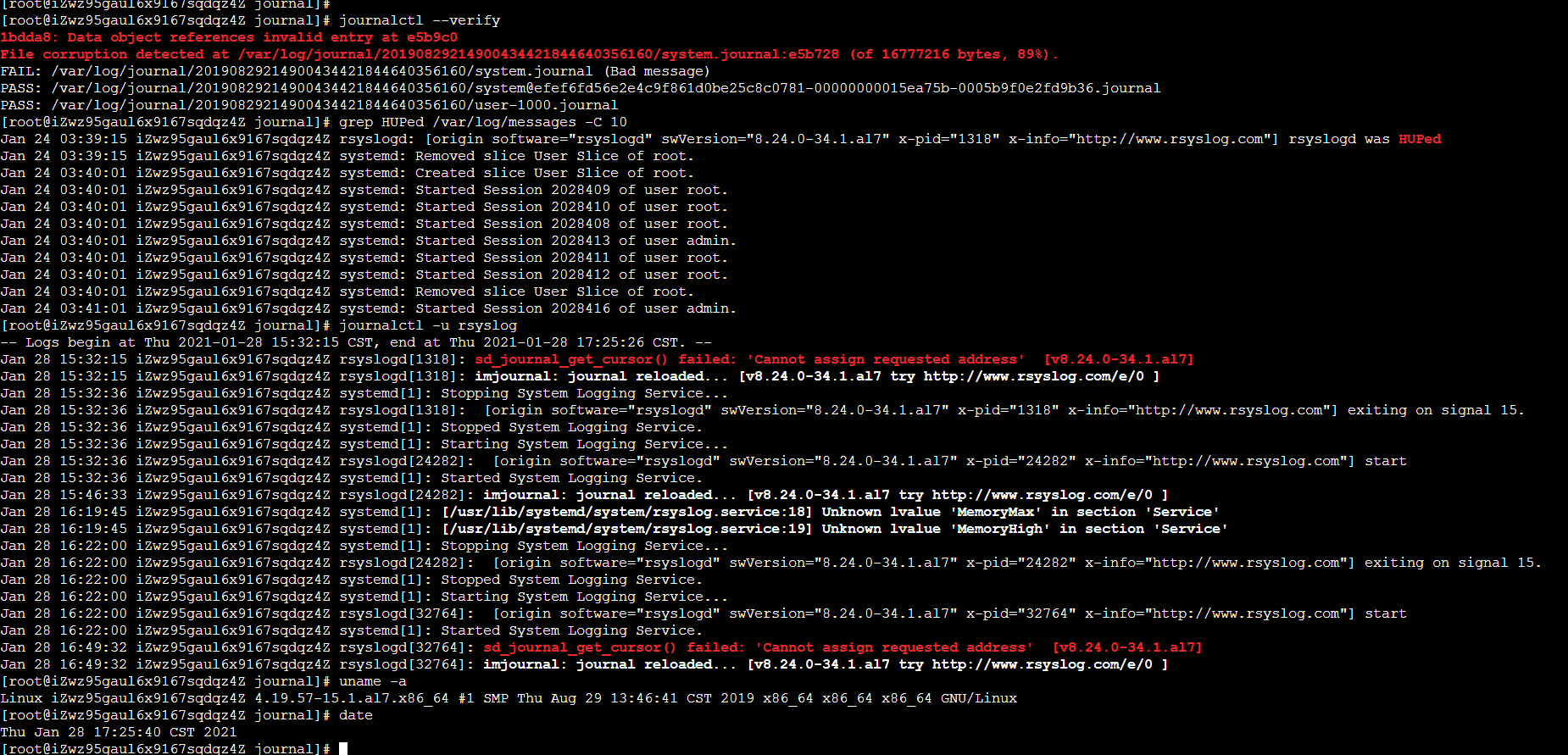
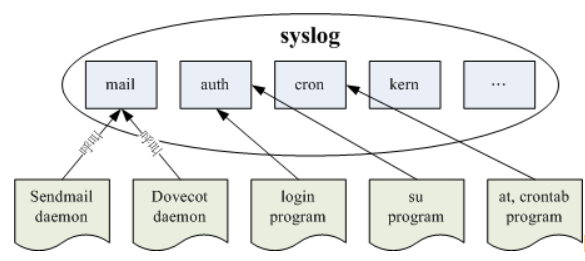
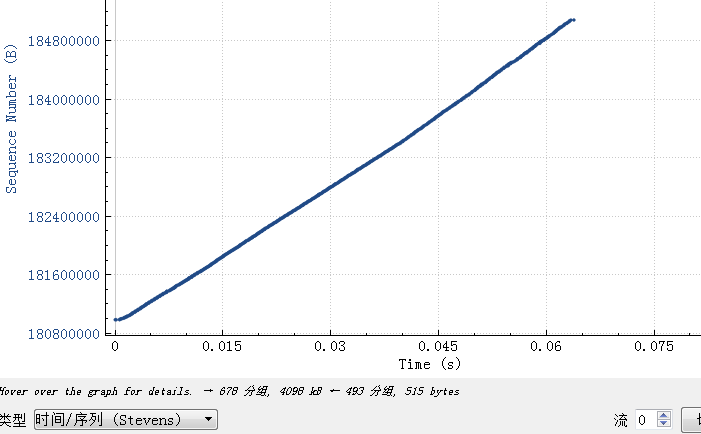
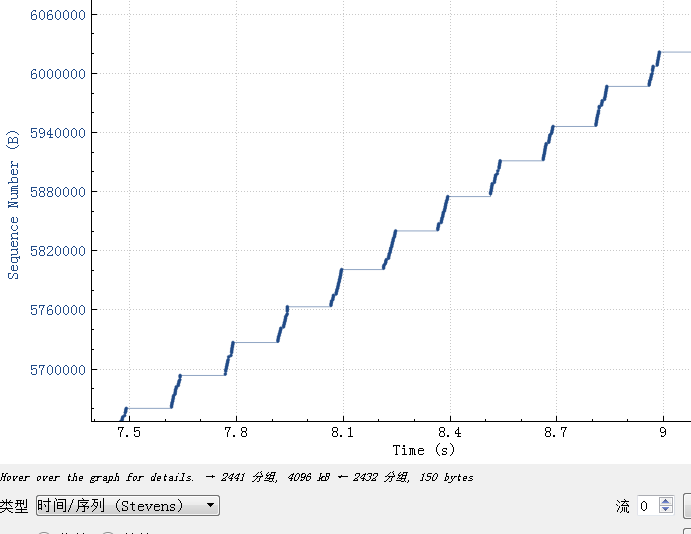
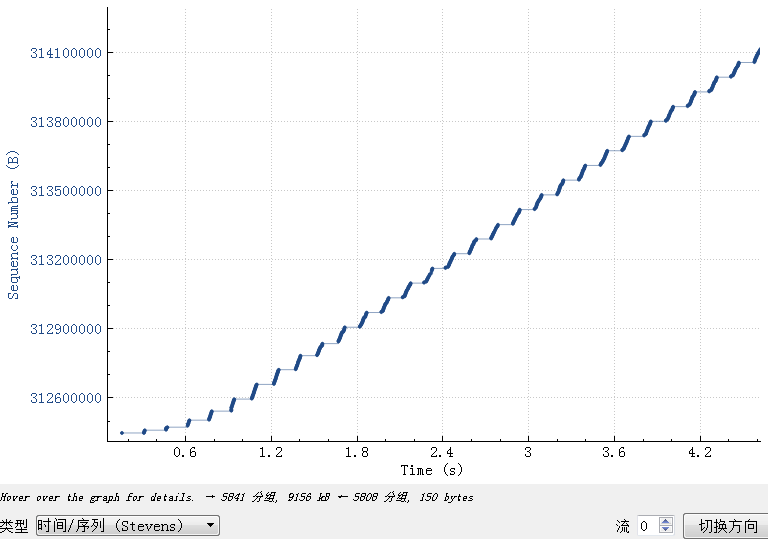
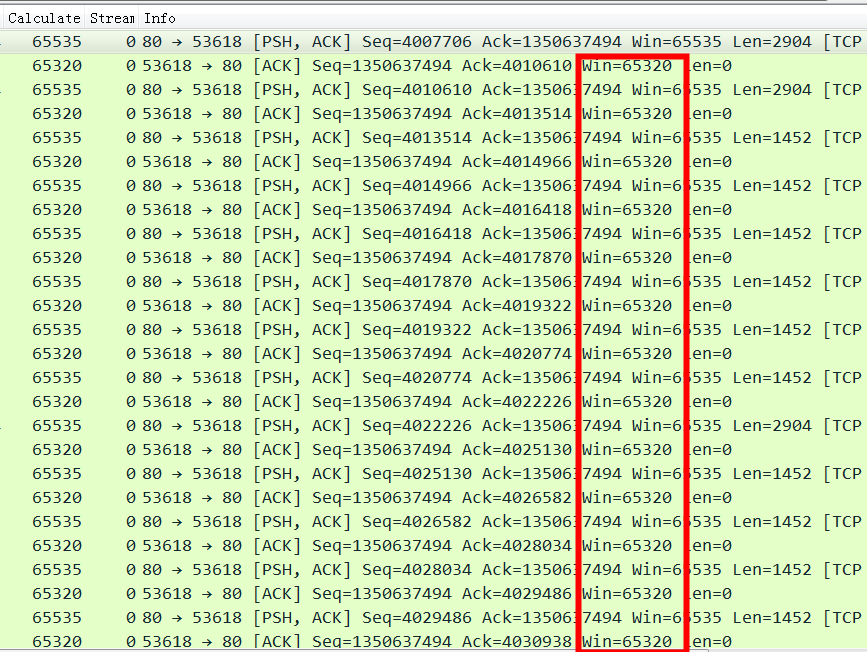
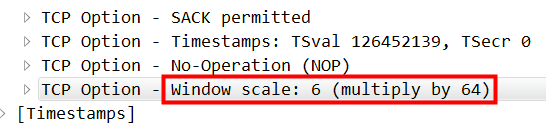
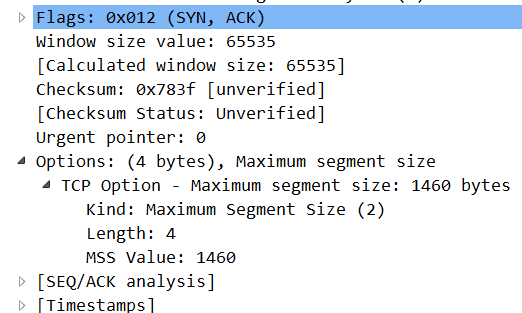
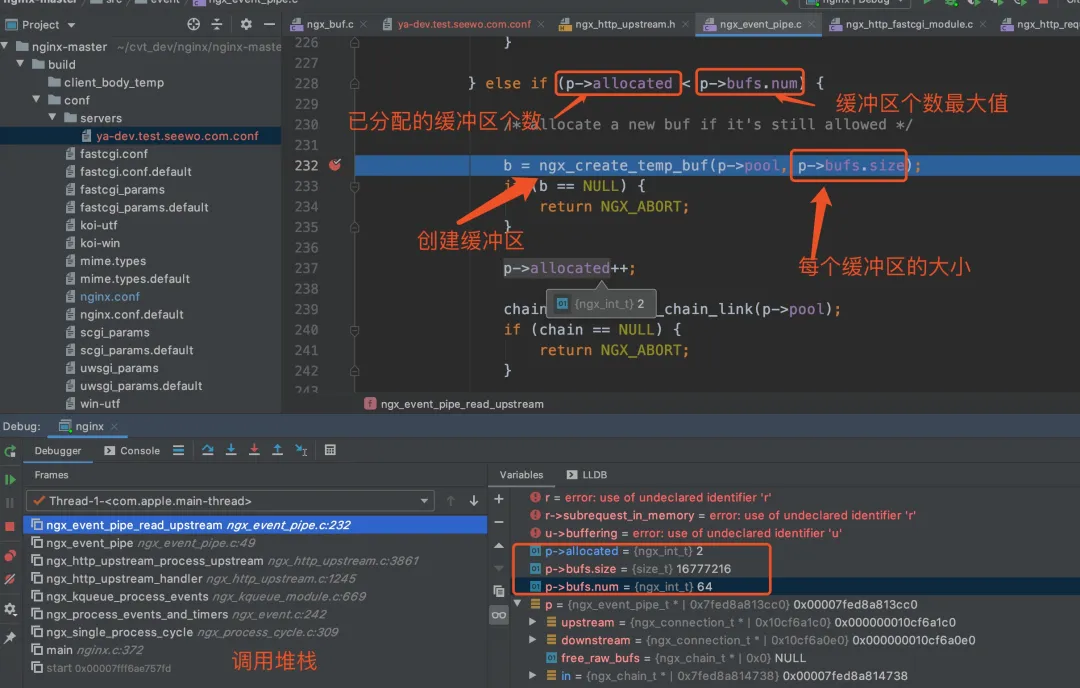
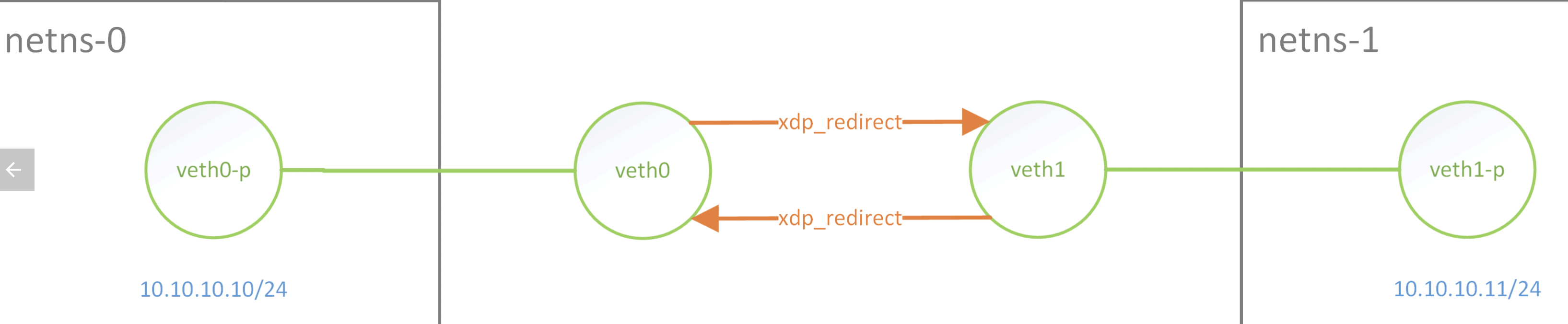
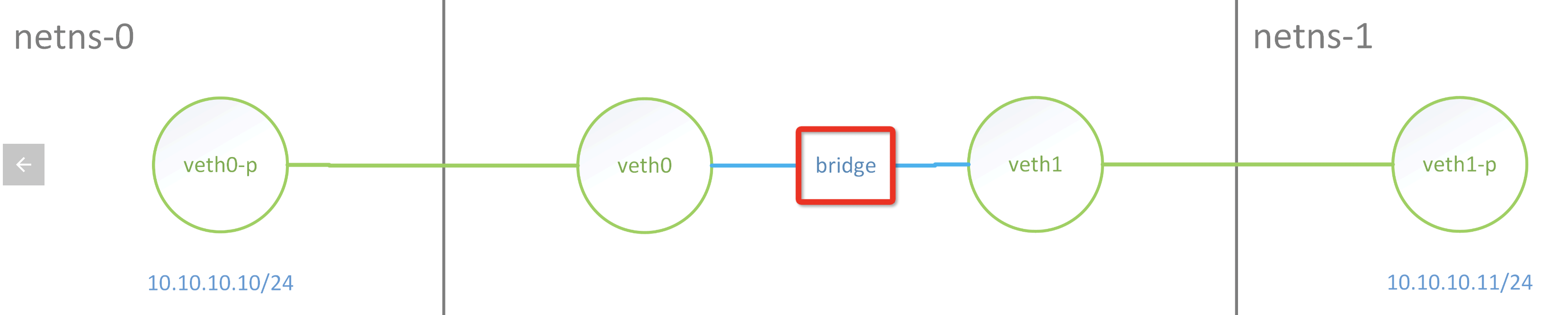
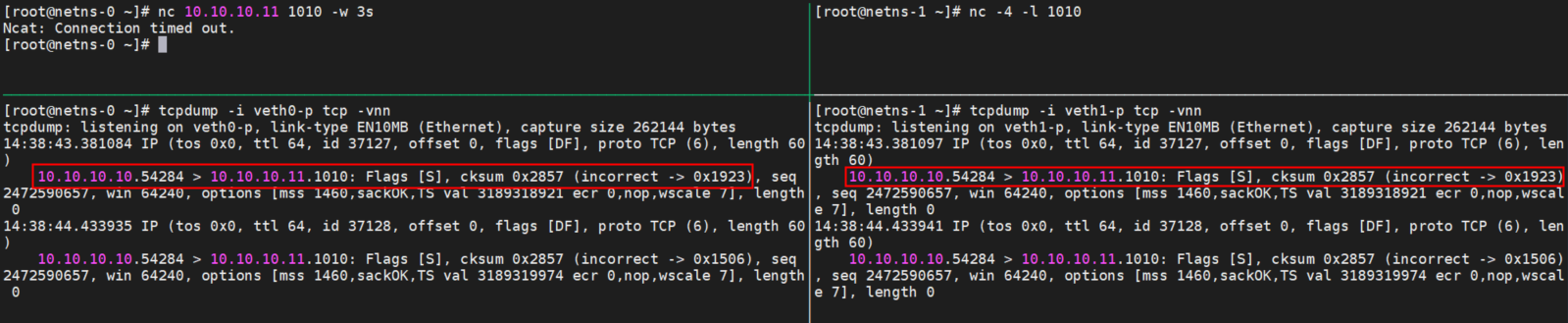
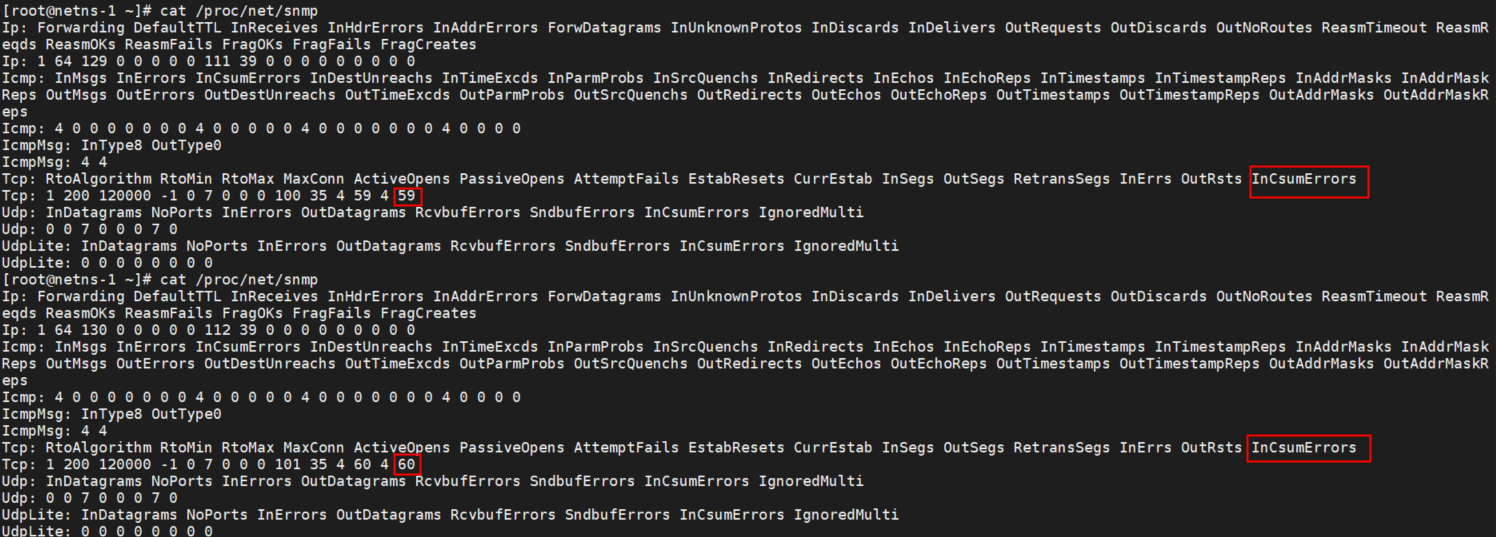
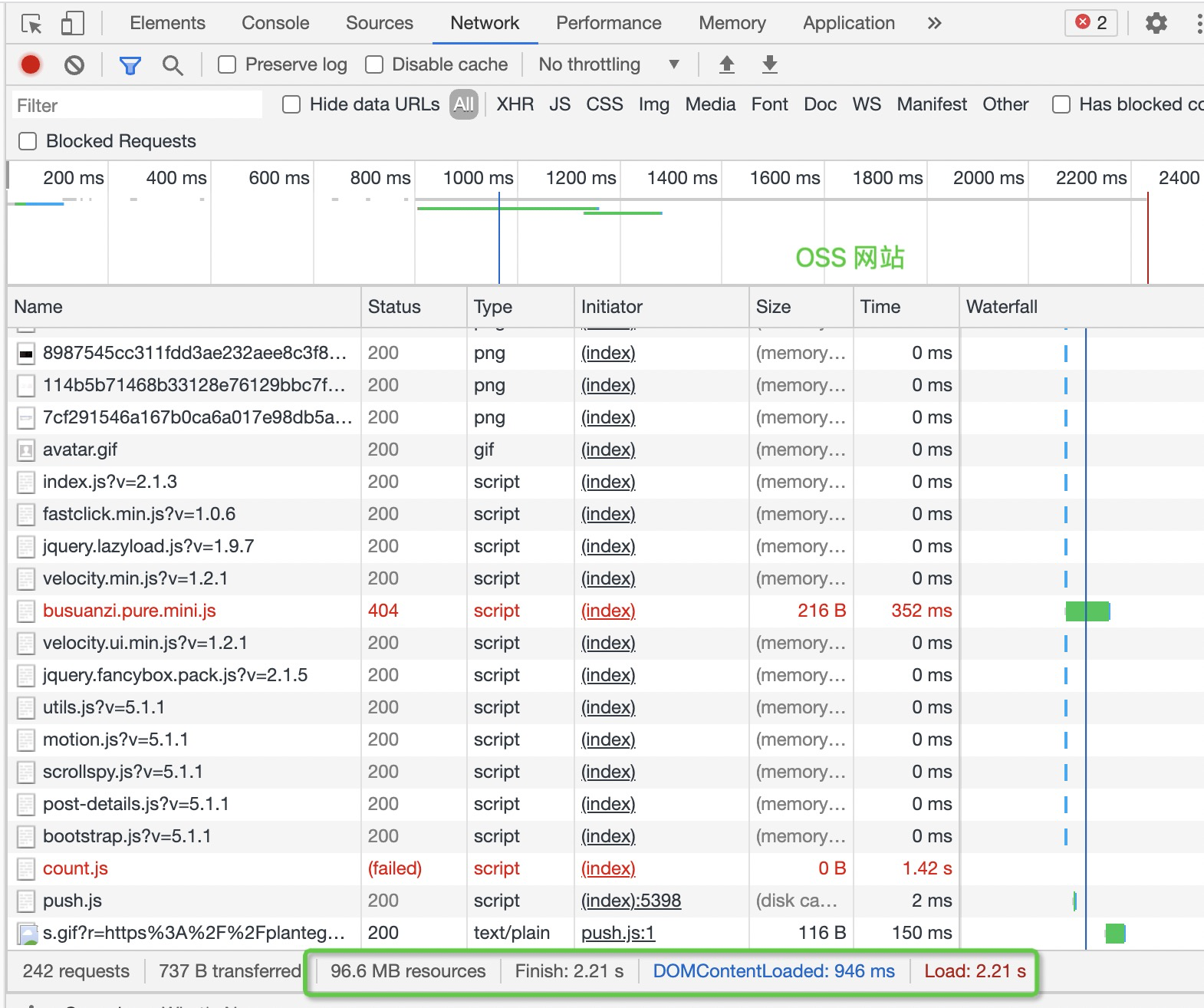
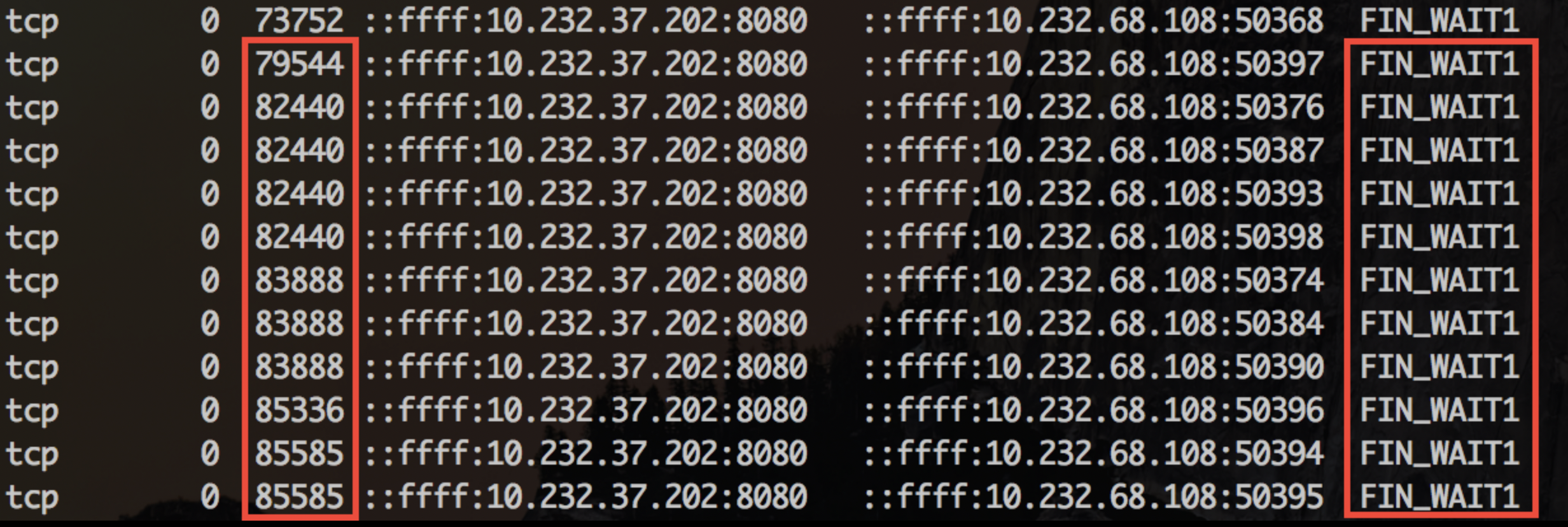
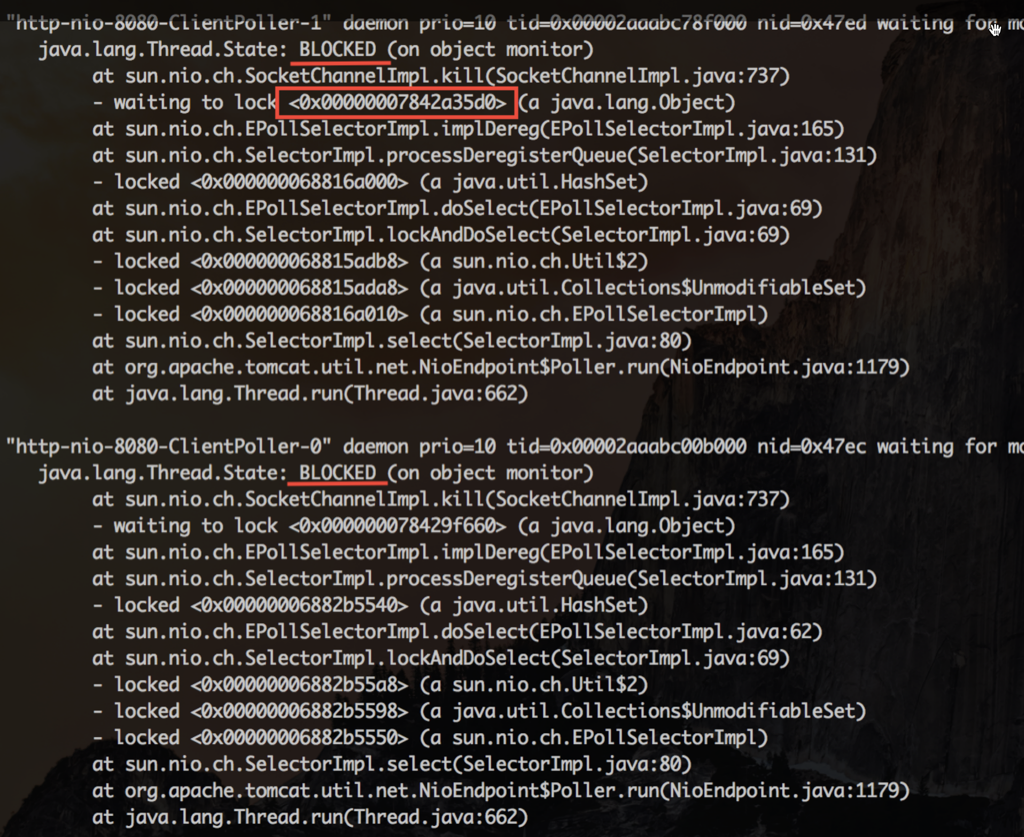
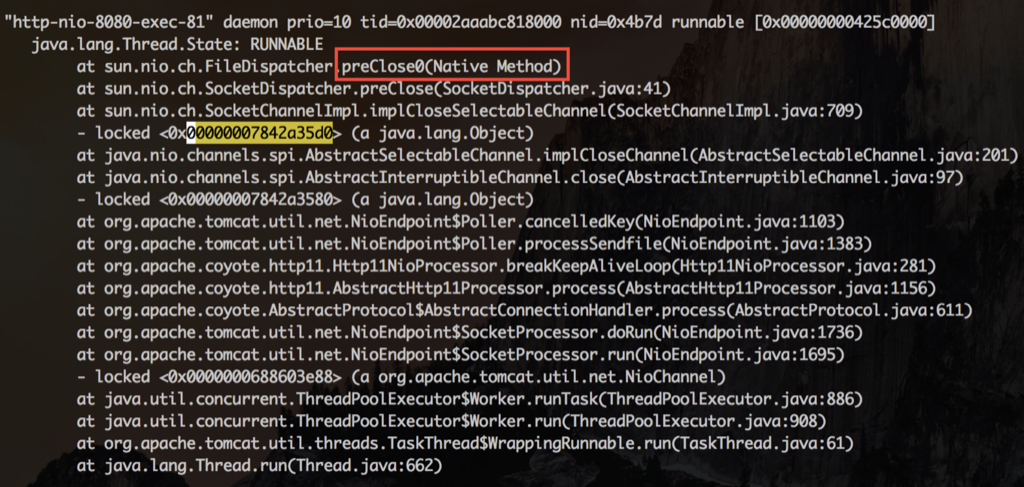
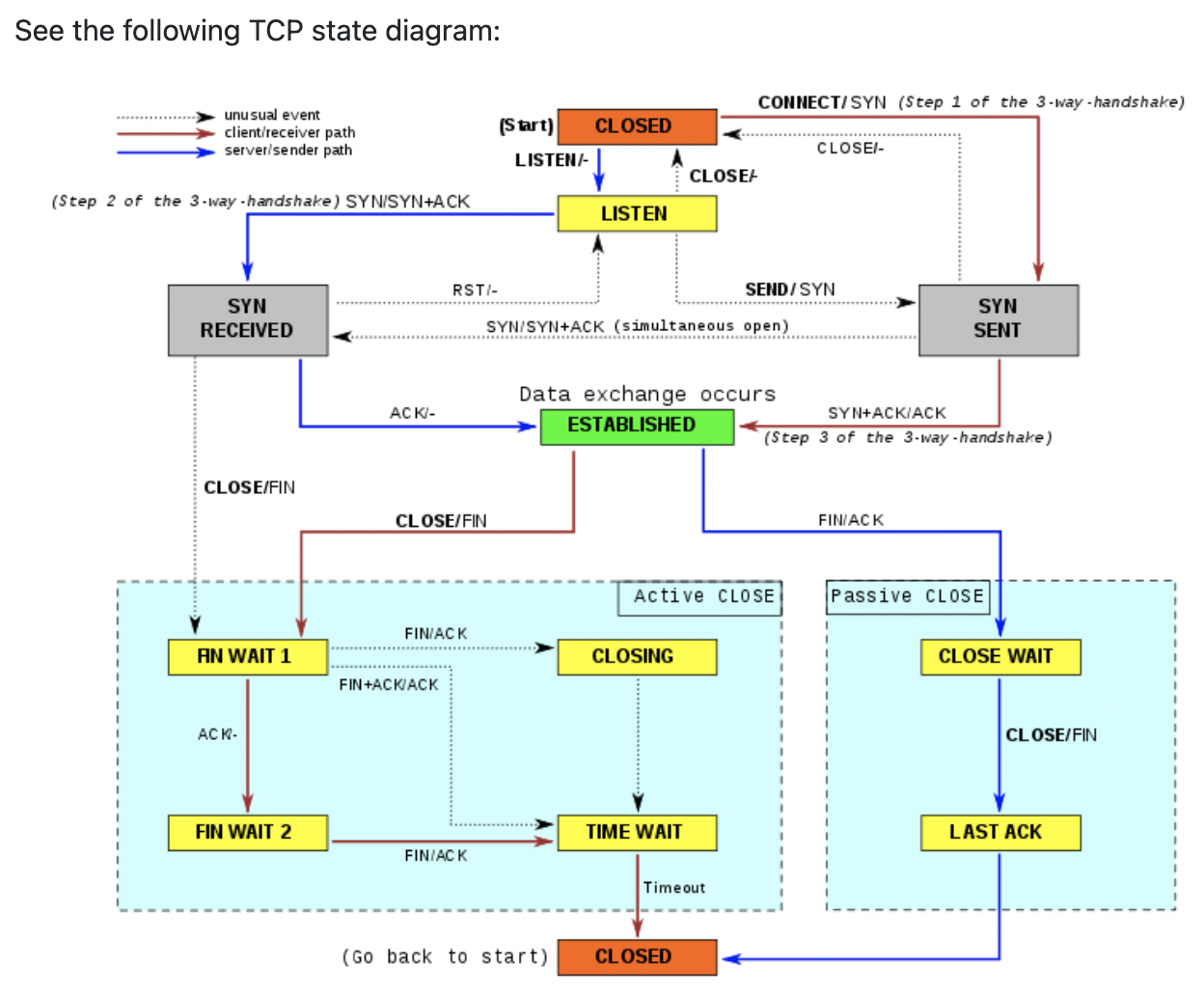
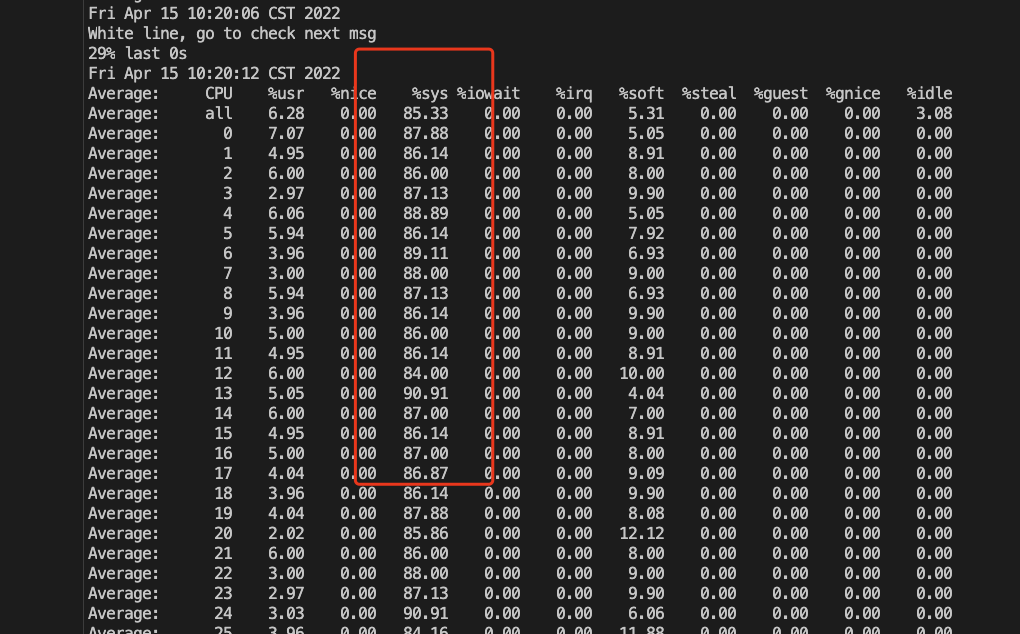
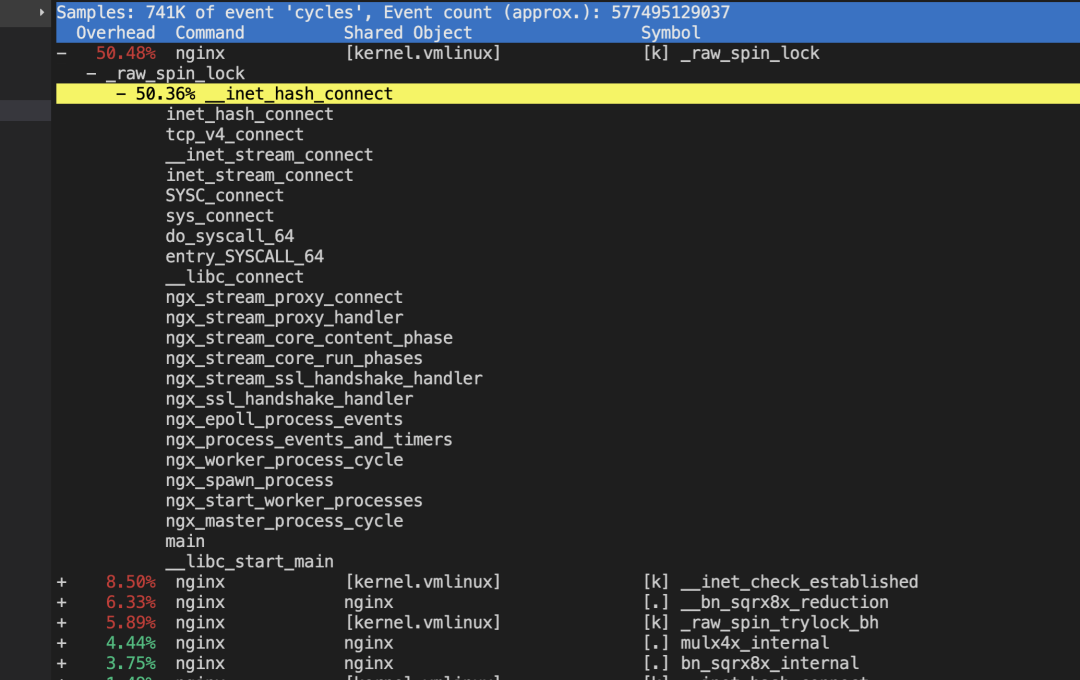
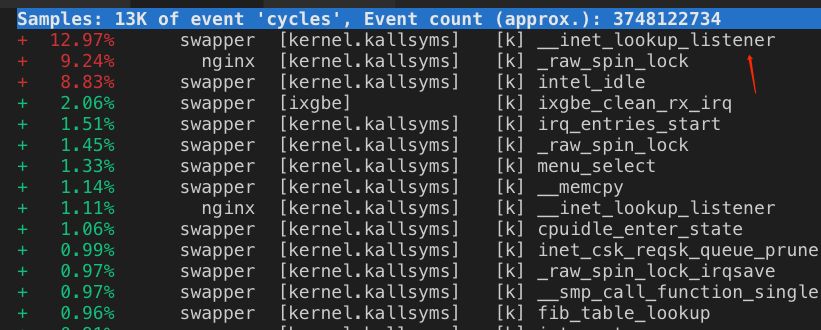
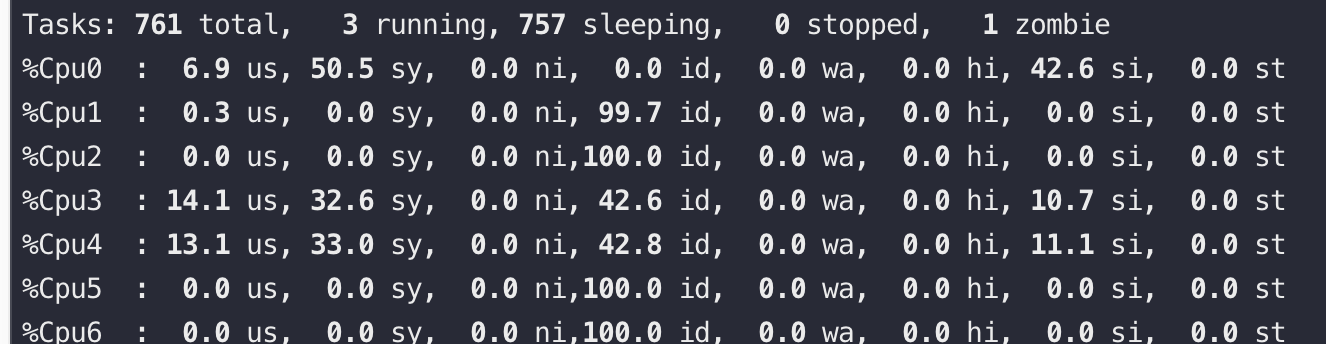
Basically, they are all the same, in the way they all permit the logging of data from different types of systems in a central repository.
But they are three different project, each project trying to improve the previous one with more reliability and functionalities.
The Syslog project was the very first project. It started in 1980. It is the root project to Syslog protocol. At this time Syslog is a very simple protocol. At the beginning it only supports UDP for transport, so that it does not guarantee the delivery of the messages.
Next came syslog-ng in 1998. It extends basic syslog protocol with new features like:
content-based filtering
Logging directly into a database
TCP for transport
TLS encryption
Next came Rsyslog in 2004. It extends syslog protocol with new features like:
# systemd-analyze critical-chain systemd-journald.service The time after the unit is active or started is printed after the "@" character. The time the unit takes to start is printed after the "+" character.
# cat /etc/systemd/journald.conf # This file is part of systemd. # # systemd is free software; you can redistribute it and/or modify it # under the terms of the GNU Lesser General Public License as published by # the Free Software Foundation; either version 2.1 of the License, or # (at your option) any later version. # # Entries in this file show the compile time defaults. # You can change settings by editing this file. # Defaults can be restored by simply deleting this file. # # See journald.conf(5) for details.
-n or –lines= Show the most recent **n** number of log lines
-f or –follow Like a tail operation for viewing live updates
-S, –since=, -U, –until= Search based on a date. “2019-07-04 13:19:17”, “00:00:00”, “yesterday”, “today”, “tomorrow”, “now” are valid formats. For complete time and date specification, see systemd.time(7)
Generally services keep the log files opened while they are running. This mean that they do not care if the log files are renamed/moved or deleted they will continue to write to the open file handled.
When logrotate move the files, the services keep writing to the same file.
Example: syslogd will write to /var/log/cron.log. Then logrotate will rename the file to /var/log/cron.log.1, so syslogd will keep writing to the open file /var/log/cron.log.1.
Sending the HUP signal to syslogd will force him to close existing file handle and open new file handle to the original path /var/log/cron.log which will create a new file.
The use of the HUP signal instead of another one is at the discretion of the program. Some services like php-fpm will listen to the USR1 signal to reopen it’s file handle without terminating itself.
cat /etc/resolv.conf # # macOS Notice # # This file is not consulted for DNS hostname resolution, address # resolution, or the DNS query routing mechanism used by most # processes on this system. # # To view the DNS configuration used by this system, use: # scutil --dns
A scoped DNS query can use only specified network interfaces (e.g. Ethernet or WiFi), while non-scoped can use any available interface.
More verbosely, an application that wants to resolve a name, sends a request (either scoped or non-scoped) to a resolver (usually a DNS client application), if the resolver does not have the answer cached, it sends a DNS query to a particular nameserver (and this goes through one interface, so it is always “scoped”).
In your example resolver #1 “for scoped queries” can use only en0 interface (Ethernet).
$networksetup -listallnetworkservices //列出网卡service, 比如 wifi ,以下是我的 macOS 输出 An asterisk (*) denotes that a network service is disabled. USB 10/100/1000 LAN Apple USB Ethernet Adapter Wi-Fi Bluetooth PAN Thunderbolt Bridge $sudo networksetup -setdnsservers 'Wi-Fi' 202.106.196.115 202.106.0.20 114.114.114.114 //修改nameserver $networksetup -getdnsservers Wi-Fi //查看对应的nameserver, 跟 scutil --dns 类似
如上, 只要是你的nameserver工作正常那么DNS就肯定回复了
删掉所有DNS nameserver:
One note to anyone wanting to remove the DNS, just write “empty” (without the quotes) instead of the DNS: sudo networksetup -setdnsservers <networkservice> empty
$networksetup -listallnetworkservices An asterisk (*) denotes that a network service is disabled. USB 10/100/1000 LAN Apple USB Ethernet Adapter Wi-Fi Bluetooth PAN Thunderbolt Bridge Thunderbolt Bridge 2 #查看网卡配置 $networksetup -getinfo "USB 10/100/1000 LAN" DHCP Configuration IP address: 30.25.25.195 Subnet mask: 255.255.255.128 Router: 30.25.25.254 Client ID: IPv6 IP address: none IPv6 Router: none Ethernet Address: 44:67:52:02:16:d4 $networksetup -listallhardwareports Hardware Port: USB 10/100/1000 LAN Device: en7 Ethernet Address: 44:67:52:02:16:d4
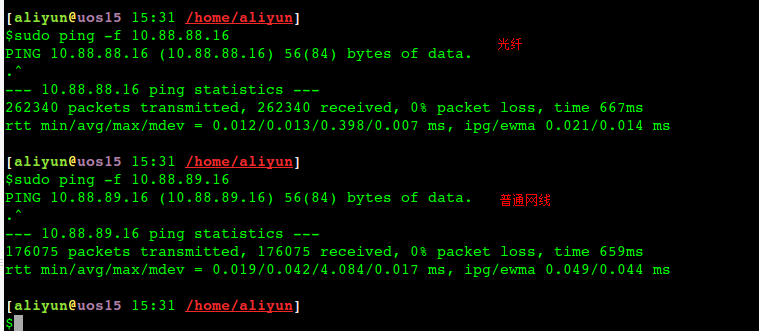
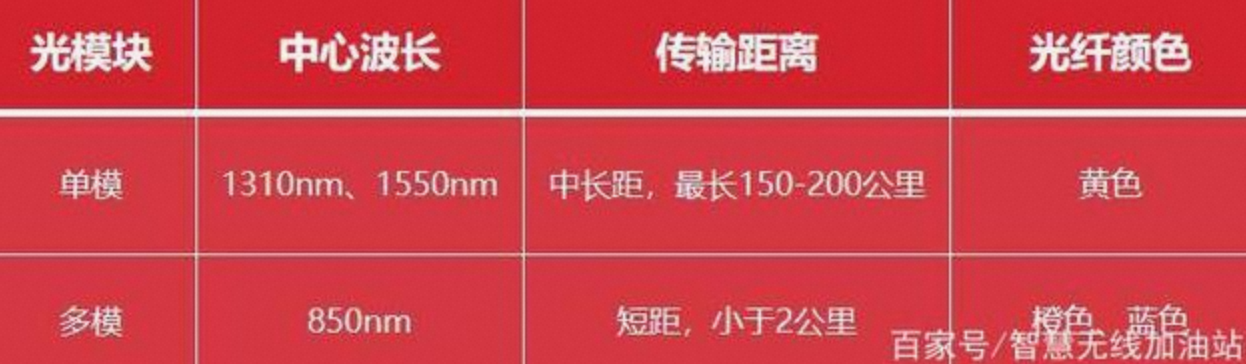
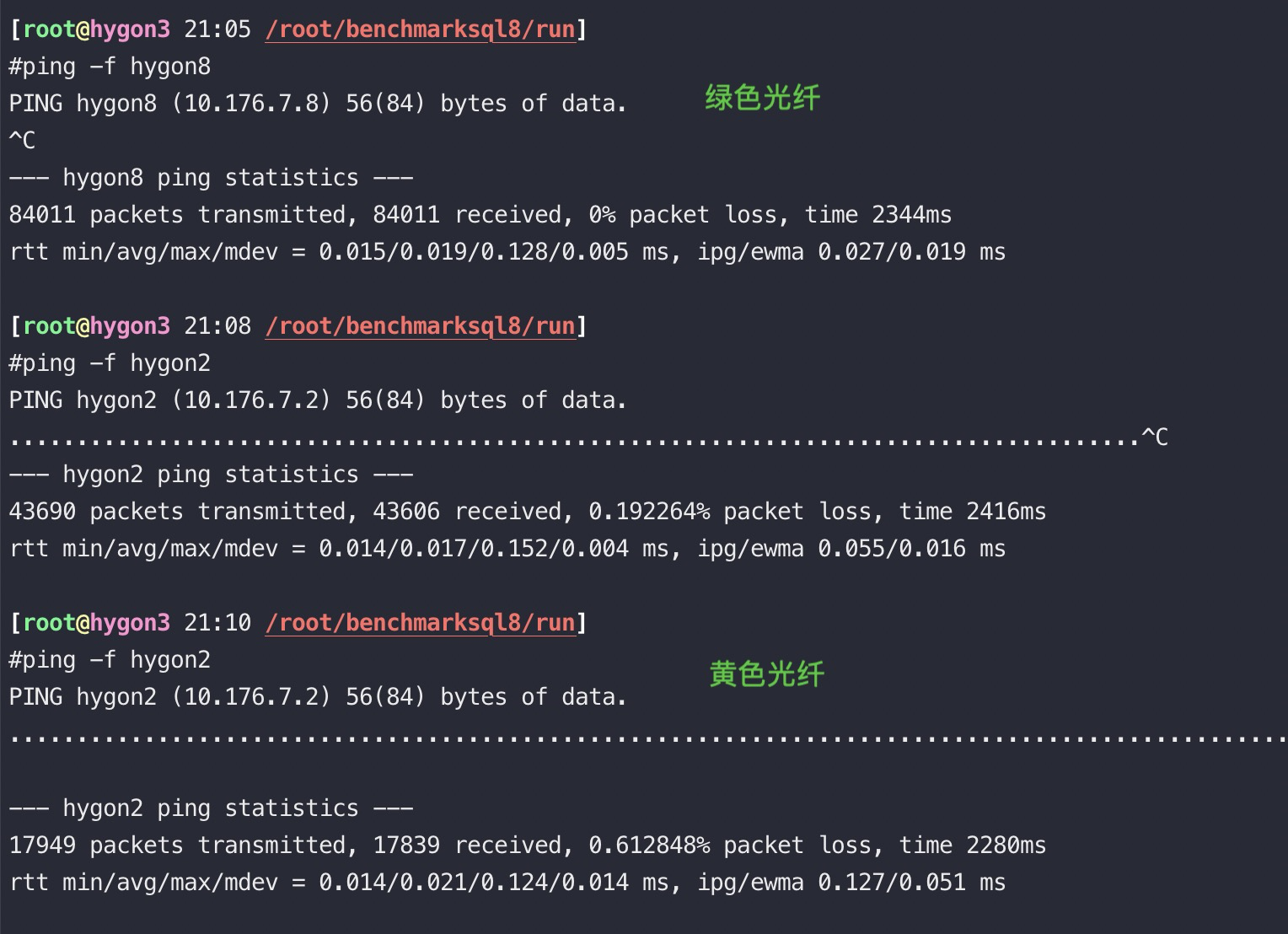
[aliyun@uos15 11:00 /home/aliyun] 以下88都是光口、89都是电口。 $ping -c 10 10.88.88.16 //光纤 PING 10.88.88.16 (10.88.88.16) 56(84) bytes of data. 64 bytes from 10.88.88.16: icmp_seq=1 ttl=64 time=0.058 ms 64 bytes from 10.88.88.16: icmp_seq=2 ttl=64 time=0.049 ms 64 bytes from 10.88.88.16: icmp_seq=3 ttl=64 time=0.053 ms 64 bytes from 10.88.88.16: icmp_seq=4 ttl=64 time=0.040 ms 64 bytes from 10.88.88.16: icmp_seq=5 ttl=64 time=0.053 ms 64 bytes from 10.88.88.16: icmp_seq=6 ttl=64 time=0.043 ms 64 bytes from 10.88.88.16: icmp_seq=7 ttl=64 time=0.038 ms 64 bytes from 10.88.88.16: icmp_seq=8 ttl=64 time=0.050 ms 64 bytes from 10.88.88.16: icmp_seq=9 ttl=64 time=0.043 ms 64 bytes from 10.88.88.16: icmp_seq=10 ttl=64 time=0.064 ms
--- 10.88.88.16 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 159ms rtt min/avg/max/mdev = 0.038/0.049/0.064/0.008 ms
[aliyun@uos15 11:01 /home/aliyun] $ping -c 10 10.88.89.16 //电口 PING 10.88.89.16 (10.88.89.16) 56(84) bytes of data. 64 bytes from 10.88.89.16: icmp_seq=1 ttl=64 time=0.087 ms 64 bytes from 10.88.89.16: icmp_seq=2 ttl=64 time=0.053 ms 64 bytes from 10.88.89.16: icmp_seq=3 ttl=64 time=0.095 ms 64 bytes from 10.88.89.16: icmp_seq=4 ttl=64 time=0.391 ms 64 bytes from 10.88.89.16: icmp_seq=5 ttl=64 time=0.051 ms 64 bytes from 10.88.89.16: icmp_seq=6 ttl=64 time=0.343 ms 64 bytes from 10.88.89.16: icmp_seq=7 ttl=64 time=0.045 ms 64 bytes from 10.88.89.16: icmp_seq=8 ttl=64 time=0.341 ms 64 bytes from 10.88.89.16: icmp_seq=9 ttl=64 time=0.054 ms 64 bytes from 10.88.89.16: icmp_seq=10 ttl=64 time=0.066 ms
--- 10.88.89.16 ping statistics --- 10 packets transmitted, 10 received, 0% packet loss, time 149ms rtt min/avg/max/mdev = 0.045/0.152/0.391/0.136 ms
Mode 4 (802.3ad): This mode creates aggregation groups that share the same speed and duplex settings, and it requires a switch that supports an IEEE 802.3ad dynamic link. Mode 4 uses all interfaces in the active aggregation group. For example, you can aggregate three 1 GB per second (GBPS) ports into a 3 GBPS trunk port. This is equivalent to having one interface with 3 GBPS speed. It provides fault tolerance and load balancing.
#ethtool bond0 Settings for bond0: Supported ports: [ ] Supported link modes: Not reported Supported pause frame use: No Supports auto-negotiation: No Advertised link modes: Not reported Advertised pause frame use: No Advertised auto-negotiation: No Speed: 20000Mb/s Duplex: Full Port: Other PHYAD: 0 Transceiver: internal Auto-negotiation: off Link detected: yes
CPU 进入节能模式之前,设定可空闲的 CPU 数量。如果有大于阀值数量的 CPU 是大于一个标准的偏差,该差值低于平均软中断工作负载,以及没有 CPU 是大于一个标准偏差,且该偏差高出平均,并有多于一个的 irq 分配给它们,一个 CPU 将处于节能模式。在节能模式中,CPU 不是 irqbalance 的一部分,所以它在有必要时才会被唤醒。
cat /etc/sysconfig/irqbalance # IRQBALANCE_BANNED_CPUS # 64 bit bitmask which allows you to indicate which cpu's should # be skipped when reblancing irqs. Cpu numbers which have their # corresponding bits set to one in this mask will not have any # irq's assigned to them on rebalance #绑定软中断到8-15core, 每位表示4core #IRQBALANCE_BANNED_CPUS=ffffffff,ffff00ff #绑定软中断到8-15core和第65core IRQBALANCE_BANNED_CPUS=ffffffff,fffffdff,ffffffff,ffff00ff
#!/bin/bash # This is the default setting of networking multiqueue and irq affinity # 1. enable multiqueue if available # 2. irq affinity optimization # 3. stop irqbalance service # set and check multiqueue
function set_check_multiqueue() { eth=$1 log_file=$2 queue_num=$(ethtool -l $eth | grep -ia5 'pre-set' | grep -i combined | awk {'print $2'}) if [ $queue_num -gt 1 ]; then # set multiqueue ethtool -L $eth combined $queue_num # check multiqueue setting cur_q_num=$(ethtool -l $eth | grep -iA5 current | grep -i combined | awk {'print $2'}) if [ "X$queue_num" != "X$cur_q_num" ]; then echo "Failed to set $eth queue size to $queue_num" >> $log_file echo "after setting, pre-set queue num: $queue_num , current: $cur_q_num" >> $log_file return 1 else echo "OK. set $eth queue size to $queue_num" >> $log_file fi else echo "only support $queue_num queue; no need to enable multiqueue on $eth" >> $log_file fi } #set irq affinity function set_irq_smpaffinity() { log_file=$1 node_dir=/sys/devices/system/node for i in $(ls -d $node_dir/node*); do i=${i/*node/} done echo "max node :$i" >> $log_file node_cpumax=$(cat /sys/devices/system/node/node${i}/cpulist |awk -F- '{print $NF}') irqs=($(cat /proc/interrupts |grep virtio |grep put | awk -F: '{print $1}')) core=0 for irq in ${irqs[@]};do VEC=$core if [ $VEC -ge 32 ];then let "IDX = $VEC / 32" MASK_FILL="" MASK_ZERO="00000000" for ((i=1; i<=$IDX;i++)) do MASK_FILL="${MASK_FILL},${MASK_ZERO}" done let "VEC -= 32 * $IDX" MASK_TMP=$((1<<$VEC)) MASK=$(printf "%X%s" $MASK_TMP $MASK_FILL) else MASK_TMP=$((1<<$VEC)) MASK=$(printf "%X" $MASK_TMP) fi echo $MASK > /proc/irq/$irq/smp_affinity echo "mask:$MASK, irq:$irq" >> $log_file core=$(((core+1)%(node_cpumax+1))) done } # stop irqbalance service function stop_irqblance() { log_file=$1 ret=0 if [ "X" != "X$(ps -ef | grep irqbalance | grep -v grep)" ]; then if which systemctl;then systemctl stop irqbalance else service irqbalance stop fi if [ $? -ne 0 ]; then echo "Failed to stop irqbalance" >> $log_file ret=1 fi else echo "OK. irqbalance stoped." >> $log_file fi return $ret } # main logic function main() { ecs_network_log=/var/log/ecs_network_optimization.log ret_value=0 echo "running $0" > $ecs_network_log echo "======== ECS network setting starts $(date +'%Y-%m-%d %H:%M:%S') ========" >> $ecs_network_log # we assume your NIC interface(s) is/are like eth* eth_dirs=$(ls -d /sys/class/net/eth*) if [ "X$eth_dirs" = "X" ]; then echo "ERROR! can not find any ethX in /sys/class/net/ dir." >> $ecs_network_log ret_value=1 fi for i in $eth_dirs do cur_eth=$(basename $i) echo "optimize network performance: current device $cur_eth" >> $ecs_network_log # only optimize virtio_net device driver=$(basename $(readlink $i/device/driver)) if ! echo $driver | grep -q virtio; then echo "ignore device $cur_eth with driver $driver" >> $ecs_network_log continue fi echo "set and check multiqueue on $cur_eth" >> $ecs_network_log set_check_multiqueue $cur_eth $ecs_network_log if [ $? -ne 0 ]; then echo "Failed to set multiqueue on $cur_eth" >> $ecs_network_log ret_value=1 fi done stop_irqblance $ecs_network_log set_irq_smpaffinity $ecs_network_log echo "======== ECS network setting END $(date +'%Y-%m-%d %H:%M:%S') ========" >> $ecs_network_log return $ret_value } # program starts here main exit $?
查询的rps绑定情况的脚本 get_rps.sh
1 2 3 4 5 6
#!/bin/bash # 获取当前rps情况 for i in $(ls /sys/class/net/eth0/queues/rx-*/rps_cpus); do echo $i cat $i done
RSS 和 RPS
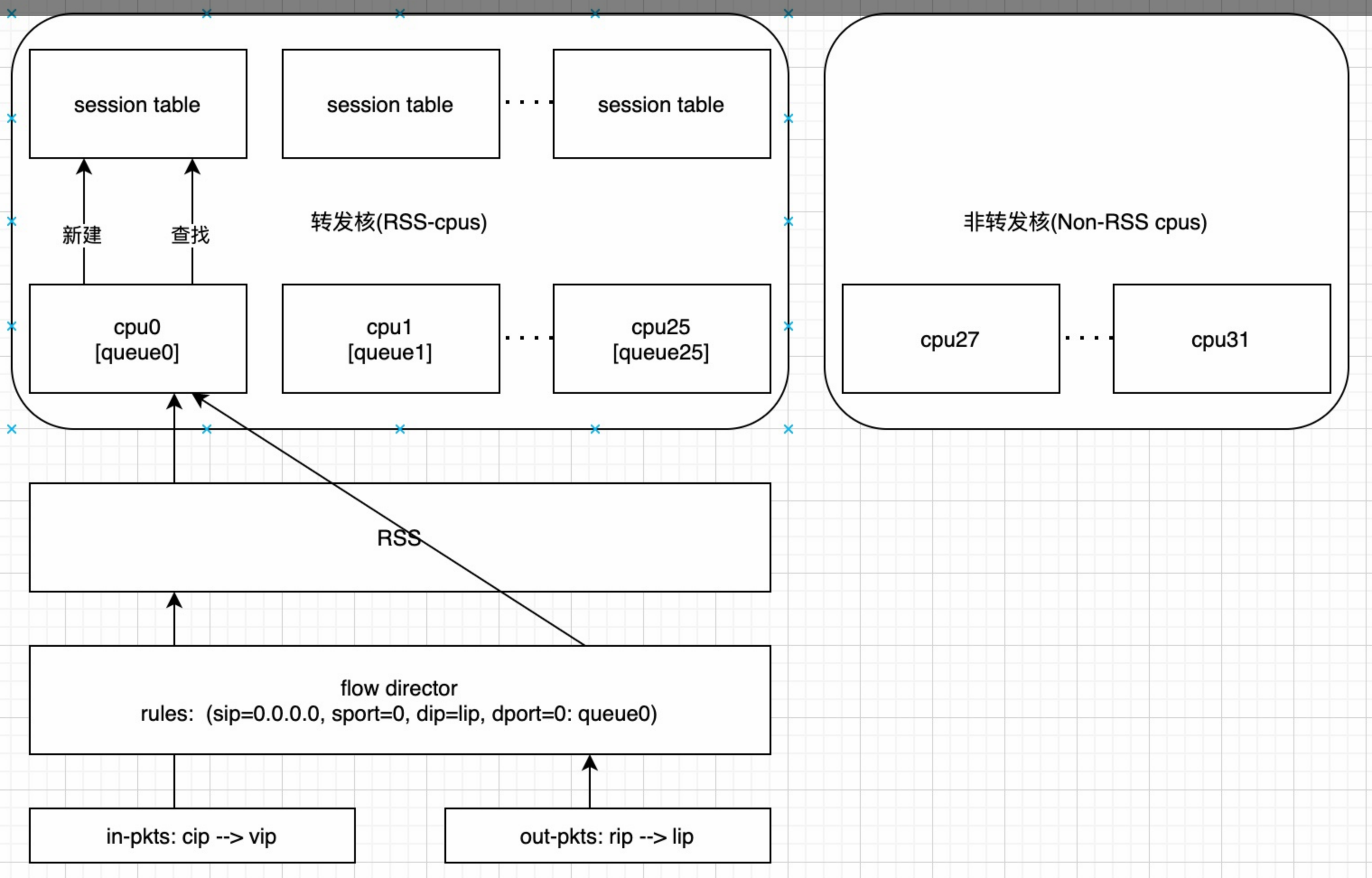
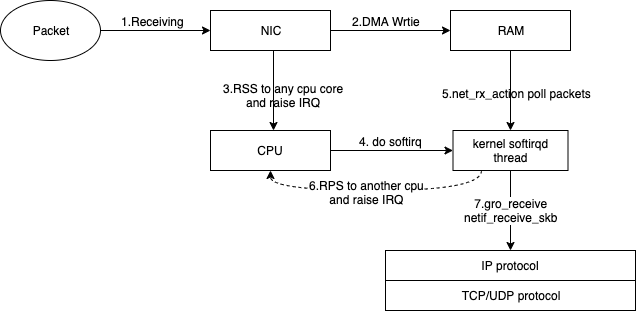
RSS:即receive side steering,利用网卡的多队列特性,将每个核分别跟网卡的一个首发队列绑定,以达到网卡硬中断和软中断均衡的负载在各个CPU上。他要求网卡必须要支持多队列特性。
default dev bond0 ---默认路由,后面的可以省略 10.0.0.0/8 via 11.158.239.247 dev bond0 11.0.0.0/8 via 11.158.239.247 dev bond0 30.0.0.0/8 via 11.158.239.247 dev bond0 172.16.0.0/12 via 11.158.239.247 dev bond0 192.168.0.0/16 via 11.158.239.247 dev bond0 100.64.0.0/10 via 11.158.239.247 dev bond0 33.0.0.0/8 via 11.158.239.247 dev bond0
或者用sed在文件第一行添加
1 2
sed -i '/default /d' /etc/sysconfig/network-scripts/route-bond0 //先删除默认路由(如果有) sed -i '1 i\default dev bond0' /etc/sysconfig/network-scripts/route-bond0 //添加
Centos 7的话需要在 /etc/sysconfig/network 中添加创建默认路由的命令
1 2 3
# cat /etc/sysconfig/network # Created by anaconda ip route add default dev eth0
kernel: ixgbe 0000:3b:00.1 eth1: renamed from enp59s0f1 kernel: i40e 0000:88:00.0 eth7: renamed from enp136s0
同时network service 会启动,进而遍历etc/sysconfig/network-scripts下面的脚本,我们配置的bond0, 默认路由,通常会在这个阶段运行,创建
1 2 3 4 5 6 7 8 9 10
kernel: bond0: Enslaving eth0 as a backup interface with a down link kernel: ixgbe 0000:3b:00.0 eth0: detected SFP+: 5 kernel: power_meter ACPI000D:00: Found ACPI power meter. kernel: power_meter ACPI000D:00: Ignoring unsafe software power cap! kernel: ixgbe 0000:3b:00.1: registered PHC device on eth1 kernel: ixgbe 0000:3b:00.0 eth0: NIC Link is Up 10 Gbps, Flow Control: RX/TX kernel: bond0: Enslaving eth1 as a backup interface with a down link kernel: bond0: Warning: No 802.3ad response from the link partner for any adapters in the bond kernel: bond0: link status definitely up for interface eth0, 10000 Mbps full duplex kernel: bond0: first active interface up!
A rule in /usr/lib/udev/rules.d/60-net.rules instructs the udev helper utility, /lib/udev/rename_device, to look into all /etc/sysconfig/network-scripts/ifcfg-*suffix* files. If it finds an ifcfg file with a HWADDR entry matching the MAC address of an interface it renames the interface to the name given in the ifcfg file by the DEVICE directive.(根据提前定义好的ifcfg-网卡名来命名网卡–依赖mac匹配,如果网卡的ifconfig文件中未加入HWADDR,则rename脚本并不会根据配置文件去重命名网卡)
A rule in /usr/lib/udev/rules.d/71-biosdevname.rules instructs biosdevname to rename the interface according to its naming policy, provided that it was not renamed in a previous step, biosdevname is installed, and biosdevname=0 was not given as a kernel command on the boot command line.
A rule in /lib/udev/rules.d/75-net-description.rules instructs udev to fill in the internal udev device property values ID_NET_NAME_ONBOARD, ID_NET_NAME_SLOT, ID_NET_NAME_PATH, ID_NET_NAME_MAC by examining the network interface device. Note, that some device properties might be undefined.
A rule in /usr/lib/udev/rules.d/80-net-name-slot.rules instructs udev to rename the interface, provided that it was not renamed in step 1 or 2, and the kernel parameter net.ifnames=0 was not given, according to the following priority: ID_NET_NAME_ONBOARD, ID_NET_NAME_SLOT, ID_NET_NAME_PATH. It falls through to the next in the list, if one is unset. If none of these are set, then the interface will not be renamed.
The following is an excerpt from Chapter 11 of the RHEL 7 “Networking Guide”:
Scheme 1: Names incorporating Firmware or BIOS provided index numbers for on-board devices (example: eno1), are applied if that information from the firmware or BIOS is applicable and available, else falling back to scheme 2.
Scheme 2: Names incorporating Firmware or BIOS provided PCI Express hotplug slot index numbers (example: ens1) are applied if that information from the firmware or BIOS is applicable and available, else falling back to scheme 3.
Scheme 3: Names incorporating physical location of the connector of the hardware (example: enp2s0), are applied if applicable, else falling directly back to scheme 5 in all other cases.
Scheme 4: Names incorporating interface’s MAC address (example: enx78e7d1ea46da), is not used by default, but is available if the user chooses.
Scheme 5: The traditional unpredictable kernel naming scheme, is used if all other methods fail (example: eth0).
o<index> on-board device index number s<slot> hotplug slot index number x<MAC> MAC address p<bus>s<slot> PCI geographical location p<bus>s<slot> USB port number chain
#include <stdio.h> #include <io.h> ... if (isatty(fileno(stdout))) printf( "stdout is a terminal\n" ); // 输出制表符 else printf( "stdout is a file or a pipe\n"); // 不输出制表符
Linux 4.2后的内核增加了IP_BIND_ADDRESS_NO_PORT 这个socket option来解决这个问题,将src port的选择延后到connect的时候
IP_BIND_ADDRESS_NO_PORT (since Linux 4.2) Inform the kernel to not reserve an ephemeral port when using bind(2) with a port number of 0. The port will later be automatically chosen at connect(2) time, in a way that allows sharing a source port as long as the 4-tuple is unique.
SO_REUSEADDR Indicates that the rules used in validating addresses supplied in a bind(2) call should allow reuse of local addresses. For AF_INET sockets this means that a socket may bind, except when there is an active listening socket bound to the address. When the listening socket is bound to INADDR_ANY with a specific port then it is not possible to bind to this port for any local address. Argument is an integer boolean flag.
SO_REUSEADDR 还可以重用TIME_WAIT状态的port, 在程序崩溃后之前的TCP连接会进入到TIME_WAIT状态,需要一段时间才能释放,如果立即重启就会抛出Address Already in use的错误导致启动失败。这时候可以通过在调用bind函数之前设置SO_REUSEADDR来解决。
What exactly does SO_REUSEADDR do?
This socket option tells the kernel that even if this port is busy (in the TIME_WAIT state), go ahead and reuse it anyway. If it is busy, but with another state, you will still get an address already in use error. It is useful if your server has been shut down, and then restarted right away while sockets are still active on its port. You should be aware that if any unexpected data comes in, it may confuse your server, but while this is possible, it is not likely.
It has been pointed out that “A socket is a 5 tuple (proto, local addr, local port, remote addr, remote port). SO_REUSEADDR just says that you can reuse local addresses. The 5 tuple still must be unique!” This is true, and this is why it is very unlikely that unexpected data will ever be seen by your server. The danger is that such a 5 tuple is still floating around on the net, and while it is bouncing around, a new connection from the same client, on the same system, happens to get the same remote port.
By setting SO_REUSEADDR user informs the kernel of an intention to share the bound port with anyone else, but only if it doesn’t cause a conflict on the protocol layer. There are at least three situations when this flag is useful:
Normally after binding to a port and stopping a server it’s neccesary to wait for a socket to time out before another server can bind to the same port. With SO_REUSEADDR set it’s possible to rebind immediately, even if the socket is in a TIME_WAIT state.
When one server binds to INADDR_ANY, say 0.0.0.0:1234, it’s impossible to have another server binding to a specific address like 192.168.1.21:1234. With SO_REUSEADDR flag this behaviour is allowed.
When using the bind before connect trick only a single connection can use a single outgoing source port. With this flag, it’s possible for many connections to reuse the same source port, given that they connect to different destination addresses.
SO_REUSEPORT is also useful for eliminating the try-10-times-to-bind hack in ftpd’s data connection setup routine. Without SO_REUSEPORT, only one ftpd thread can bind to TCP (lhost, lport, INADDR_ANY, 0) in preparation for connecting back to the client. Under conditions of heavy load, there are more threads colliding here than the try-10-times hack can accomodate. With SO_REUSEPORT, things work nicely and the hack becomes unnecessary.
(a) on Linux SO_REUSEPORT is meant to be used purely for load balancing multiple incoming UDP packets or incoming TCP connection requests across multiple sockets belonging to the same app. ie. it’s a work around for machines with a lot of cpus, handling heavy load, where a single listening socket becomes a bottleneck because of cross-thread contention on the in-kernel socket lock (and state).
(b) set IP_BIND_ADDRESS_NO_PORT socket option for tcp sockets before binding to a specific source ip with port 0 if you’re going to use the socket for connect() rather then listen() this allows the kernel to delay allocating the source port until connect() time at which point it is much cheaper
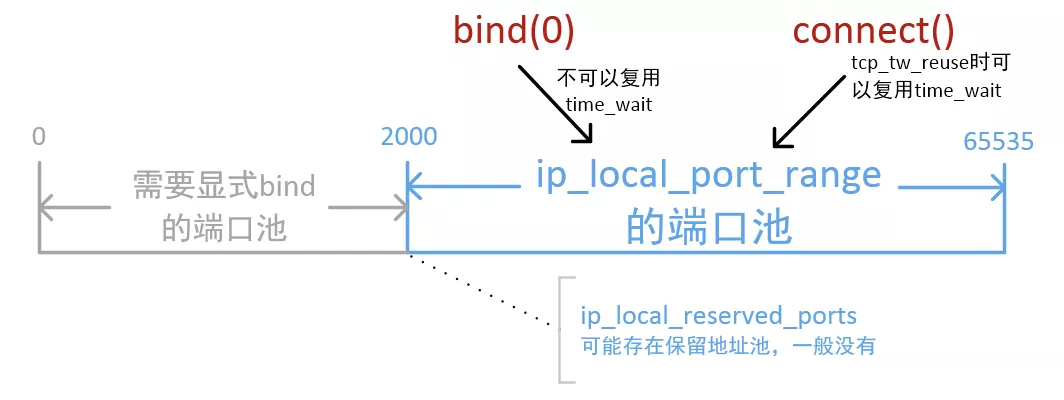
Ephemeral Port Range就是我们前面所说的Port Range(/proc/sys/net/ipv4/ip_local_port_range)
A TCP/IPv4 connection consists of two endpoints, and each endpoint consists of an IP address and a port number. Therefore, when a client user connects to a server computer, an established connection can be thought of as the 4-tuple of (server IP, server port, client IP, client port).
Usually three of the four are readily known – client machine uses its own IP address and when connecting to a remote service, the server machine’s IP address and service port number are required.
What is not immediately evident is that when a connection is established that the client side of the connection uses a port number. Unless a client program explicitly requests a specific port number, the port number used is an ephemeral port number.
Ephemeral ports are temporary ports assigned by a machine’s IP stack, and are assigned from a designated range of ports for this purpose. When the connection terminates, the ephemeral port is available for reuse, although most IP stacks won’t reuse that port number until the entire pool of ephemeral ports have been used.
So, if the client program reconnects, it will be assigned a different ephemeral port number for its side of the new connection.
#date; ./client && echo "+++++++" ; ./client && sleep 0.1 ; echo "-------" && ./client && sleep 10; date; ./client && echo "+++++++" ; ./client && sleep 0.1 && echo "******"; ./client; Fri Nov 27 10:52:52 CST 2020 local port: 17448 local port: 17449 local port: 17451 local port: 17452 local port: 17453 +++++++ local port: 17455 local port: 17456 local port: 17457 local port: 17458 local port: 17460 ------- local port: 17475 local port: 17476 local port: 17477 local port: 17478 local port: 17479 Fri Nov 27 10:53:02 CST 2020 local port: 17997 local port: 17998 local port: 17999 local port: 18000 local port: 18001 +++++++ local port: 18002 local port: 18003 local port: 18004 local port: 18005 local port: 18006 ****** local port: 18010 local port: 18011 local port: 18012 local port: 18013 local port: 18014
$date; ./client && echo "+++++++" ; ./client && sleep 0.1 ; echo "-------" && ./client && sleep 10; date; ./client && echo "+++++++" ; ./client && sleep 0.1 && echo "******"; ./client; Fri Nov 27 14:10:47 CST 2020 local port: 7890 local port: 7892 local port: 7894 local port: 7896 local port: 7898 +++++++ local port: 7900 local port: 7902 local port: 7904 local port: 7906 local port: 7908 ------- local port: 7910 local port: 7912 local port: 7914 local port: 7916 local port: 7918 Fri Nov 27 14:10:57 CST 2020 local port: 7966 local port: 7968 local port: 7970 local port: 7972 local port: 7974 +++++++ local port: 7976 local port: 7978 local port: 7980 local port: 7982 local port: 7984 ****** local port: 7988 local port: 7990 local port: 7992 local port: 7994 local port: 7996
$./client local port: 1033 local port: 1025 local port: 1027 local port: 1029 local port: 1031 local port: 1033 local port: 1025 local port: 1027 local port: 1029 local port: 1031 local port: 1033 local port: 1025
tcp_max_tw_buckets - INTEGER Maximal number of timewait sockets held by system simultaneously.If this number is exceeded time-wait socket is immediately destroyed and warning is printed. This limit exists only to prevent simple DoS attacks, you must not lower the limit artificially, but rather increase it (probably, after increasing installed memory), if network conditions require more than default value.
This option specifies how the close function operates for a connection-oriented protocol (for TCP, but not for UDP). By default, close returns immediately, but ==if there is any data still remaining in the socket send buffer, the system will try to deliver the data to the peer==.
A进程选择某个端口当local port 来connect,并设置了 reuseaddr opt(表示其它进程还能继续用这个端口),这时B进程选了这个端口,并且bind了,B进程用完后把这个bind的端口释放了,但是如果 A 进程一直不释放这个端口对应的连接,那么这个端口会一直在内核中记录被bind用掉了(能bind的端口 是65535个,四元组不重复的连接你理解可以无限多),这样的端口越来越多后,剩下可供 A 进程发起连接的本地随机端口就越来越少了(也就是本来A进程选择端口是按四元组的,但因为前面所说的原因,导致不按四元组了,只按端口本身这个一元组来排重),这时会造成新建连接的时候这个四元组高概率重复,一般这个时候对端大概率还在 time_wait 状态,会忽略掉握手 syn 包并回复 ack ,进而造成建连接卡顿的现象;超频繁的端口复用在LVS 场景下会产生问题,导致建连异常;或者syn包被 RST 触发1秒钟重传 syn
#netstat -anpo |grep 18181 0.0.0.0:18181 0.0.0.0:* LISTEN 2732449/nc off (0.00/0/0) 172.17.151.5:18181 19.12.59.7:56166 ESTABLISHED 2732449/nc off (0.00/0/0) (stream2) 172.17.151.5:18181 110.242.68.66:80 ESTABLISHED 2732445/python keepalive (4.96/0/0)(stream1) 172.17.151.5:18181 10.143.33.49:123 ESTABLISHED 624/chronyd off (0.00/0/0)