#mkisofs -r -o docker_ansible.iso ./yum/ I: -input-charset not specified, using utf-8 (detected in locale settings) Using PYTHO000.RPM;1 for /python-httplib2-0.7.7-3.el7.noarch.rpm (python-httplib2-0.9.1-3.el7.noarch.rpm) Using MARIA006.RPM;1 for /mariadb-5.5.56-2.el7.x86_64.rpm (mariadb-libs-5.5.56-2.el7.x86_64.rpm) Using LIBTO001.RPM;1 for /libtomcrypt-1.17-25.el7.x86_64.rpm (libtomcrypt-1.17-26.el7.x86_64.rpm) 6.11% done, estimate finish Sun Jul 12 14:26:47 2020 97.60% done, estimate finish Sun Jul 12 14:26:48 2020 Total translation table size: 0 Total rockridge attributes bytes: 14838 Total directory bytes: 2048 Path table size(bytes): 26 Max brk space used 21000 81981 extents written (160 MB)
将 生成的 iso挂载到目标机器上
1 2 3
# mkdir /mnt/iso # mount ./docker_ansible.iso /mnt/iso mount: /dev/loop0 is write-protected, mounting read-only
set mirror_path $base_path/mirror set skel_path $base_path/skel set var_path $base_path/var set cleanscript $var_path/clean.sh set defaultarch amd64 #set postmirror_script $var_path/postmirror.sh set run_postmirror 0 set nthreads 20 set _tilde 0 # ############# end config ##############
#从哪里镜像仓库 deb http://yum.tbsite.net/mirrors/debian/ buster main non-free contrib #deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main
#deb http://ftp.us.debian.org/debian unstable main contrib non-free #deb-src http://ftp.us.debian.org/debian unstable main contrib non-free
# mirror additional architectures #deb-alpha http://ftp.us.debian.org/debian unstable main contrib non-free #deb-amd64 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-armel http://ftp.us.debian.org/debian unstable main contrib non-free #deb-hppa http://ftp.us.debian.org/debian unstable main contrib non-free #deb-i386 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-ia64 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-m68k http://ftp.us.debian.org/debian unstable main contrib non-free #deb-mips http://ftp.us.debian.org/debian unstable main contrib non-free #deb-mipsel http://ftp.us.debian.org/debian unstable main contrib non-free #deb-powerpc http://ftp.us.debian.org/debian unstable main contrib non-free #deb-s390 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-sparc http://ftp.us.debian.org/debian unstable main contrib non-free
#mkisofs -r -o docker_ansible.iso ./yum/ I: -input-charset not specified, using utf-8 (detected in locale settings) Using PYTHO000.RPM;1 for /python-httplib2-0.7.7-3.el7.noarch.rpm (python-httplib2-0.9.1-3.el7.noarch.rpm) Using MARIA006.RPM;1 for /mariadb-5.5.56-2.el7.x86_64.rpm (mariadb-libs-5.5.56-2.el7.x86_64.rpm) Using LIBTO001.RPM;1 for /libtomcrypt-1.17-25.el7.x86_64.rpm (libtomcrypt-1.17-26.el7.x86_64.rpm) 6.11% done, estimate finish Sun Jul 12 14:26:47 2020 97.60% done, estimate finish Sun Jul 12 14:26:48 2020 Total translation table size: 0 Total rockridge attributes bytes: 14838 Total directory bytes: 2048 Path table size(bytes): 26 Max brk space used 21000 81981 extents written (160 MB)
将 生成的 iso挂载到目标机器上
1 2 3
# mkdir /mnt/iso # mount ./docker_ansible.iso /mnt/iso mount: /dev/loop0 is write-protected, mounting read-only
set mirror_path $base_path/mirror set skel_path $base_path/skel set var_path $base_path/var set cleanscript $var_path/clean.sh set defaultarch amd64 #set postmirror_script $var_path/postmirror.sh set run_postmirror 0 set nthreads 20 set _tilde 0 # ############# end config ##############
#从哪里镜像仓库 deb http://yum.tbsite.net/mirrors/debian/ buster main non-free contrib #deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main
#deb http://ftp.us.debian.org/debian unstable main contrib non-free #deb-src http://ftp.us.debian.org/debian unstable main contrib non-free
# mirror additional architectures #deb-alpha http://ftp.us.debian.org/debian unstable main contrib non-free #deb-amd64 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-armel http://ftp.us.debian.org/debian unstable main contrib non-free #deb-hppa http://ftp.us.debian.org/debian unstable main contrib non-free #deb-i386 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-ia64 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-m68k http://ftp.us.debian.org/debian unstable main contrib non-free #deb-mips http://ftp.us.debian.org/debian unstable main contrib non-free #deb-mipsel http://ftp.us.debian.org/debian unstable main contrib non-free #deb-powerpc http://ftp.us.debian.org/debian unstable main contrib non-free #deb-s390 http://ftp.us.debian.org/debian unstable main contrib non-free #deb-sparc http://ftp.us.debian.org/debian unstable main contrib non-free
LoadBalancer:和nodePort类似,不过除了使用一个Cluster IP和nodePort之外,还会向所使用的公有云申请一个负载均衡器,实现从集群外通过LB访问服务。在公有云提供的 Kubernetes 服务里,都使用了一个叫作 CloudProvider 的转接层,来跟公有云本身的 API 进行对接。所以,在上述 LoadBalancer 类型的 Service 被提交后,Kubernetes 就会调用 CloudProvider 在公有云上为你创建一个负载均衡服务,并且把被代理的 Pod 的 IP 地址配置给负载均衡服务做后端。
ExternalName:是 Service 的特例。此模式主要面向运行在集群外部的服务,通过它可以将外部服务映射进k8s集群,且具备k8s内服务的一些特征(如具备namespace等属性),来为集群内部提供服务。此模式要求kube-dns的版本为1.7或以上。这种模式和前三种模式(除headless service)最大的不同是重定向依赖的是dns层次,而不是通过kube-proxy。
# ip addr ... 5: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default link/ether de:29:17:2a:8d:79 brd ff:ff:ff:ff:ff:ff inet 10.68.70.130/32 scope global kube-ipvs0 valid_lft forever preferred_lft forever
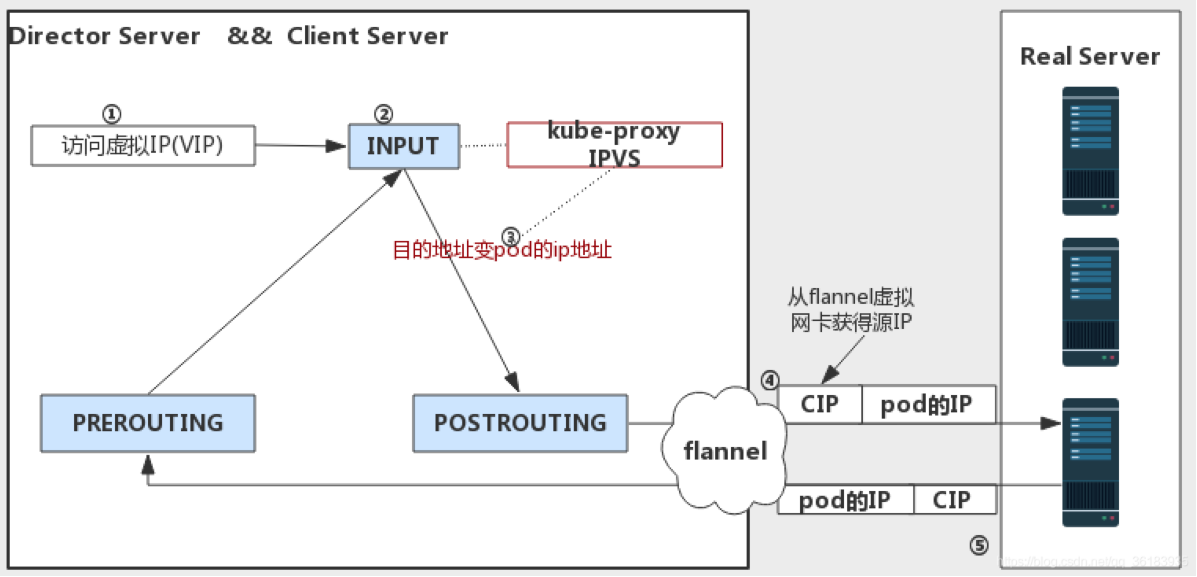
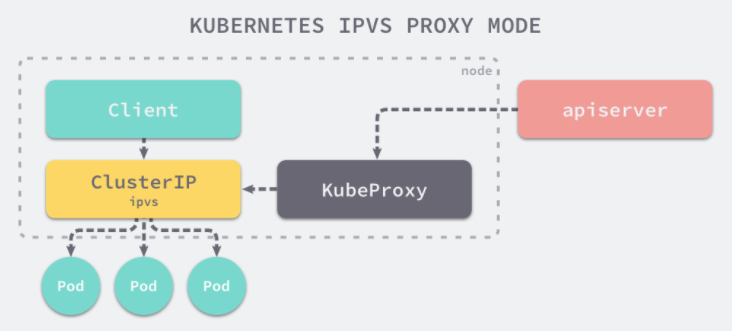
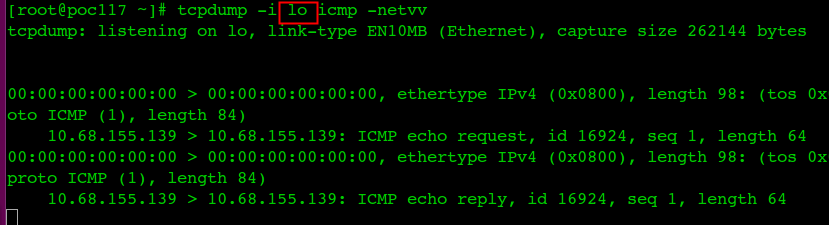
ipvs会放置DNAT钩子在INPUT链上,因此必须要让内核识别 VIP 是本机的 IP。这样才会过INPUT 链,要不然就通过OUTPUT链出去了。k8s 通过kube-proxy将service cluster ip 绑定到虚拟网卡kube-ipvs0。
同时在路由表中增加一些ipvs 的路由条目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
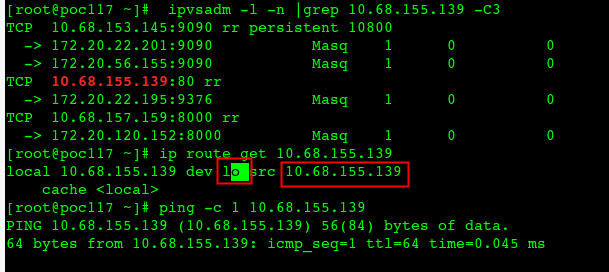
# ip route show table local local 10.68.0.1 dev kube-ipvs0 proto kernel scope host src 10.68.0.1 local 10.68.0.2 dev kube-ipvs0 proto kernel scope host src 10.68.0.2 local 10.68.70.130 dev kube-ipvs0 proto kernel scope host src 10.68.70.130 -- ipvs broadcast 127.0.0.0 dev lo proto kernel scope link src 127.0.0.1 local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1 broadcast 172.17.0.0 dev docker0 proto kernel scope link src 172.17.0.1 local 172.17.0.1 dev docker0 proto kernel scope host src 172.17.0.1 broadcast 172.17.255.255 dev docker0 proto kernel scope link src 172.17.0.1 local 172.20.185.192 dev tunl0 proto kernel scope host src 172.20.185.192 broadcast 172.20.185.192 dev tunl0 proto kernel scope link src 172.20.185.192 broadcast 172.26.128.0 dev eth0 proto kernel scope link src 172.26.137.117 local 172.26.137.117 dev eth0 proto kernel scope host src 172.26.137.117 broadcast 172.26.143.255 dev eth0 proto kernel scope link src 172.26.137.117
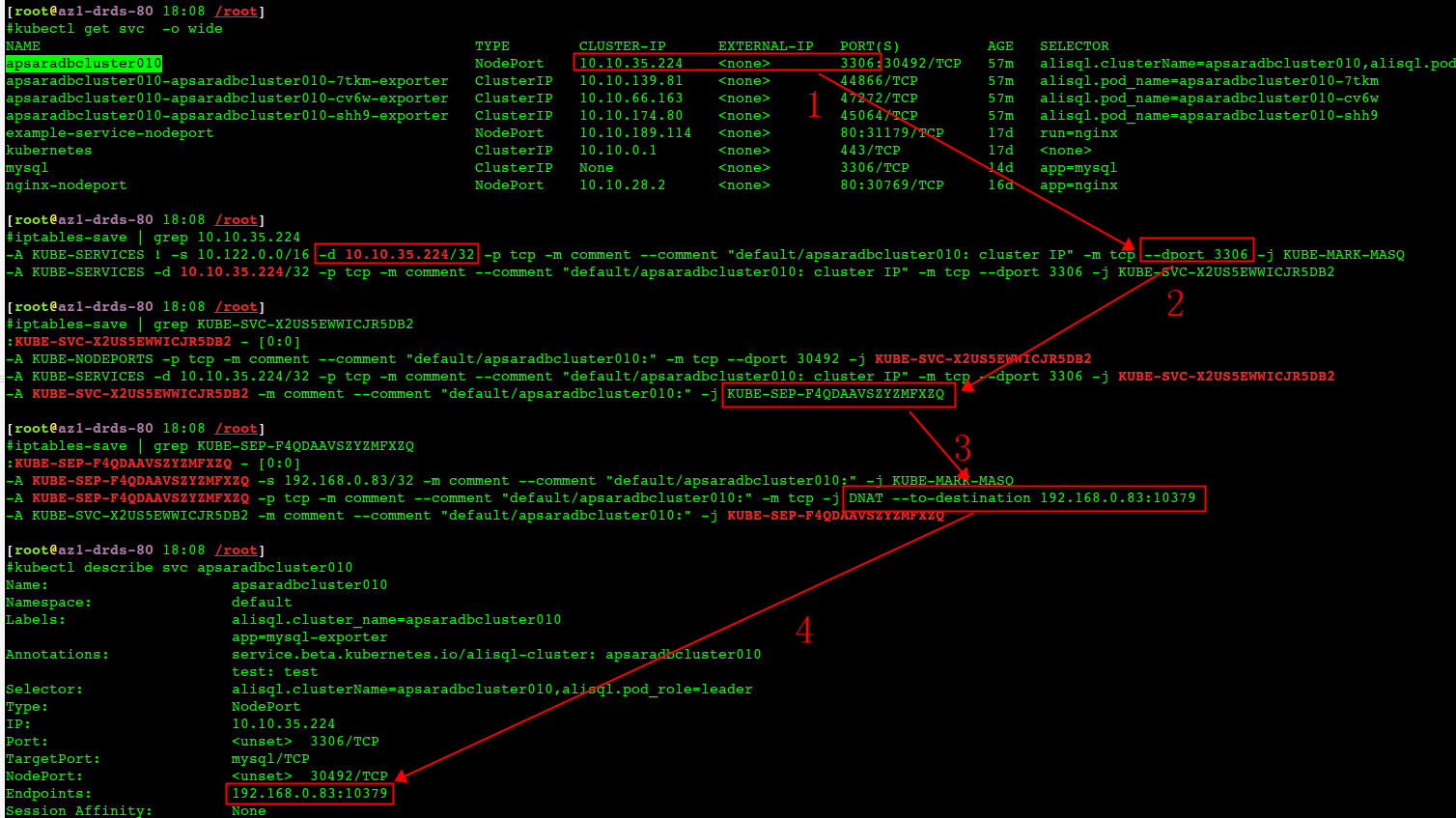
而接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略。我们可以通过 ipvsadm 查看到这个设置,如下所示:
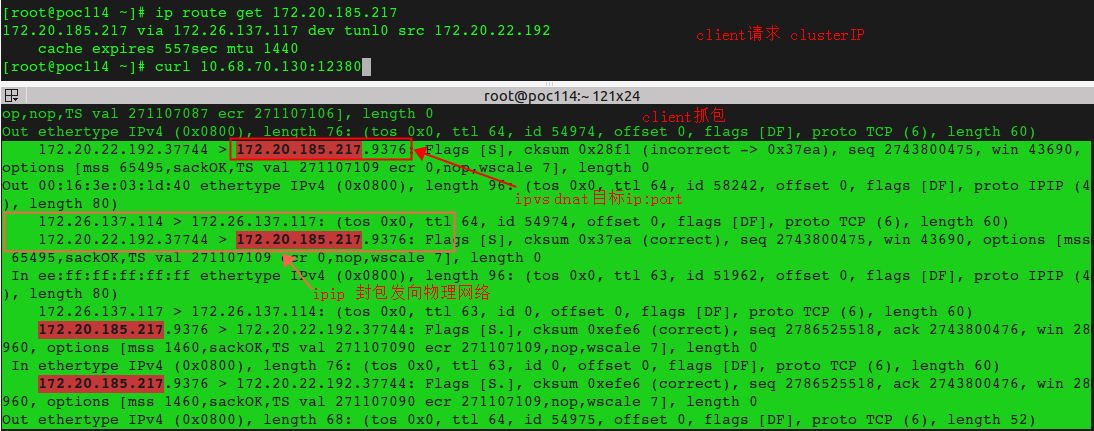
# ip route get 10.68.70.130 local 10.68.70.130 dev lo src 10.68.70.130 //这条规则指示了clusterIP是发给自己的 cache <local> # ip route get 172.20.185.217 172.20.185.217 via 172.26.137.117 dev tunl0 src 172.20.22.192 //这条规则指示clusterIP替换成POD IP后发给本地tunl0做ipip封包
kubectl looks up a Pod from the service information provided on the command line and forwards directly to a Pod rather than forwarding to the ClusterIP/Service port and allowing the cluster to load balance the service like regular service traffic.
To my (inexperienced) Go eyes, it appears the attachablePodForObject is the thing kubectl uses to look up a Pod to from a Service defined on the command line.
Then from there on everything deals with filling in the Pod specific PortForwardOptions (which doesn’t include a service) and is passed to the kubernetes API.
Service 和 DNS 的关系
Service 和 Pod 都会被分配对应的 DNS A 记录(从域名解析 IP 的记录)。
对于 ClusterIP 模式的 Service 来说(比如我们上面的例子),它的 A 记录的格式是:..svc.cluster.local。当你访问这条 A 记录的时候,它解析到的就是该 Service 的 VIP 地址。
而对于指定了 clusterIP=None 的 Headless Service 来说,它的 A 记录的格式也是:..svc.cluster.local。但是,当你访问这条 A 记录的时候,它返回的是所有被代理的 Pod 的 IP 地址的集合。当然,如果你的客户端没办法解析这个集合的话,它可能会只会拿到第一个 Pod 的 IP 地址。
# cat mysql-configmap.yaml //mysql配置文件放入: configmap apiVersion: v1 kind: ConfigMap metadata: name: mysql labels: app: mysql data: master.cnf: | # Apply this config only on the master. [mysqld] log-bin
mysqld.cnf: | [mysqld] pid-file = /var/run/mysqld/mysqld.pid socket = /var/run/mysqld/mysqld.sock datadir = /var/lib/mysql #log-error = /var/log/mysql/error.log # By default we only accept connections from localhost #bind-address = 127.0.0.1 # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION' # 慢查询阈值,查询时间超过阈值时写入到慢日志中 long_query_time = 2 innodb_buffer_pool_size = 257M
slave.cnf: | # Apply this config only on slaves. [mysqld] super-read-only
#cat $JWT_TOKEN_DEFAULT_DEFAULT eyJhbGciOiJSUzI1NiIsImtpZCI6ImlNVVFVNmxUM2t4c3Y2Q3IyT1BzV2hDZGRVSmVxTHc5RV8wUXZ4RVM5REEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJ: File name too long
//打开 coredump $gdb /opt/taobao/java/bin/java core.24086 [New LWP 27184] [New LWP 27186] [New LWP 24086] [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib64/libthread_db.so.1". Core was generated by `/opt/tt/java_coroutine/bin/java'. #0 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 Missing separate debuginfos, use: debuginfo-install jdk-8.9.14-20200203164153.alios7.x86_64 (gdb) info threads //查看所有thread Id Target Id Frame 583 Thread 0x7f2fa56177c0 (LWP 24086) 0x00007f2fa4fab017 in pthread_join () from /lib64/libpthread.so.0 582 Thread 0x7f2f695f3700 (LWP 27186) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 581 Thread 0x7f2f6cbfb700 (LWP 27184) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 580 Thread 0x7f2f691ef700 (LWP 27176) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 579 Thread 0x7f2f698f6700 (LWP 27174) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0
(gdb) thread apply all bt //查看所有线程堆栈 Thread 583 (Thread 0x7f2fa56177c0 (LWP 24086)): #0 0x00007f2fa4fab017 in pthread_join () from /lib64/libpthread.so.0 #1 0x00007f2fa4b85085 in ContinueInNewThread0 (continuation=continuation@entry=0x7f2fa4b7fd70 <JavaMain>, stack_size=1048576, args=args@entry=0x7ffe529432d0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/solaris/bin/java_md_solinux.c:1044 #2 0x00007f2fa4b81877 in ContinueInNewThread (ifn=ifn@entry=0x7ffe529433d0, threadStackSize=<optimized out>, argc=<optimized out>, argv=0x7f2fa3c163a8, mode=mode@entry=1, what=what@entry=0x7ffe5294be17 "com.taobao.tddl.server.TddlLauncher", ret=0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/share/bin/java.c:2033 #3 0x00007f2fa4b8513b in JVMInit (ifn=ifn@entry=0x7ffe529433d0, threadStackSize=<optimized out>, argc=<optimized out>, argv=<optimized out>, mode=mode@entry=1, what=what@entry=0x7ffe5294be17 "com.taobao.tddl.server.TddlLauncher", ret=ret@entry=0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/solaris/bin/java_md_solinux.c:1091 #4 0x00007f2fa4b8254d in JLI_Launch (argc=0, argv=0x7f2fa3c163a8, jargc=<optimized out>, jargv=<optimized out>, appclassc=1, appclassv=0x0, fullversion=0x400885 "1.8.0_232-b604", dotversion=0x400881 "1.8", pname=0x40087c "java", lname=0x40087c "java", javaargs=0 '\000', cpwildcard=1 '\001', javaw=0 '\000', ergo=0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/share/bin/java.c:304 #5 0x0000000000400635 in main ()
Thread 582 (Thread 0x7f2f695f3700 (LWP 27186)): #0 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 #1 0x00007f2fa342d863 in Parker::park(bool, long) () from /opt/taobao/install/ajdk-8_9_14-b604/jre/lib/amd64/server/libjvm.so #2 0x00007f2fa35ba3c3 in Unsafe_Park () from /opt/taobao/install/ajdk-8_9_14-b604/jre/lib/amd64/server/libjvm.so #3 0x00007f2f9343b44a in ?? () #4 0x000000008082e778 in ?? () #5 0x0000000000000003 in ?? () #6 0x00007f2f88e32758 in ?? () #7 0x00007f2f6f532800 in ?? ()
Attaching to core core.24086 from executable /opt/taobao/java/bin/java, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.232-b604 Deadlock Detection:
//打开 coredump $gdb /opt/taobao/java/bin/java core.24086 [New LWP 27184] [New LWP 27186] [New LWP 24086] [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib64/libthread_db.so.1". Core was generated by `/opt/tt/java_coroutine/bin/java'. #0 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 Missing separate debuginfos, use: debuginfo-install jdk-8.9.14-20200203164153.alios7.x86_64 (gdb) info threads //查看所有thread Id Target Id Frame 583 Thread 0x7f2fa56177c0 (LWP 24086) 0x00007f2fa4fab017 in pthread_join () from /lib64/libpthread.so.0 582 Thread 0x7f2f695f3700 (LWP 27186) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 581 Thread 0x7f2f6cbfb700 (LWP 27184) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 580 Thread 0x7f2f691ef700 (LWP 27176) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 579 Thread 0x7f2f698f6700 (LWP 27174) 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0
(gdb) thread apply all bt //查看所有线程堆栈 Thread 583 (Thread 0x7f2fa56177c0 (LWP 24086)): #0 0x00007f2fa4fab017 in pthread_join () from /lib64/libpthread.so.0 #1 0x00007f2fa4b85085 in ContinueInNewThread0 (continuation=continuation@entry=0x7f2fa4b7fd70 <JavaMain>, stack_size=1048576, args=args@entry=0x7ffe529432d0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/solaris/bin/java_md_solinux.c:1044 #2 0x00007f2fa4b81877 in ContinueInNewThread (ifn=ifn@entry=0x7ffe529433d0, threadStackSize=<optimized out>, argc=<optimized out>, argv=0x7f2fa3c163a8, mode=mode@entry=1, what=what@entry=0x7ffe5294be17 "com.taobao.tddl.server.TddlLauncher", ret=0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/share/bin/java.c:2033 #3 0x00007f2fa4b8513b in JVMInit (ifn=ifn@entry=0x7ffe529433d0, threadStackSize=<optimized out>, argc=<optimized out>, argv=<optimized out>, mode=mode@entry=1, what=what@entry=0x7ffe5294be17 "com.taobao.tddl.server.TddlLauncher", ret=ret@entry=0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/solaris/bin/java_md_solinux.c:1091 #4 0x00007f2fa4b8254d in JLI_Launch (argc=0, argv=0x7f2fa3c163a8, jargc=<optimized out>, jargv=<optimized out>, appclassc=1, appclassv=0x0, fullversion=0x400885 "1.8.0_232-b604", dotversion=0x400881 "1.8", pname=0x40087c "java", lname=0x40087c "java", javaargs=0 '\000', cpwildcard=1 '\001', javaw=0 '\000', ergo=0) at /ssd1/jenkins_home/workspace/ajdk.8.build.master/jdk/src/share/bin/java.c:304 #5 0x0000000000400635 in main ()
Thread 582 (Thread 0x7f2f695f3700 (LWP 27186)): #0 0x00007f2fa4fada35 in pthread_cond_wait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0 #1 0x00007f2fa342d863 in Parker::park(bool, long) () from /opt/taobao/install/ajdk-8_9_14-b604/jre/lib/amd64/server/libjvm.so #2 0x00007f2fa35ba3c3 in Unsafe_Park () from /opt/taobao/install/ajdk-8_9_14-b604/jre/lib/amd64/server/libjvm.so #3 0x00007f2f9343b44a in ?? () #4 0x000000008082e778 in ?? () #5 0x0000000000000003 in ?? () #6 0x00007f2f88e32758 in ?? () #7 0x00007f2f6f532800 in ?? ()
Attaching to core core.24086 from executable /opt/taobao/java/bin/java, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.232-b604 Deadlock Detection:
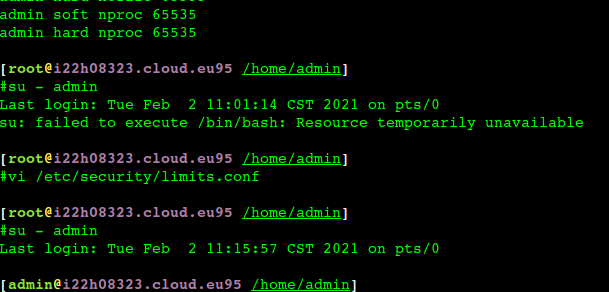
$cat /etc/pam.d/system-auth #%PAM-1.0 # This file is auto-generated. # User changes will be destroyed the next time authconfig is run. auth required pam_env.so auth required pam_faildelay.so delay=2000000 auth sufficient pam_unix.so nullok try_first_pass auth requisite pam_succeed_if.so uid >= 1000 quiet_success auth required pam_deny.so
If dmesg does not show any information about NUMA, then increase the Ring Buffer size: Boot with ‘log_buf_len=16M’ (or some other big value). Refer the following kbase article How do I increase the kernel log ring buffer size? for steps on how to increase the ring buffer
Please install a package which provides this module, or verify that the module is installed correctly.
It's possible that the above module doesn't match the current version of Python, which is: 2.6.6 (r266:84292, Sep 4 2013, 07:46:00) [GCC 4.4.7 20120313 (Red Hat 4.4.7-3)]
If you cannot solve this problem yourself, please go to the yum faq at: http://yum.baseurl.org/wiki/Faq
Check and fix the related library paths or remove 3rd party libraries, usually libcurl or libssh2. On a x86_64 system, the standard paths for those libraries are /usr/lib64/libcurl.so.4 and /usr/lib64/libssh2.so.1
PROCESS STATE CODES Here are the different values that the s, stat and state output specifiers(header "STAT" or "S") will display to describe the state of a process: D uninterruptible sleep (usually IO) #不可中断睡眠 不接受任何信号,因此kill对它无效,一般是磁盘io,网络io读写时出现 R running or runnable (on run queue) #可运行状态或者运行中,可运行状态表明进程所需要的资源准备就绪,待内核调度 S interruptible sleep (waiting for an event to complete) #可中断睡眠,等待某事件到来而进入睡眠状态 T stopped by job control signal #进程暂停状态 平常按下的ctrl+z,实际上是给进程发了SIGTSTP 信号 (kill -l可查看系统所有的信号量) t stopped by debugger during the tracing #进程被ltrace、strace attach后就是这种状态 W paging (not valid since the 2.6.xx kernel) #没有用了 X dead (should never be seen) #进程退出时的状态 Z defunct ("zombie") process, terminated but not reaped by its parent #进程退出后父进程没有正常回收,俗称僵尸进程
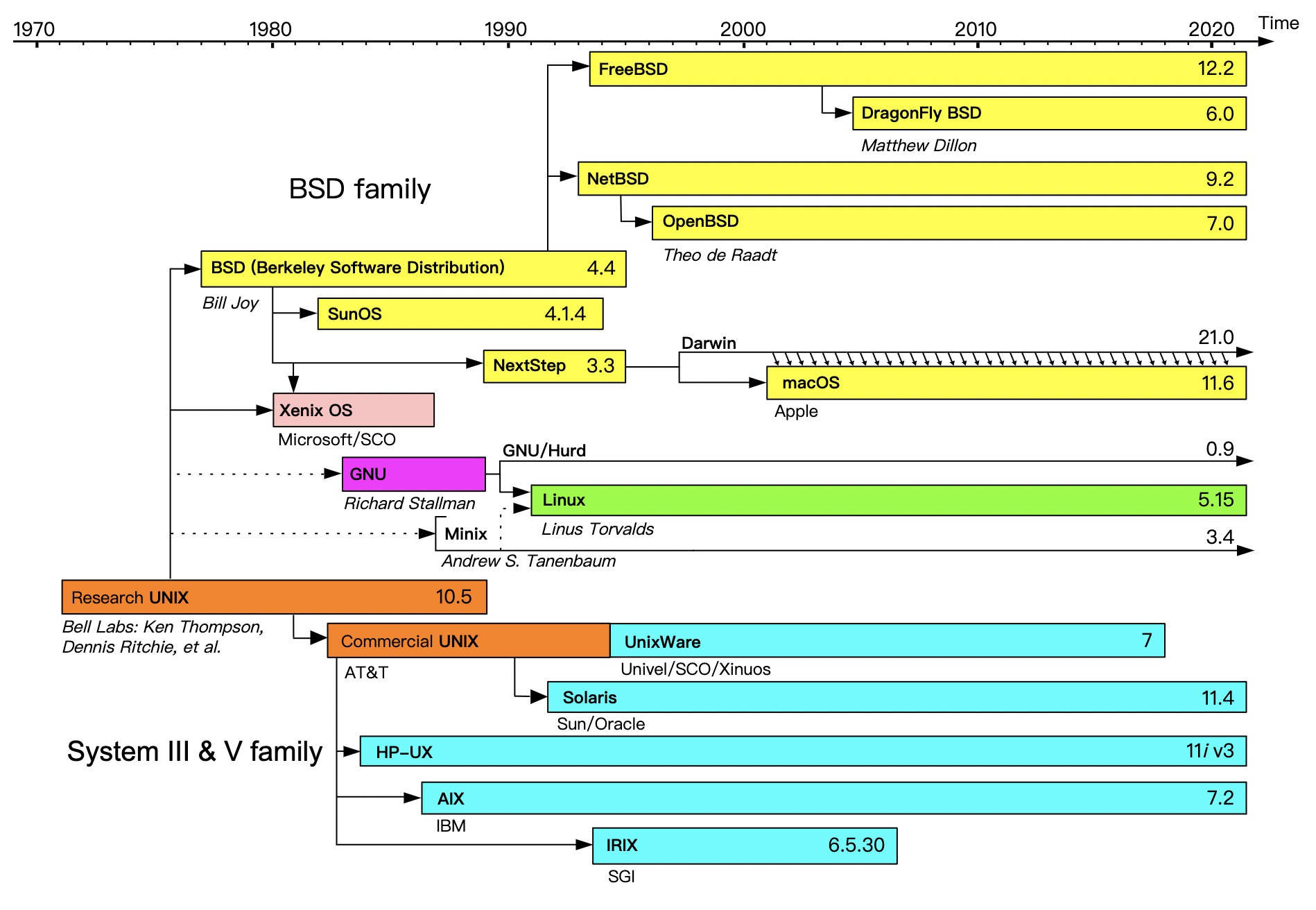
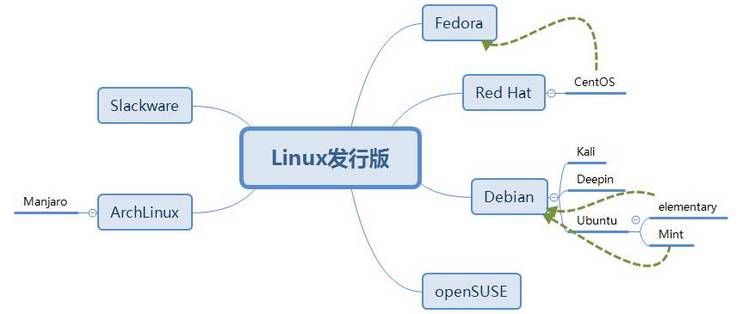
Fedora:基于Red Hat Linux,在Red Hat Linux终止发行后,红帽公司计划以Fedora来取代Red Hat Linux在个人领域的应用,而另外发行的Red Hat Enterprise Linux取代Red Hat Linux在商业应用的领域。Fedora的功能对于用户而言,它是一套功能完备、更新快速的免费操作系统,而对赞助者Red Hat公司而言,它是许多新技术的测试平台,被认为可用的技术最终会加入到Red Hat Enterprise Linux中。Fedora大约每六个月发布新版本。