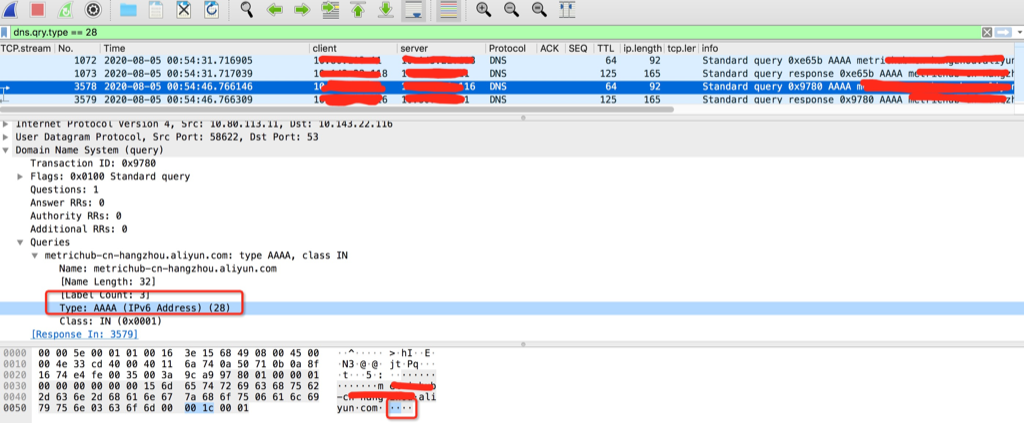
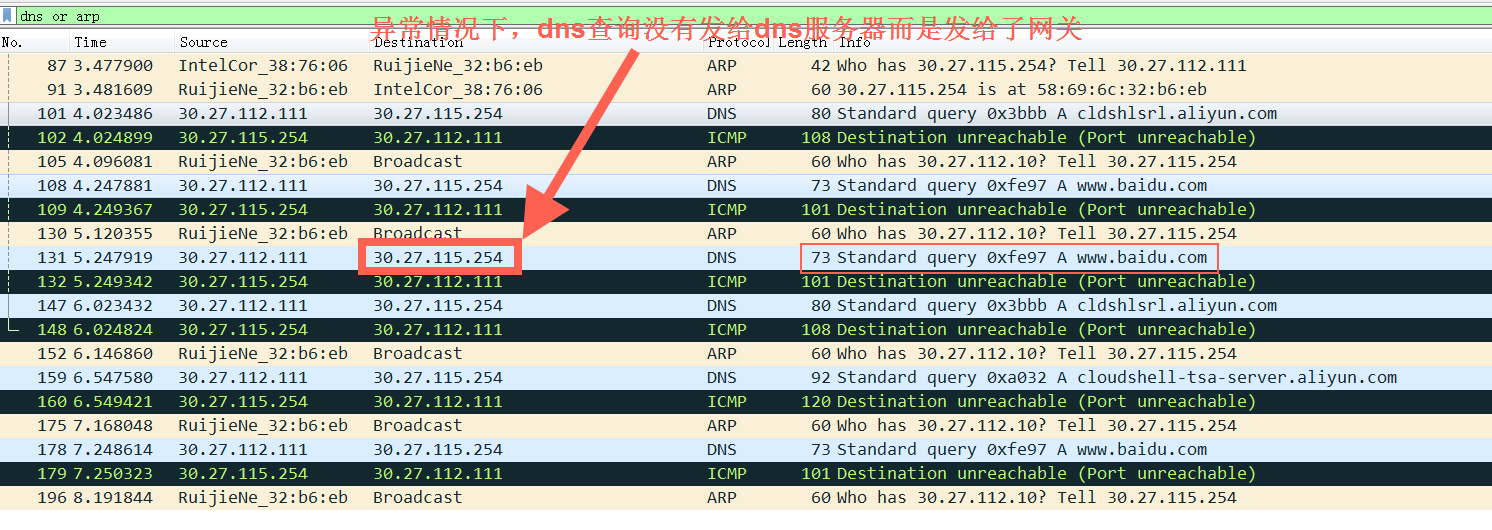
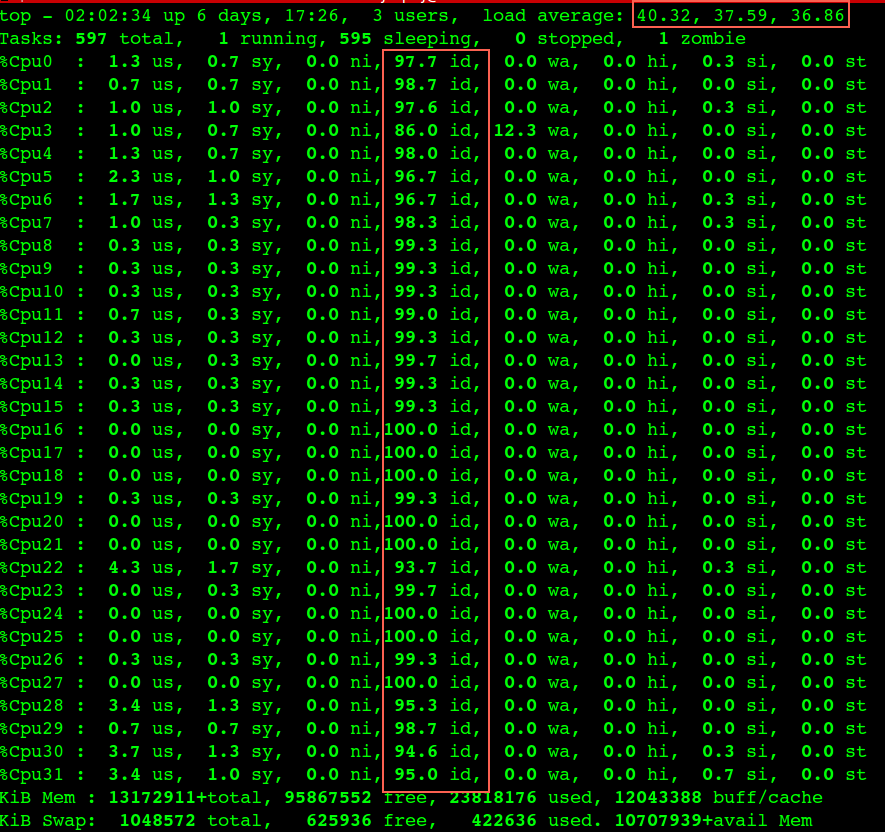
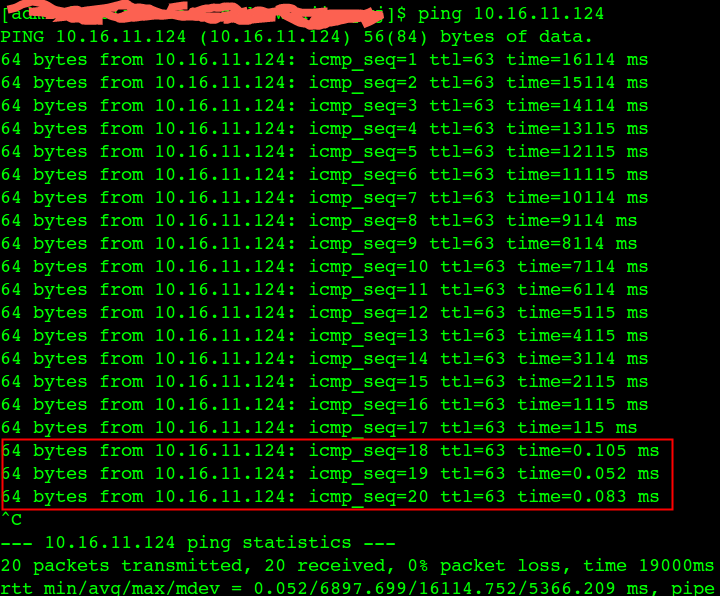
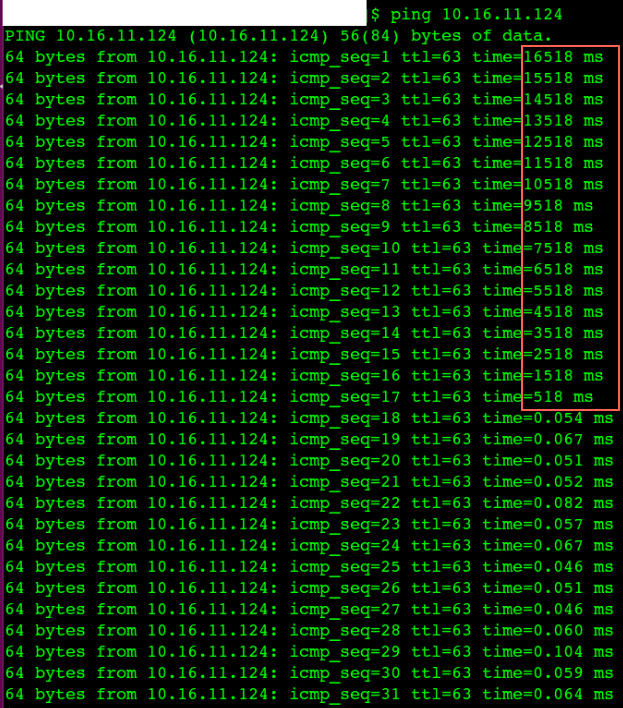
Linux Module and make debug
Linux Module and make debug
Makefile 中的 tab 键
$sudo make
Makefile:4: *** missing separator. Stop.
Makefile 中每个指令前面必须是tab(不能是4个空格)!
pwd
$sudo make
make -C /lib/modules/4.19.48-002.ali4000.test.alios7.x86_64/build M= modules
make[1]: Entering directory `/usr/src/kernels/4.19.48-002.ali4000.test.alios7.x86_64'
make[2]: *** No rule to make target `arch/x86/entry/syscalls/syscall_32.tbl', needed by `arch/x86/include/generated/asm/syscalls_32.h'. Stop.
make[1]: *** [archheaders] Error 2
make[1]: Leaving directory `/usr/src/kernels/4.19.48-002.ali4000.test.alios7.x86_64'
make: *** [all] Error 2
Makefile中的:
make -C /lib/modules/$(shell uname -r)/build M=$(pwd) modules
$(pwd) 需要修改成:$(shell pwd)
makefile调试的法宝
makefile调试的法宝1
$ make --debug=a,m SHELL="bash -x" > make.log 2>&1 # 可以获取make过程最完整debug信息
$ make --debug=v,m SHELL="bash -x" > make.log 2>&1 # 一个相对精简版,推荐使用这个命令
$ make --debug=v > make.log 2>&1 # 再精简一点的版本
$ make --debug=b > make.log 2>&1 # 最精简的版本
推荐版本(会输出执行的具体命令):
make --debug=b SHELL="bash -x" > make.log.simple 2>&1
or
make V=1
makefile调试的法宝2
上面的法宝1更多的还是在整体工程的makefile结构、makefile读取和makefile内部的rule之间的关系方面有很好的帮助作用。但是对于makefile中rule部分之前的变量部分的引用过程则表现的不是很充分。在这里,我们有另外一个法宝,可以把变量部分的引用过程给出一个比较好的调试信息。具体命令如下。
$ make -p 2>&1 | grep -A 1 '^# makefile' | grep -v '^--' | awk '/# makefile/&&/line/{getline n;print $0,";",n}' | LC_COLLATE=C sort -k 4 -k 6n > variable.log
$ cat variable.log
# makefile (from `Makefile', line 1) ; aa := 11
# makefile (from `Makefile', line 3) ; cc := 11
# makefile (from `Makefile', line 4) ; bb := 9999
# makefile (from `cfg_makefile', line 1) ; MAKEFILE_LIST := Makefile cfg_makefile
# makefile (from `cfg_makefile', line 1) ; xx := 4444
# makefile (from `cfg_makefile', line 2) ; yy := 4444
# makefile (from `cfg_makefile', line 3) ; zz := 4444
# makefile (from `sub_makefile', line 1) ; MAKEFILE_LIST := sub_makefile
# makefile (from `sub_makefile', line 1) ; aaaa := 222222
# makefile (from `sub_makefile', line 2) ; bbbb := 222222
# makefile (from `sub_makefile', line 3) ; cccc := 222222
makefile调试的法宝3
法宝2可以把makefile文件中每个变量的最终值清晰的展现出来,但是对于这些变量引用过程中的中间值却没有展示。此时,我们需要依赖法宝3来帮助我们。
$(warning $(var123))
很多人可能都知道这个warning语句。我们可以在makefile文件中的变量引用阶段的任何两行之间,添加这个语句打印关键变量的引用过程。
make 时ld报找不到lib
make总是报找不到libc,但实际我执行 ld -lc –verbose 从debug信息看又能够正确找到libc,debug方法
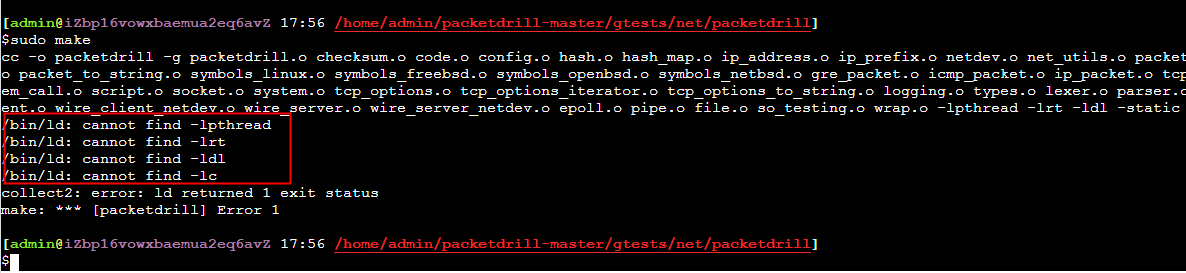
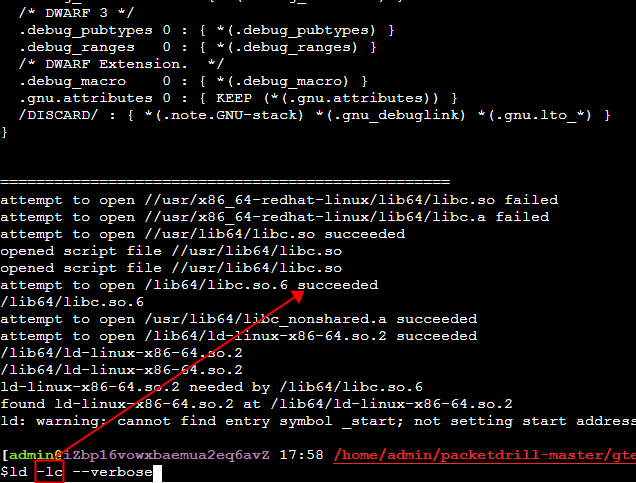
实际原因是make的时候最后有一个参数 -static,这要求得装 ***-static lib库,可以去掉 -static
依赖错误
编译报错缺少的组件需要yum install一下(bison/flex)
hping3
构造半连接:
sudo hping3 -i u100 -S -p 3306 10.0.186.79
tcp sk_state
enum {
TCP_ESTABLISHED = 1,
TCP_SYN_SENT,
TCP_SYN_RECV,
TCP_FIN_WAIT1,
TCP_FIN_WAIT2,
TCP_TIME_WAIT,
TCP_CLOSE,
TCP_CLOSE_WAIT,
TCP_LAST_ACK,
TCP_LISTEN,
TCP_CLOSING, /* Now a valid state */
TCP_MAX_STATES /* Leave at the end! */
};
kdump
启动kdump(kexec-tools), 系统崩溃的时候dump 内核(/var/crash)
sudo systemctl start kdump
Kdump 的概念出现在 2005 左右,是迄今为止最可靠的内核转存机制,已经被主要的 linux™ 厂商选用。kdump是一种先进的基于 kexec 的内核崩溃转储机制。当系统崩溃时,kdump 使用 kexec 启动到第二个内核。第二个内核通常叫做捕获内核,以很小的内存启动以捕获转储镜像。
第一个内核保留了内存的一部分给第二个内核启动用。由于 kdump 利用 kexec 启动捕获内核,绕过了 BIOS,所以第一个内核的内存得以保留。这是内核崩溃转储的本质。
kdump 需要两个不同目的的内核,生产内核和捕获内核。生产内核是捕获内核服务的对象。捕获内核会在生产内核崩溃时启动起来,与相应的 ramdisk 一起组建一个微环境,用以对生产内核下的内存进行收集和转存。
什么是 kexec ?
Kexec 是实现 kdump 机制的关键,它包括 2 一是组成部分:一是内核空间的系统调用 kexec_load,负责在生产内核(production kernel 或 first kernel)启动时将捕获内核(capture kernel 或 sencond kernel)加载到指定地址。二是用户空间的工具 kexec-tools,他将捕获内核的地址传递给生产内核,从而在系统崩溃的时候能够找到捕获内核的地址并运行。
没有 kexec 就没有 kdump。先有 kexec 实现了在一个内核中可以启动另一个内核,才让 kdump 有了用武之地。kexec 原来的目的是为了节省时间 kernel 开发人员重启系统的时间,谁能想到这个“偷懒”的技术却孕育了最成功的内存转存机制呢?
crash
sudo yum install crash -y
//手动触发crash
#echo 1 > /proc/sys/kernel/sysrq
#echo c > /proc/sysrq-trigger
//系统crash,然后重启,重启后分析:
sudo crash /usr/lib/debug/lib/modules/4.19.57-15.1.al7.x86_64/vmlinux /var/crash/127.0.0.1-2020-04-02-14\:40\:45/vmcore
可以触发dump但是系统没有crash, 以下两个命令都可以
1 | sudo crash /usr/lib/debug/usr/lib/modules/4.19.91-19.1.al7.x86_64/vmlinux /proc/kcore |
内核函数替换
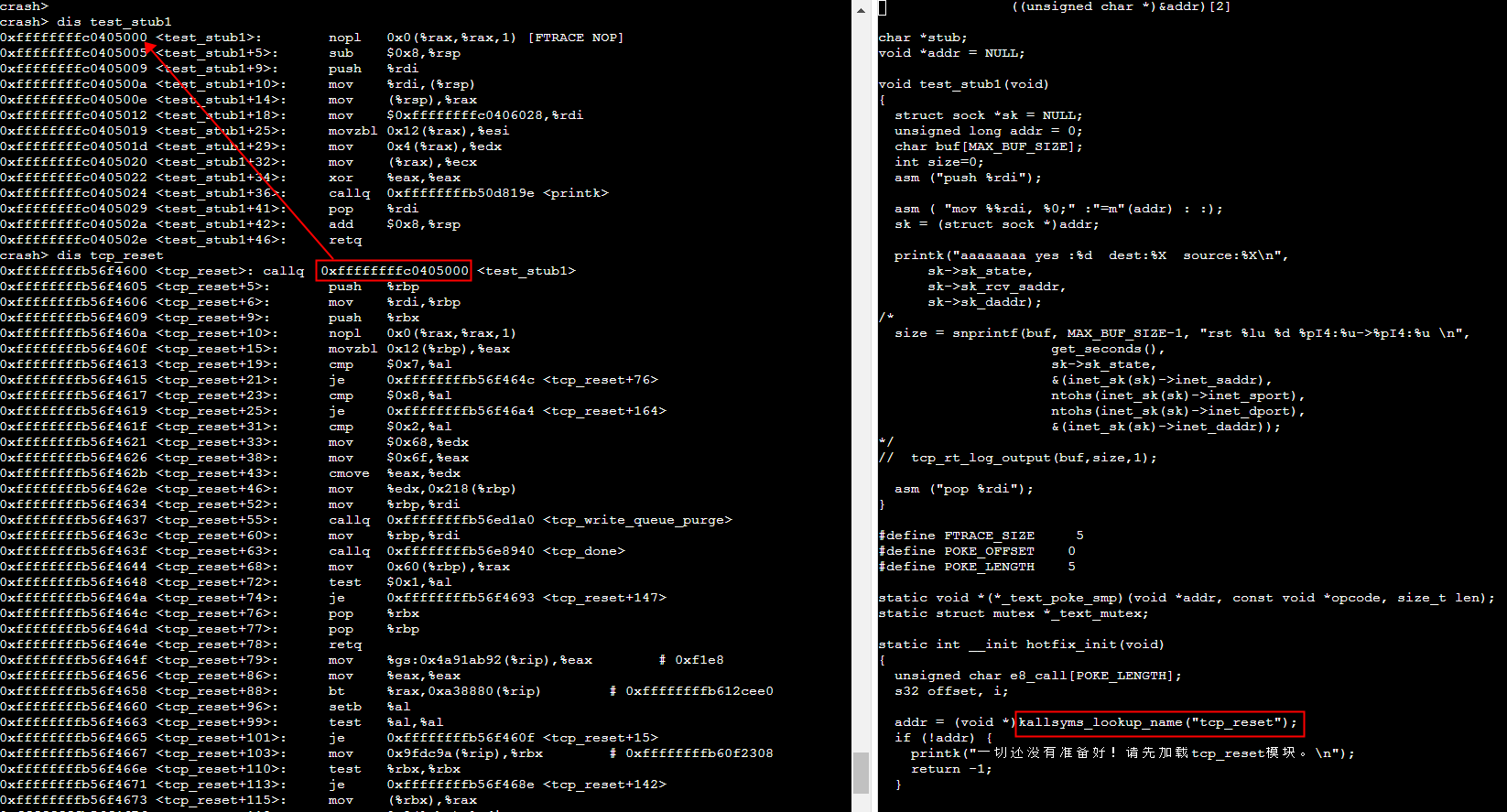
static int __init hotfix_init(void)
{
unsigned char e8_call[POKE_LENGTH];
s32 offset, i;
addr = (void *)kallsyms_lookup_name("tcp_reset");
if (!addr) {
printk("一切还没有准备好!请先加载tcp_reset模块。\n");
return -1;
}
_text_poke_smp = (void *)kallsyms_lookup_name("text_poke");
_text_mutex = (void *)kallsyms_lookup_name("text_mutex");
stub = (void *)test_stub1;
offset = (s32)((long)stub - (long)addr - FTRACE_SIZE);
e8_call[0] = 0xe8;
(*(s32 *)(&e8_call[1])) = offset;
for (i = 5; i < POKE_LENGTH; i++) {
e8_call[i] = 0x90;
}
get_online_cpus();
mutex_lock(_text_mutex);
_text_poke_smp(&addr[POKE_OFFSET], e8_call, POKE_LENGTH);
mutex_unlock(_text_mutex);
put_online_cpus();
return 0;
}
void test_stub1(void)
{
struct sock *sk = NULL;
unsigned long sk_addr = 0;
char buf[MAX_BUF_SIZE];
int size=0;
asm ("push %rdi");
asm ( "mov %%rdi, %0;" :"=m"(sk_addr) : :);
sk = (struct sock *)sk_addr;
printk("aaaaaaaa yes :%d dest:%X source:%X\n",
sk->sk_state,
sk->sk_rcv_saddr,
sk->sk_daddr);
/*
size = snprintf(buf, MAX_BUF_SIZE-1, "rst %lu %d %pI4:%u->%pI4:%u \n",
get_seconds(),
sk->sk_state,
&(inet_sk(sk)->inet_saddr),
ntohs(inet_sk(sk)->inet_sport),
ntohs(inet_sk(sk)->inet_dport),
&(inet_sk(sk)->inet_daddr));
*/
// tcp_rt_log_output(buf,size,1);
asm ("pop %rdi");
}
参考文档
https://blog.sourcerer.io/writing-a-simple-linux-kernel-module-d9dc3762c234
https://stackoverflow.com/questions/16710047/usr-bin-ld-cannot-find-lnameofthelibrary