Docker中的DNS解析过程
Docker中的DNS解析过程
问题描述
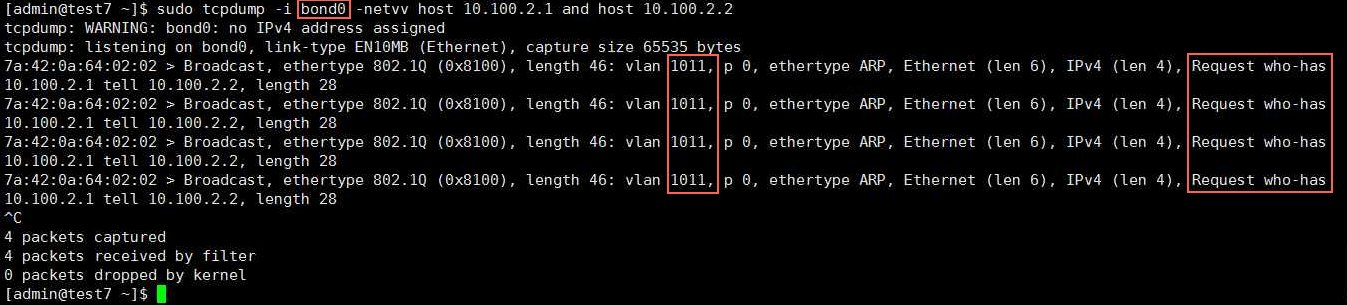
同一个Docker集群中两个容器中通过 nslookup 同一个域名,这个域名是容器启动的时候通过net alias指定的,但是返回来的IP不一样
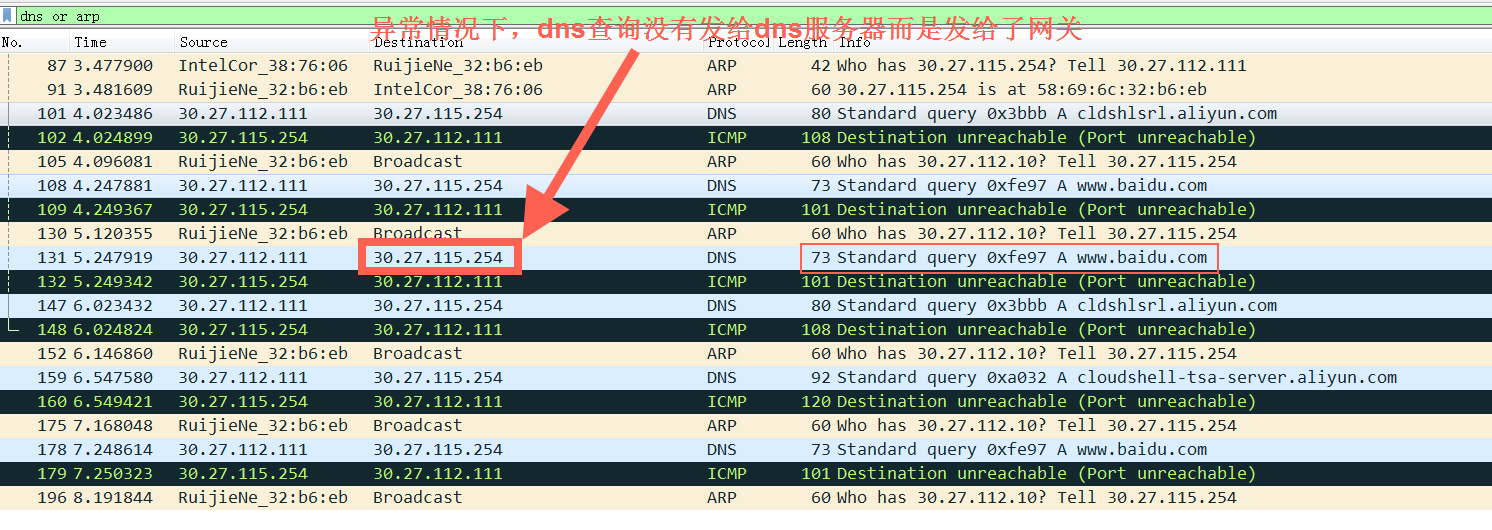
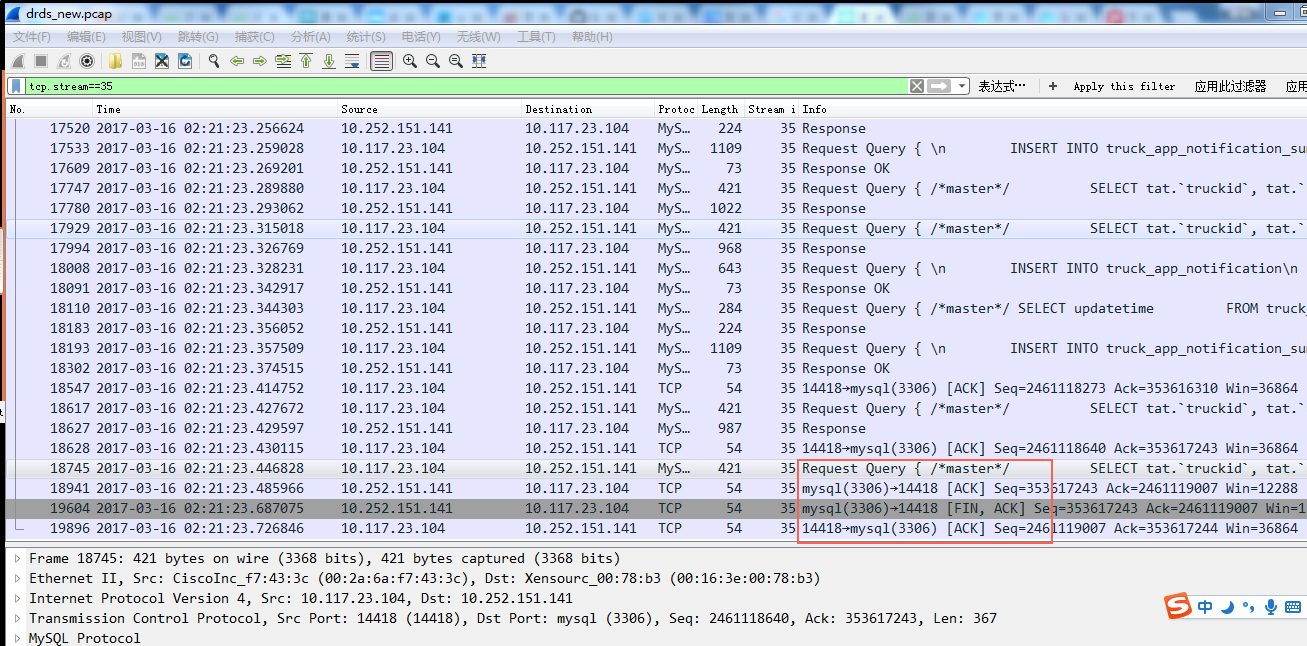
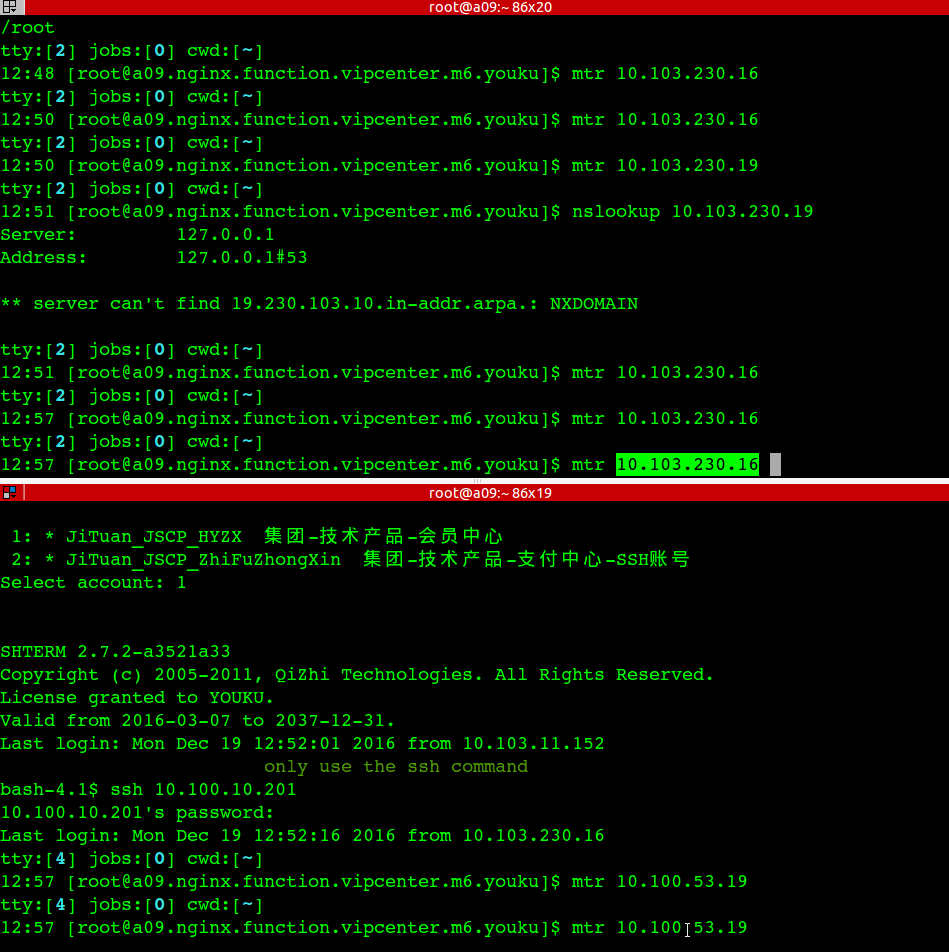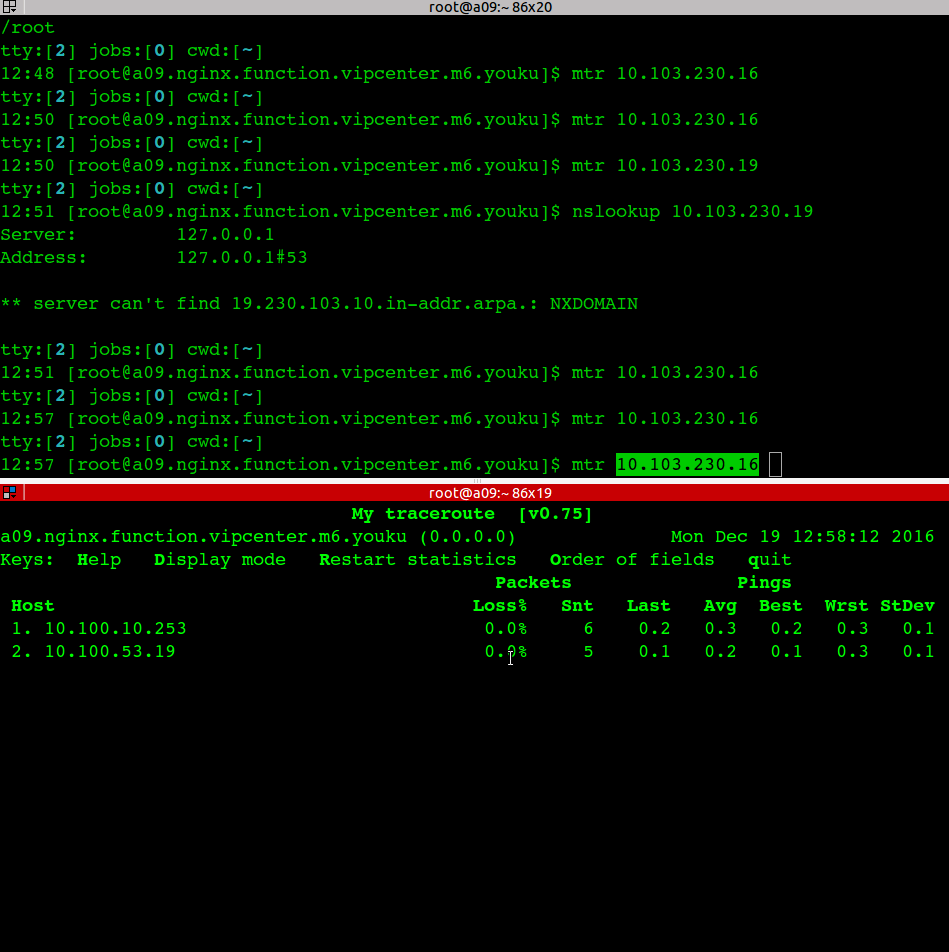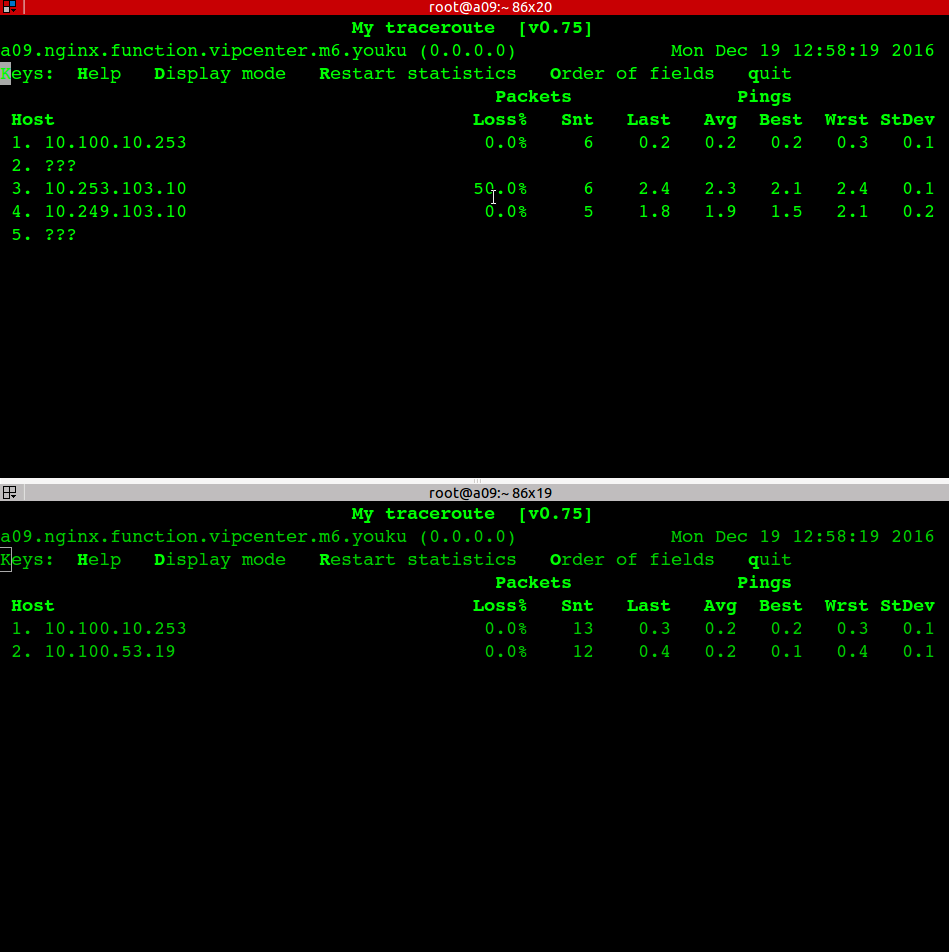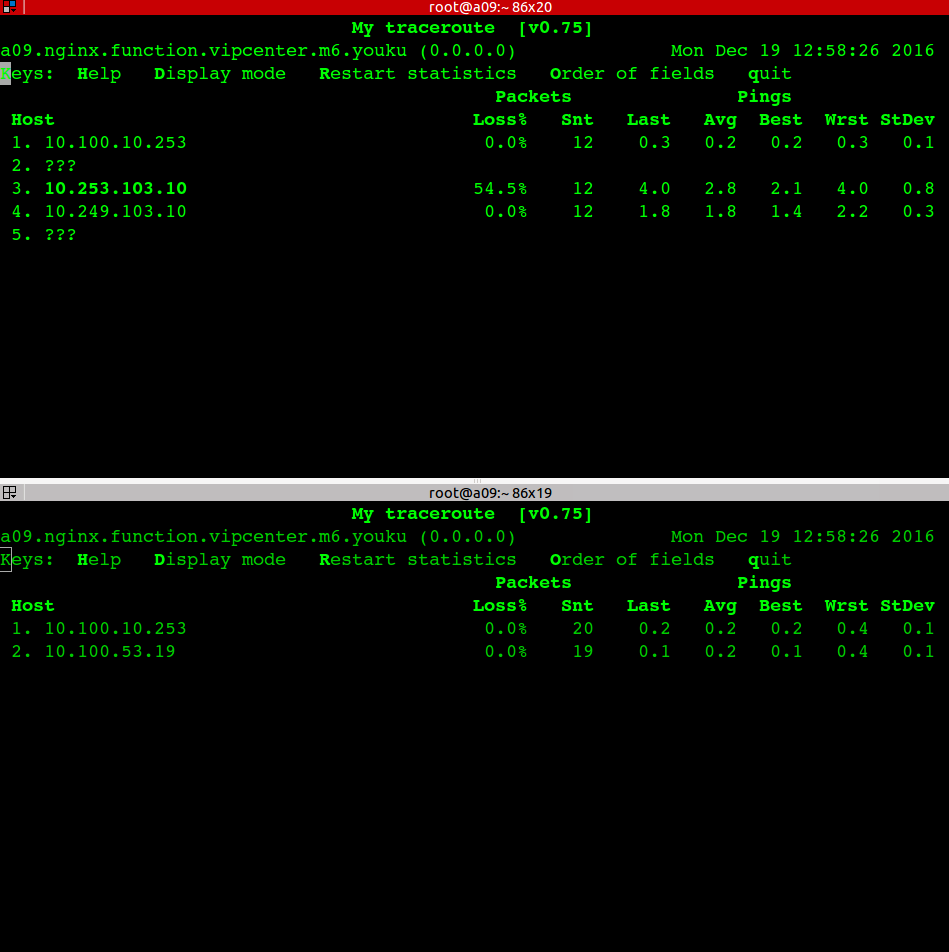
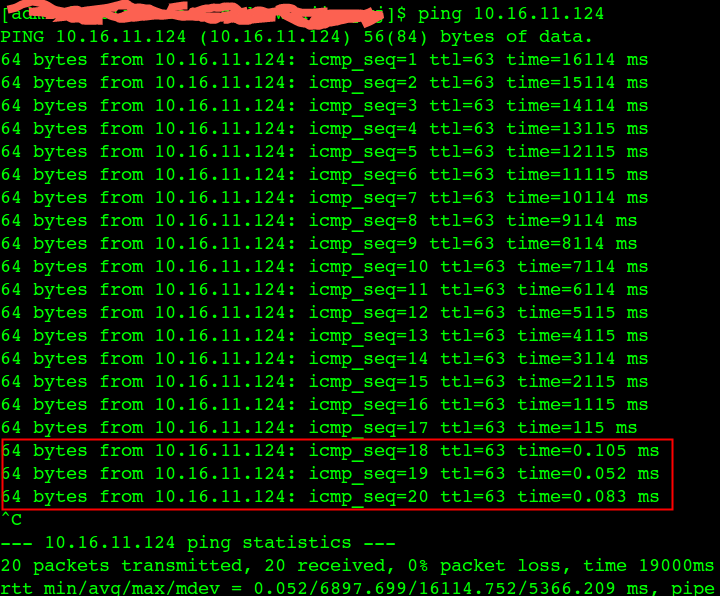
如图所示:
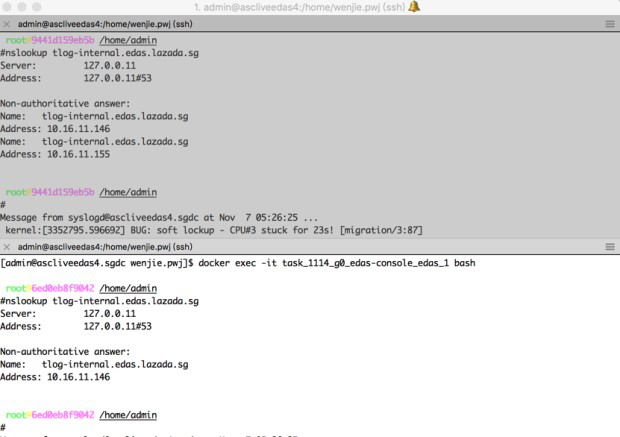
图中上面的容器中 nslookup 返回来了两个IP,但是只有146是正确的,155是多出来,不对的。
要想解决这个问题抓包就没用了,因为Docker 中的net alias 域名是 Docker Daemon自己来解析的,也就是在容器中做域名解析(nslookup、ping)的时候,Docker Daemon先看这个域名是不是net alias的,是的话返回对应的ip,如果不是(比如 www.baidu.com) ,那么Docker Daemon再把这个域名丢到宿主机上去解析,在宿主机上的解析过程就是标准的DNS,可以抓包分析。但是Docker Daemon内部的解析过程没有走DNS协议,不好分析,所以得先了解一下 Docker Daemon的域名解析原理
具体参考文章: http://www.jianshu.com/p/4433f4c70cf0 http://www.bijishequ.com/detail/261401?p=70-67
继续分析所有容器对这个域名的解析
继续分析所有容器对这个域名的解析发现只有某一台宿主机上的有这个问题,而且这台宿主机上所有容器都有这个问题,结合上面的文章,那么这个问题比较明朗了,这台有问题的宿主机的Docker Daemon中残留了一个net alias,你可以理解成cache中有脏数据没有清理。
进而跟业务的同学们沟通,确实155这个IP的容器做过升级,改动过配置,可能升级前这个155也绑定过这个域名,但是升级后绑到146这个容器上去了,但是Docker Daemon中还残留这条记录。
重启Docker Daemon后问题解决(容器不需要重启)
重启Docker Daemon的时候容器还在正常运行,只是这段时间的域名解析会不正常,其它业务长连接都能正常运行,在Docker Daemon重启的时候它会去检查所有容器的endpoint、重建sandbox、清理network等等各种事情,所以就把这个脏数据修复掉了。
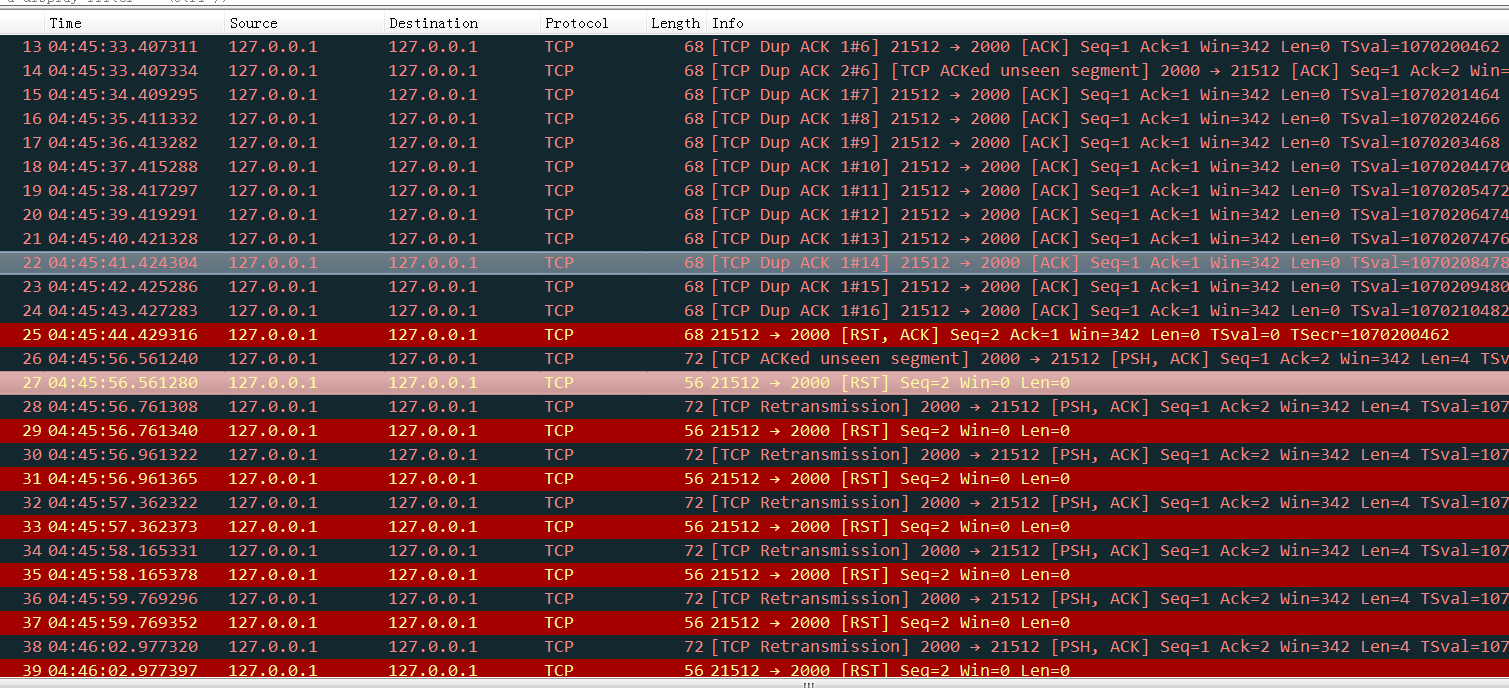
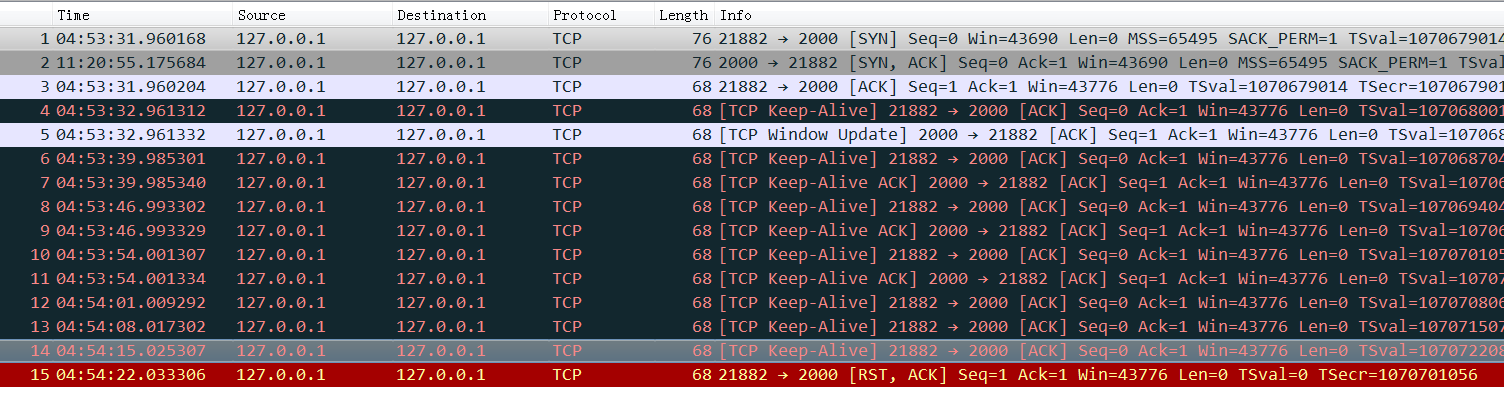
在Docker Daemon重启过程中,会给每个容器构建DNS Resovler(setup-resolver),如果构建DNS Resovler这个过程中容器发送了大量域名查询过来同时这些域名又查询不到的话Docker Daemon在重启过程中需要等待这个查询超时,然后才能继续往下走重启流程,所以导致启动流程拉长问题严重的时候导致Docker Daemon长时间无法启动
Docker的域名解析为什么要这么做,是因为容器中有两种域名解析需求:
- 容器启动时通过 net alias 命名的域名
- 容器中正常对外网各种域名的解析(比如 baidu.com/api.taobao.com)
对于第一种只能由docker daemon来解析了,所以容器中碰到的任何域名解析都会丢给 docker daemon(127.0.0.11), 如果 docker daemon 发现这个域名不认识,也就是不是net alias命名的域名,那么docker就会把这个域名解析丢给宿主机配置的 nameserver 来解析【非常非常像 dns-f/vipclient 的解析原理】
容器中的域名解析
容器启动的时候读取宿主机的 /etc/resolv.conf (去掉127.0.0.1/16 的nameserver)然后当成容器的 /etc/resolv.conf, 但是实际在容器中看到的 /etc/resolve.conf 中的nameserver只有一个:127.0.0.11,因为如上描述nameserver都被代理掉了
容器 -> docker daemon(127.0.0.11) -> 宿主机中的/etc/resolv.conf 中的nameserver
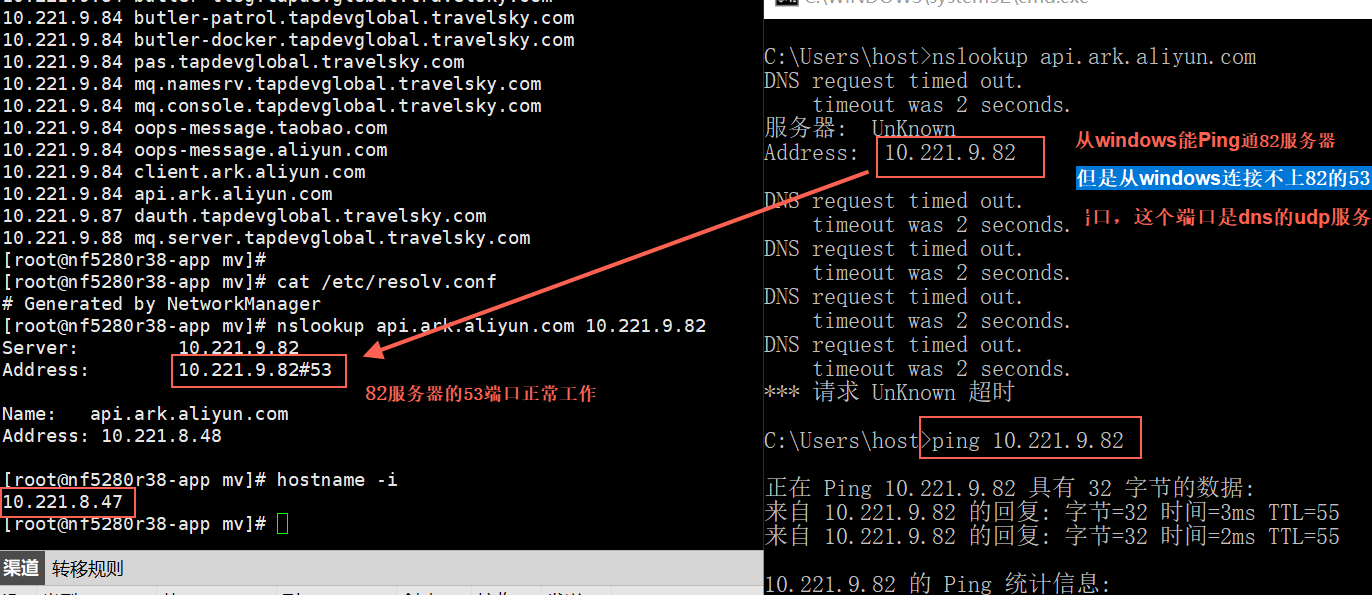
如果宿主机中的/etc/resolv.conf 中的nameserver没有,那么daemon默认会用8.8.8.8/8.8.4.4来做下一级dns server,如果在一些隔离网络中(跟外部不通),那么域名解析就会超时,因为一直无法连接到 8.8.8.8/8.8.4.4 ,进而导致故障。
比如 vipserver 中需要解析 armory的域名,如果这个时候在私有云环境,宿主机又没有配置 nameserver, 那么这个域名解析会发送给 8.8.8.8/8.8.4.4 ,长时间没有响应,超时后 vipserver 会关闭自己的探活功能,从而导致 vipserver 基本不可用一样。
修改 宿主机的/etc/resolv.conf后 重新启动、创建的容器才会load新的nameserver
如果容器中需要解析vipserver中的域名
- 容器中安装vipclient,同时容器的 /etc/resolv.conf 配置 nameserver 127.0.0.1
- 要保证vipclient起来之后才能启动业务
kubernetes中dns解析偶尔5秒钟超时
dns解析默认会发出ipv4和ipv6,一般dns没有配置ipv6,会导致ipv6解析等待5秒超时后再发出ipv4解析得到正确结果。应用表现出来就是偶尔卡顿了5秒
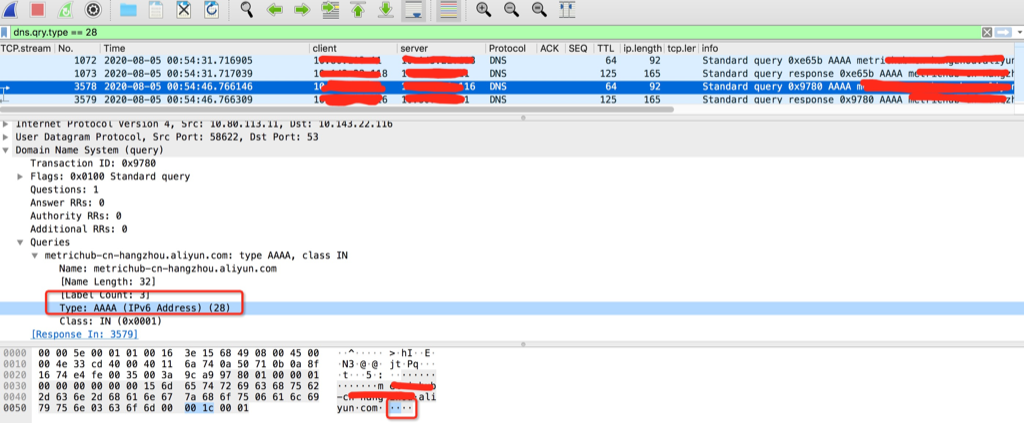
(高亮行delay 5秒才发出查询,是因为高亮前一行等待5秒都没有等到查询结果)
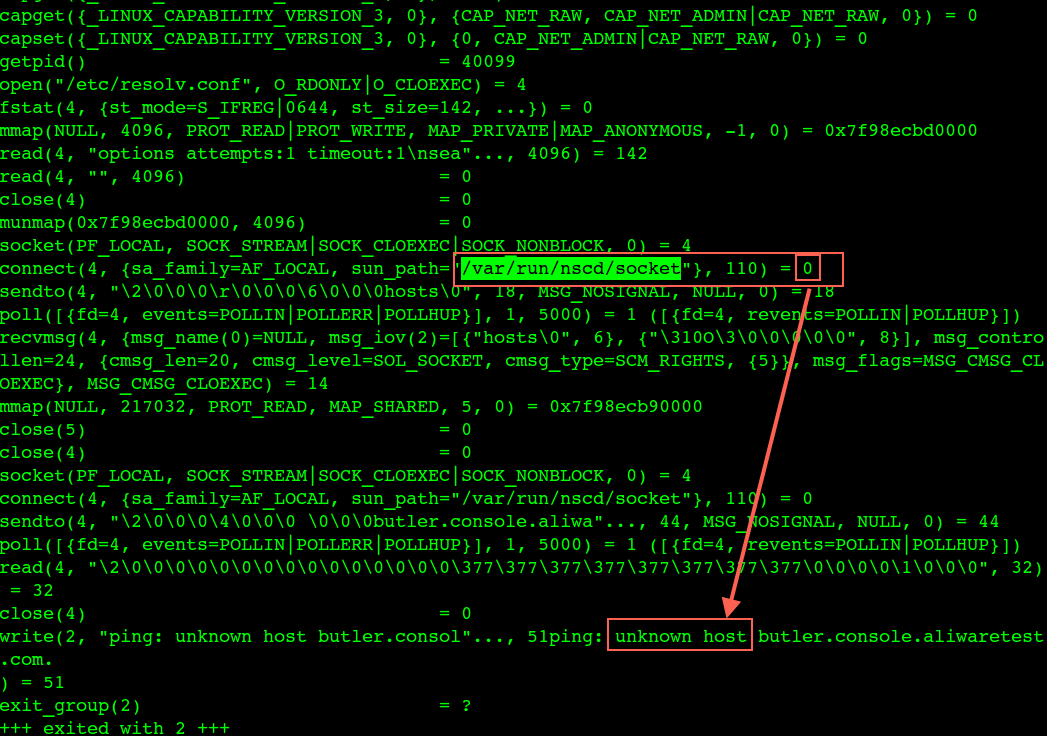
解析异常的strace栈:
1 | 不正常解析的strace日志: |
原因分析
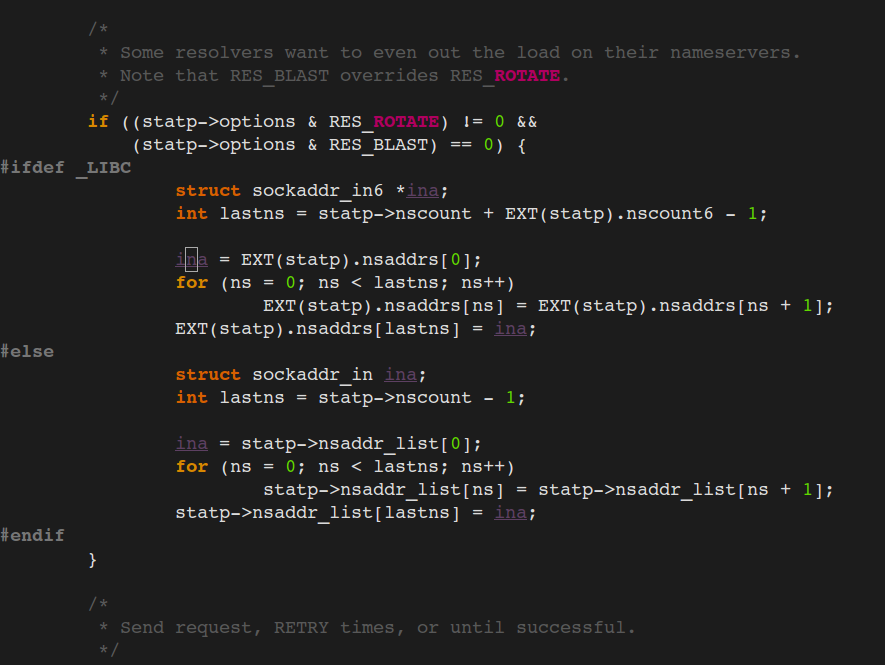
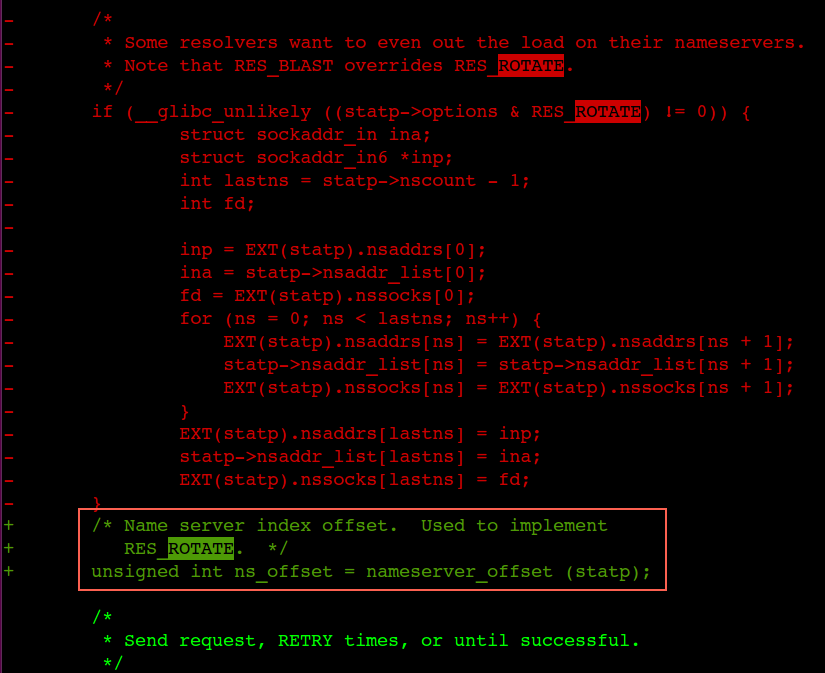
DNS client (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议, connect 时并不会发包,也就不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,send 时各自发的包它们源 Port 相同(因为用的同一个socket发送),当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 kube-dns 或 coredns 都是访问的CLUSTER-IP,报文最终会被 DNAT 成一个 endpoint 的 POD IP,当两个包恰好又被 DNAT 成同一个 POD IP时,它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,而single-request-reopen的选项设置为俩请求被丢了一个,会等待超时再重发 ,这个就解释了为什么还存在调整成2s就是2s的异常比较多 ,因此这种场景下调整成single-request是比较好的方式,同时k8s那边给的dns缓存方案是 nodelocaldns组件可以考虑用一下
关于recolv的选项
1 | single-request (since glibc 2.10) 串行解析, |
getaddrinfo 关闭ipv6的解析
基本上所有测试下来,网上那些通过修改配置的基本都不能关闭ipv6的解析,只有通过在代码中指定
hints.ai_family = AF_INET; /* or AF_INET6 for ipv6 addresses */
来只做ipv4的解析
Prefer A (IPv4) DNS lookups before AAAA(IPv6) lookups
https://man7.org/linux/man-pages/man3/getaddrinfo.3.html:
1 | If hints.ai_flags includes the AI_ADDRCONFIG flag, then IPv4 |
1 | struct addrinfo hints, *result; |
or
In the Wireshark capture, 172.25.50.3 is the local DNS resolver; the capture was taken there, so you also see its outgoing queries and responses. Note that only an A record was requested. No AAAA lookup was ever done.
1 | #include <sys/types.h> |
or:https://unix.stackexchange.com/questions/9940/convince-apt-get-not-to-use-ipv6-method
/etc/gai.conf getaddrinfo的配置文件
| Prefix | Precedence | Label | Usage |
|---|---|---|---|
| ::1/128 | 50 | 0 | Localhost |
| ::/0 | 40 | 1 | Default unicast |
| ::ffff:0:0/96 | 35 | 4 | IPv4-mapped IPv6 address |
| 2002::/16 | 30 | 2 | 6to4 |
| 2001::/32 | 5 | 5 | Teredo tunneling |
| fc00::/7 | 3 | 13 | Unique local address |
| ::/96 | 1 | 3 | IPv4-compatible addresses (deprecated) |
| fec0::/10 | 1 | 11 | Site-local address (deprecated) |
| 3ffe::/16 | 1 | 12 | 6bone (returned) |
来源于维基百科
0:0:0:0:0:ffff:0:0/96 10 4 IPv4映射地址(这个地址网络上信息较少,地址范围::: ffff:0.0.0.0~:: ffff:255.255.255.255 地址数量2 128−96 = 2 32 = 4 294 967 296,用于软件,目的是IPv4映射的地址。 )