就是要你懂TCP–TCP性能问题 先通过一个案例来看TCP 性能点
案例描述 某个PHP服务通过Nginx将后面的redis封装了一下,让其他应用可以通过http协议访问Nginx来get、set 操作redis
上线后测试一切正常,每次操作几毫秒. 但是有个应用的value是300K,这个时候set一次需要300毫秒以上。 在没有任何并发压力单线程单次操作也需要这么久,这个操作需要这么久是不合理和无法接受的。
问题的原因 因为TCP协议为了对带宽利用率、性能方面优化,而做了一些特殊处理。比如Delay Ack和Nagle算法。
这个原因对大家理解TCP基本的概念后能在实战中了解一些TCP其它方面的性能和影响。
什么是delay ack 由我前面的TCP介绍文章大家都知道,TCP是可靠传输,可靠的核心是收到包后回复一个ack来告诉对方收到了。
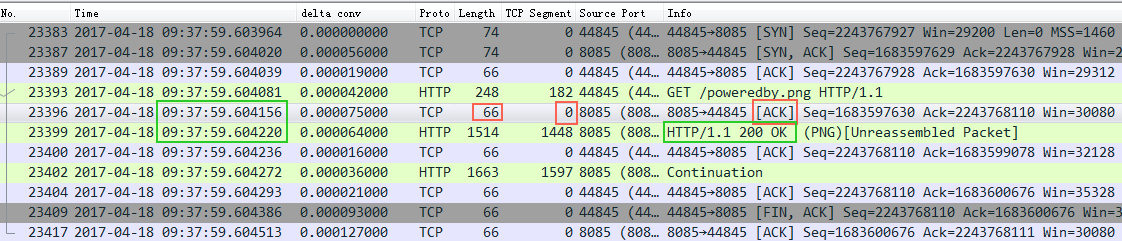
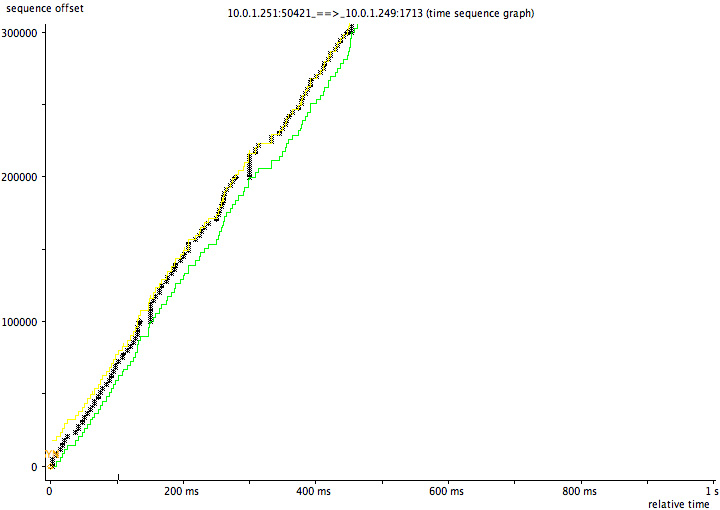
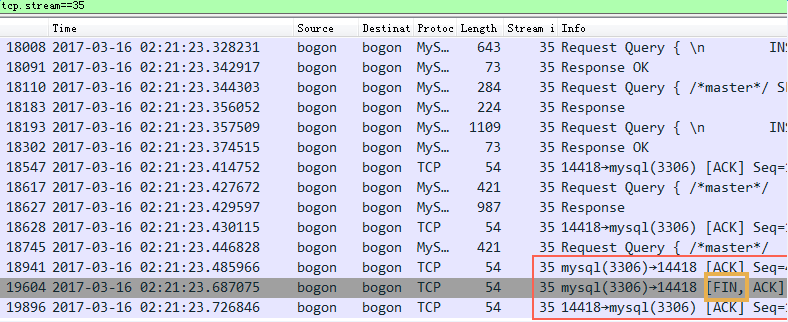
来看一个例子:
截图中的Nignx(8085端口),收到了一个http request请求,然后立即回复了一个ack包给client,接着又回复了一个http response 给client。大家注意回复的ack包长度66,实际内容长度为0,ack信息放在TCP包头里面,也就是这里发了一个66字节的空包给客户端来告诉客户端我收到你的请求了。
这里没毛病,逻辑很对,符合TCP的核心可靠传输的意义。但是带来的一个问题是:性能不够好(用了一个空包用于特意回复ack,有点浪费)。那能不能优化呢?
这里的优化方法就是delay ack。
**delay ack **是指收到包后不立即ack,而是等一小会(比如40毫秒)看看,如果这40毫秒内有其它包(比如上面的http response)要发给client,那么这个ack包就跟着发过去(顺风车,http reponse包不需要增加任何大小和包的数量),这样节省了资源。 当然如果超过这个时间还没有包发给client(比如nginx处理需要 40毫秒以上),那么这个ack也要发给client了(即使为空,要不client以为丢包了,又要重发http request,划不来)。
假如这个时候ack包还在等待延迟发送的时候,又收到了client的一个包,那么这个时候server有两个ack包要回复,那么os会把这两个ack包合起来立即 回复一个ack包给client,告诉client前两个包都收到了。
也就是delay ack开启的情况下:ack包有顺风车就搭;如果凑两个ack包那么包个车也立即发车;再如果等了40毫秒以上也没顺风车或者拼车的,那么自己打个专车也要发车。
截图中Nginx没有开delay ack ,所以你看红框中的ack是完全可以跟着绿框(http response)一起发给client的,但是没有,红框的ack立即打车跑了
什么是Nagle算法 下面的伪代码就是Nagle算法的基本逻辑,摘自wiki :
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
这段代码的意思是如果接收窗口大于MSS 并且 要发送的数据大于 MSS的话,立即发送。
我总结下Nagle算法逻辑就是:如果发送的包很小(不足MSS),又有包发给了对方对方还没回复说收到了,那我也不急着发,等前面的包回复收到了再发。这样可以优化带宽利用率(早些年带宽资源还是很宝贵的),Nagle算法也是用来优化改进tcp传输效率的。
如果client启用Nagle,并且server端启用了delay ack会有什么后果呢? 假如client要发送一个http请求给server,这个请求有1600个bytes,通过握手协商好的MSS是1460,那么这1600个bytes就会分成2个TCP包,第一个包1460,剩下的140bytes放在第二个包。第一个包发出去后,server收到第一个包,因为delay ack所以没有回复ack,同时因为server没有收全这个HTTP请求,所以也没法回复HTTP response(server的应用层在等一个完整的HTTP请求然后才能回复,或者TCP层在等超过40毫秒的delay时间)。client这边开启了Nagle算法(默认开启)第二个包比较小(140<MSS),第一个包的ack还没有回来,那么第二个包就不发了,等!互相等 !一直到Delay Ack的Delay时间到了!
这就是悲剧的核心原因。
再来看一个经典例子和数据分析 这个案例的原始出处
案例核心奇怪的现象是:
如果传输的数据是 99,900 bytes,速度5.2M/秒;
如果传输的数据是 100,000 bytes 速度2.7M/秒,多了10个bytes,不至于传输速度差这么多。
原因就是:
99,900 bytes = 68 full-sized 1448-byte packets, plus 1436 bytes extra
100,000 bytes = 69 full-sized 1448-byte packets, plus 88 bytes extra
99,900 bytes:
68个整包会立即发送(都是整包,不受Nagle算法的影响),因为68是偶数,对方收到最后两个包后立即回复ack(delay ack凑够两个也立即ack),那么剩下的1436也很快发出去(根据Nagle算法,没有没ack的包了,立即发)
100,000 bytes:
前面68个整包很快发出去也收到ack回复了,然后发了第69个整包,剩下88bytes(不够一个整包)根据Nagle算法要等一等,server收到第69个ack后,因为delay ack不回复(手里只攒下一个没有回复的包),所以client、server两边等在等,一直等到server的delay ack超时了。
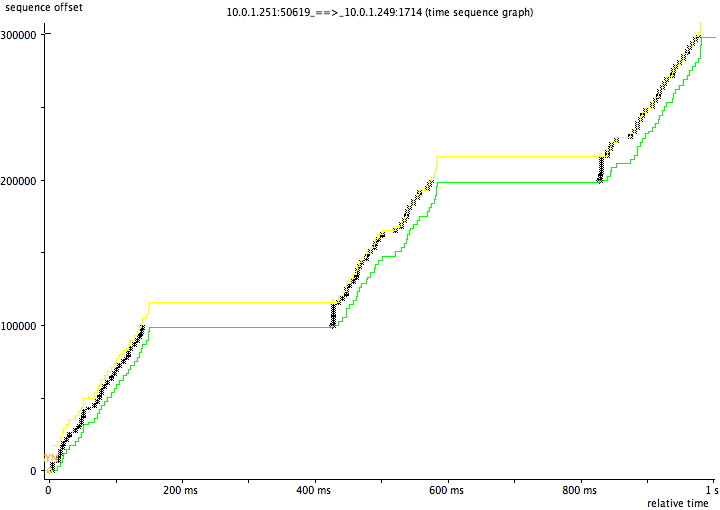
挺奇怪和挺有意思吧,作者还给出了传输数据的图表:
这是有问题的传输图,明显有个平台层,这个平台层就是两边在互相等,整个速度肯定就上不去。
如果传输的都是99,900,那么整个图形就很平整:
回到前面的问题 服务写好后,开始测试都没有问题,rt很正常(一般测试的都是小对象),没有触发这个问题。后来碰到一个300K的rt就到几百毫秒了,就是因为这个原因。
另外有些http post会故意把包头和包内容分成两个包,再加一个Expect 参数之类的,更容易触发这个问题。
这是修改后的C代码
struct curl_slist *list = NULL;
//合并post包
list = curl_slist_append(list, "Expect:");
CURLcode code(CURLE_FAILED_INIT);
if (CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_URL, oss.str().c_str())) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_TIMEOUT_MS, timeout)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, &write_callback)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_VERBOSE, 1L)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_POST, 1L)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_POSTFIELDSIZE, pooh.sizeleft)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_READFUNCTION, read_callback)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_READDATA, &pooh)) &&
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_NOSIGNAL, 1L)) && //1000 ms curl bug
CURLE_OK == (code = curl_easy_setopt(curl, CURLOPT_HTTPHEADER, list))
) {
//这里如果是小包就不开delay ack,实际不科学
if (request.size() < 1024) {
code = curl_easy_setopt(curl, CURLOPT_TCP_NODELAY, 1L);
} else {
code = curl_easy_setopt(curl, CURLOPT_TCP_NODELAY, 0L);
}
if(CURLE_OK == code) {
code = curl_easy_perform(curl);
}
上面中文注释的部分是后来的改进,然后经过测试同一个300K的对象也能在几毫秒以内完成get、set了。
尤其是在 Post请求将HTTP Header 和Body内容分成两个包后,容易出现这种延迟问题。
一些概念和其它会导致TCP性能差的原因 跟速度相关的几个概念
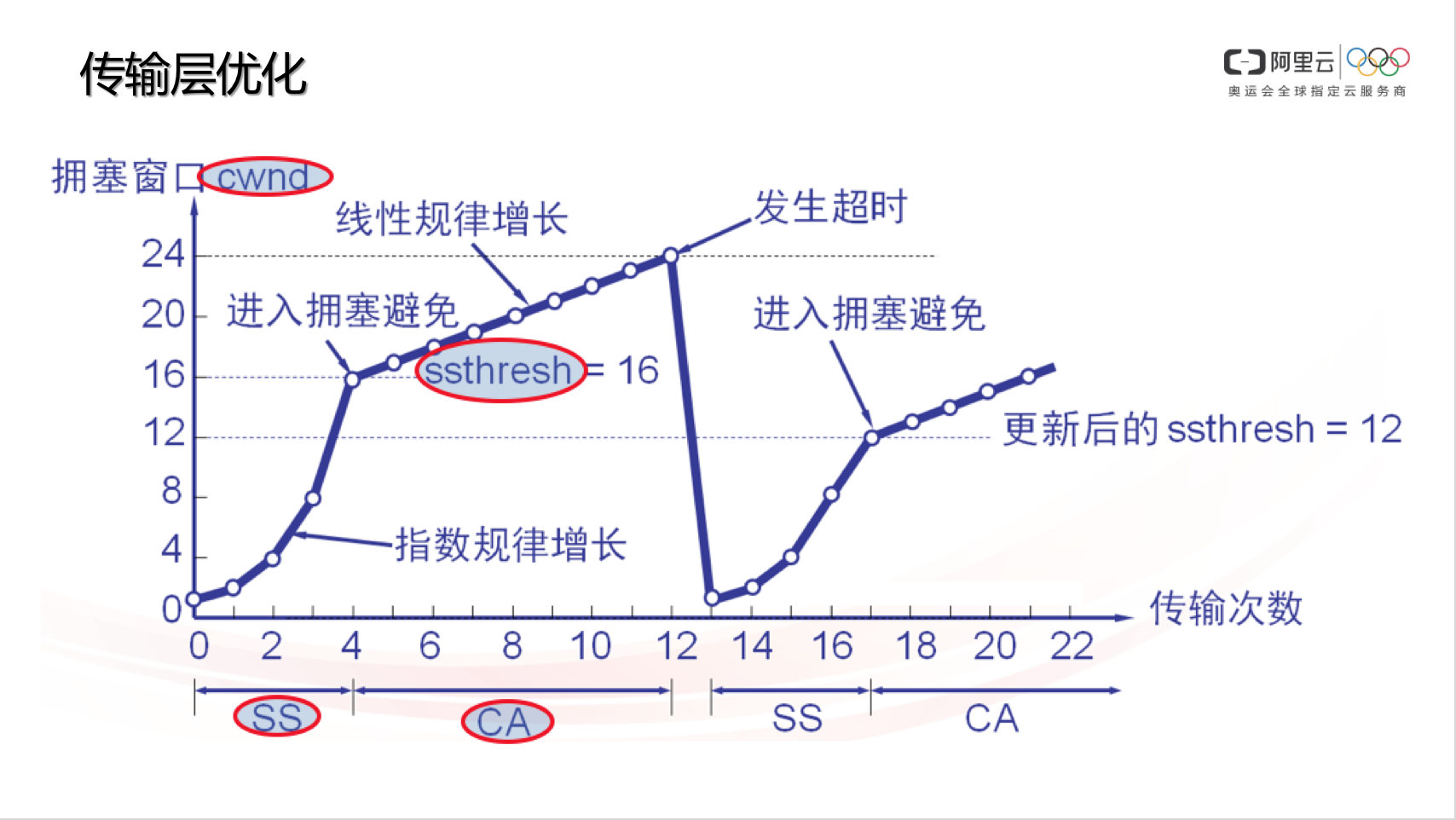
CWND:Congestion Window,拥塞窗口,负责控制单位时间内,数据发送端的报文发送量。TCP 协议规定,一个 RTT(Round-Trip Time,往返时延,大家常说的 ping 值)时间内,数据发送端只能发送 CWND 个数据包(注意不是字节数)。TCP 协议利用 CWND/RTT 来控制速度。这个值是根据丢包动态计算出来的
SS:Slow Start,慢启动阶段。TCP 刚开始传输的时候,速度是慢慢涨起来的,除非遇到丢包,否则速度会一直指数性增长(标准 TCP 协议的拥塞控制算法,例如 cubic 就是如此。很多其它拥塞控制算法或其它厂商可能修改过慢启动增长特性,未必符合指数特性)。
CA:Congestion Avoid,拥塞避免阶段。当 TCP 数据发送方感知到有丢包后,会降低 CWND,此时速度会下降,CWND 再次增长时,不再像 SS 那样指数增,而是线性增(同理,标准 TCP 协议的拥塞控制算法,例如 cubic 是这样,很多其它拥塞控制算法或其它厂商可能修改过慢启动增长特性,未必符合这个特性)。
ssthresh:Slow Start Threshold,慢启动阈值。当数据发送方感知到丢包时,会记录此时的 CWND,并计算合理的 ssthresh 值(ssthresh <= 丢包时的 CWND),当 CWND 重新由小至大增长,直到 sshtresh 时,不再 SS 而是 CA。但因为数据确认超时(数据发送端始终收不到对端的接收确认报文),发送端会骤降 CWND 到最初始的状态。
tcp_wmem 对应send buffer,也就是滑动窗口大小
上图一旦发生丢包,cwnd降到1 ssthresh降到cwnd/2,一夜回到解放前,太保守了,实际大多情况下都是公网带宽还有空余但是链路过长,非带宽不够丢包概率增大,对此没必要这么保守(tcp诞生的背景主要针对局域网、双绞线来设计,偏保守)。RTT越大的网络环境(长肥管道)这个问题越是严重,表现就是传输速度抖动非常厉害。
所以改进的拥塞算法一旦发现丢包,cwnd和ssthresh降到原来的cwnd的一半。
TCP性能优化点
建连优化:TCP 在建立连接时,如果丢包,会进入重试,重试时间是 1s、2s、4s、8s 的指数递增间隔,缩短定时器可以让 TCP 在丢包环境建连时间更快,非常适用于高并发短连接的业务场景。
首包优化:此优化其实没什么实质意义,若要说一定会有意义的话,可能就是满足一些评测标准的需要吧,例如有些客户以首包时间作为性能评判的一个依据。所谓首包时间,简单解释就是从 HTTP Client 发出 GET 请求开始计时,到收到 HTTP 响应的时间。为此,Server 端可以通过 TCP_NODELAY 让服务器先吐出 HTTP 头,再吐出实际内容(分包发送,原本是粘到一起的),来进行提速和优化。据说更有甚者先让服务器无条件返回 “HTTP/“ 这几个字符,然后再去 upstream 拿数据。这种做法在真实场景中没有任何帮助,只能欺骗一下探测者罢了,因此还没见过有直接发 “HTTP/“ 的,其实是一种作弊行为。
平滑发包:如前文所述,在 RTT 内均匀发包,规避微分时间内的流量突发,尽量避免瞬间拥塞,此处不再赘述。
丢包预判:有些网络的丢包是有规律性的,例如每隔一段时间出现一次丢包,例如每次丢包都连续丢几个等,如果程序能自动发现这个规律(有些不明显),就可以针对性提前多发数据,减少重传时间、提高有效发包率。
RTO 探测:如前文讲 TCP 基础时说过的,若始终收不到 ACK 报文,则需要触发 RTO 定时器。RTO 定时器一般都时间非常长,会浪费很多等待时间,而且一旦 RTO,CWND 就会骤降(标准 TCP),因此利用 Probe 提前与 RTO 去试探,可以规避由于 ACK 报文丢失而导致的速度下降问题。
带宽评估:通过单位时间内收到的 ACK 或 SACK 信息可以得知客户端有效接收速率,通过这个速率可以更合理的控制发包速度。
带宽争抢:有些场景(例如合租)是大家互相挤占带宽的,假如你和室友各 1Mbps 的速度看电影,会把 2Mbps 出口占满,而如果一共有 3 个人看,则每人只能分到 1/3。若此时你的流量流量达到 2Mbps,而他俩还都是 1Mbps,则你至少仍可以分到 2/(2+1+1) * 2Mbps = 1Mbps 的 50% 的带宽,甚至更多,代价就是服务器侧的出口流量加大,增加成本。(TCP 优化的本质就是用带宽换用户体验感)
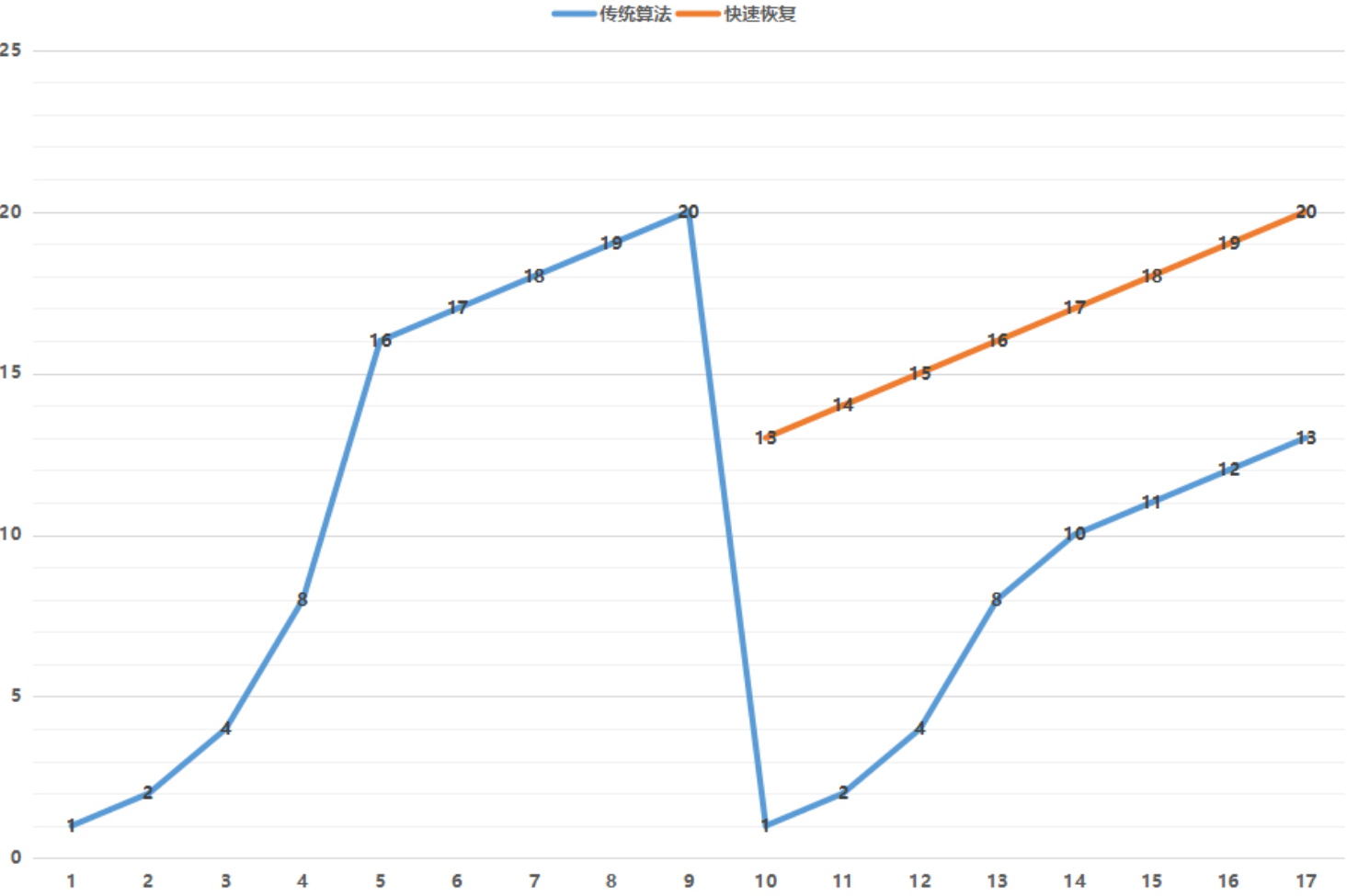
链路质量记忆 (后面有反面案例):如果一个 Client IP 或一个 C 段 Network,若已经得知了网络质量规律(例如 CWND 多大合适,丢包规律是怎样的等),就可以在下次连接时,优先使用历史经验值,取消慢启动环节直接进入告诉发包状态,以提升客户端接收数据速率。
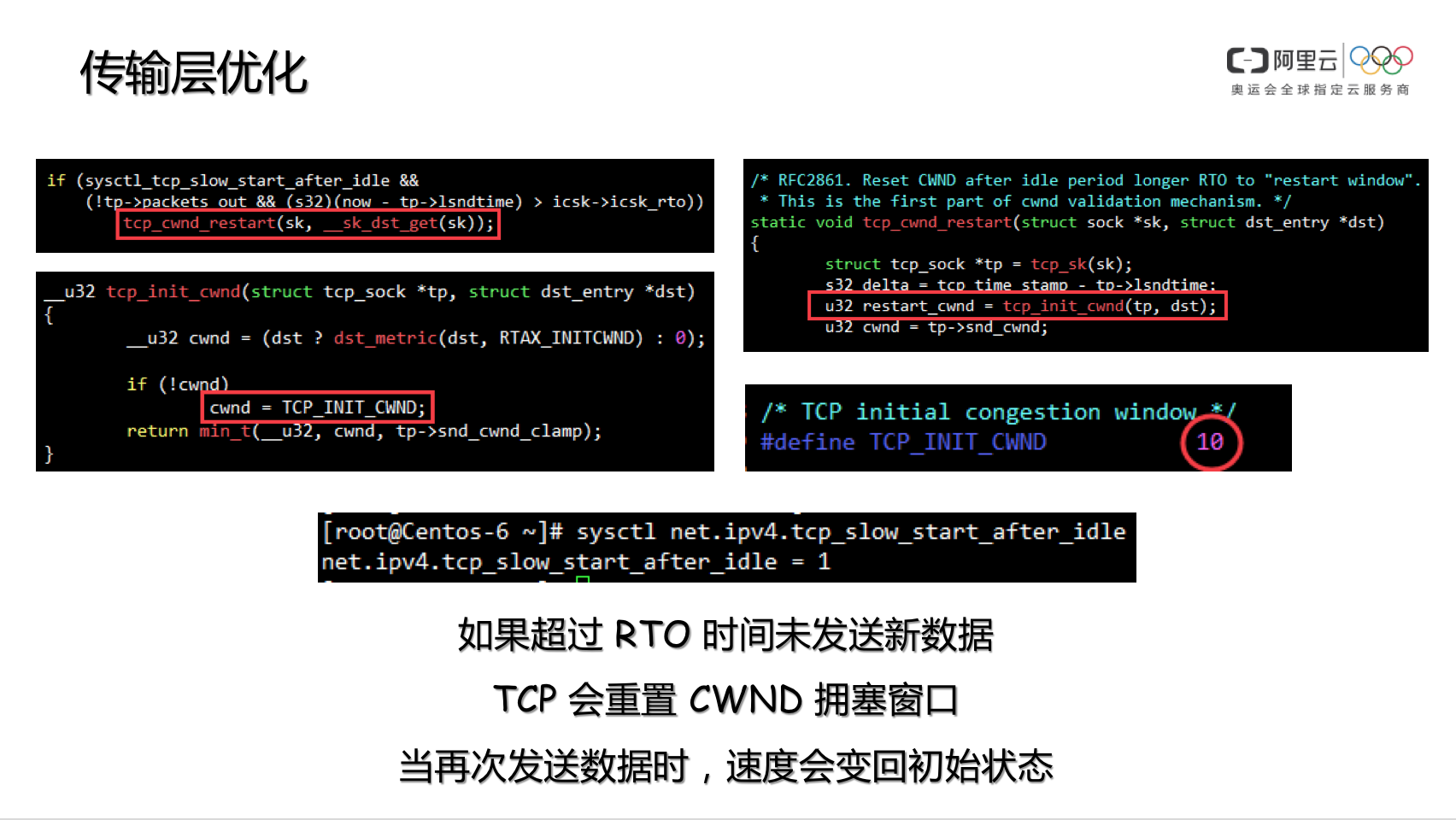
参数 net.ipv4.tcp_slow_start_after_idle 内核协议栈参数 net.ipv4.tcp_slow_start_after_idle 默认是开启的,这个参数的用途,是为了规避 CWND 无休止增长,因此在连接不断开,但一段时间不传输数据的话,就将 CWND 收敛到 initcwnd,kernel-2.6.32 是 10,kernel-2.6.18 是 2。因此在 HTTP Connection: keep-alive 的环境下,若连续两个 GET 请求之间存在一定时间间隔,则此时服务器端会降低 CWND 到初始值,当 Client 再次发起 GET 后,服务器会重新进入慢启动流程。
这种友善的保护机制,对于 CDN 来说是帮倒忙,因此我们可以通过命令将此功能关闭,以提高 HTTP Connection: keep-alive 环境下的用户体验感。
sysctl net.ipv4.tcp_slow_start_after_idle=0
运行中每个连接 CWND/ssthresh(slow start threshold) 的确认 #for i in {1..1000}; do ss -i dst 172.16.250.239:22 ; sleep 0.2; done
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
tcp ESTAB 0 2068920 192.168.99.211:43090 172.16.250.239:ssh
cubic wscale:7,7 rto:224 rtt:22.821/0.037 ato:40 mss:1448 pmtu:1500 rcvmss:1056 advmss:1448 cwnd:3004 ssthresh:3004 bytes_sent:139275001 bytes_acked:137206082 bytes_received:46033 segs_out:99114 segs_in:9398 data_segs_out:99102 data_segs_in:1203 send 1524.8Mbps lastrcv:4 pacing_rate 1829.8Mbps delivery_rate 753.9Mbps delivered:97631 app_limited busy:2024ms unacked:1472 rcv_rtt:23 rcv_space:14480 rcv_ssthresh:64088 minrtt:22.724
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
tcp ESTAB 0 2036080 192.168.99.211:43090 172.16.250.239:ssh
cubic wscale:7,7 rto:224 rtt:22.814/0.022 ato:40 mss:1448 pmtu:1500 rcvmss:1056 advmss:1448 cwnd:3004 ssthresh:3004 bytes_sent:157304161 bytes_acked:155284502 bytes_received:51685 segs_out:111955 segs_in:10597 data_segs_out:111943 data_segs_in:1360 send 1525.3Mbps pacing_rate 1830.3Mbps delivery_rate 745.7Mbps delivered:110506 app_limited busy:2228ms unacked:1438 rcv_rtt:23 rcv_space:14480 rcv_ssthresh:64088 notsent:16420 minrtt:22.724
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
tcp ESTAB 0 1970400 192.168.99.211:43090 172.16.250.239:ssh
cubic wscale:7,7 rto:224 rtt:22.816/0.028 ato:40 mss:1448 pmtu:1500 rcvmss:1056 advmss:1448 cwnd:3004 ssthresh:3004 bytes_sent:174955661 bytes_acked:172985262 bytes_received:57229 segs_out:124507 segs_in:11775 data_segs_out:124495 data_segs_in:1514 send 1525.2Mbps pacing_rate 1830.2Mbps delivery_rate 746.7Mbps delivered:123097 app_limited busy:2432ms unacked:1399 rcv_rtt:23 rcv_space:14480 rcv_ssthresh:64088 minrtt:22.724
从系统cache中查看 tcp_metrics item $sudo ip tcp_metrics show | grep 100.118.58.7
100.118.58.7 age 1457674.290sec tw_ts 3195267888/5752641sec ago rtt 1000us rttvar 1000us ssthresh 361 cwnd 40 metric_5 8710 metric_6 4258
每个连接的ssthresh默认是个无穷大的值,但是内核会cache对端ip上次的ssthresh(大部分时候两个ip之间的拥塞窗口大小不会变),这样大概率到达ssthresh之后就基本拥塞了,然后进入cwnd的慢增长阶段。
如果因为之前的网络状况等其它原因导致tcp_metrics缓存了一个非常小的ssthresh(这个值默应该非常大),ssthresh太小的话tcp的CWND指数增长阶段很快就结束,然后进入CWND+1的慢增加阶段导致整个速度感觉很慢
清除 tcp_metrics, sudo ip tcp_metrics flush all
关闭 tcp_metrics 功能,net.ipv4.tcp_no_metrics_save = 1
sudo ip tcp_metrics delete 100.118.58.7
tcp_metrics会记录下之前已关闭TCP连接的状态,包括发送端CWND和ssthresh,如果之前网络有一段时间比较差或者丢包比较严重,就会导致TCP的ssthresh降低到一个很低的值 ,这个值在连接结束后会被tcp_metrics cache 住,在新连接建立时,即使网络状况已经恢复,依然会继承 tcp_metrics 中cache 的一个很低的ssthresh 值。
对于rt很高的网络环境,新连接经历短暂的“慢启动”后(ssthresh太小),随即进入缓慢的拥塞控制阶段(rt太高,CWND增长太慢),导致连接速度很难在短时间内上去。而后面的连接,需要很特殊的场景之下(比如,传输一个很大的文件)才能将ssthresh 再次推到一个比较高的值更新掉之前的缓存值,因此很有很能在接下来的很长一段时间,连接的速度都会处于一个很低的水平。
ssthresh 是如何降低的 在网络情况较差,并且出现连续dup ack情况下,ssthresh 会设置为 cwnd/2, cwnd 设置为当前值的一半,
ssthresh 降低后为何长时间不恢复正常 ssthresh 降低之后需要在检测到有丢包的之后才会变动,因此就需要机缘巧合才会增长到一个比较大的值。
也就是如果ssthresh 降低之后,需要传一个非常大的文件,并且网络状况超级好一直不丢包,这样能让CWND一直慢慢稳定增长,一直到CWND达到带宽的限制后出现丢包,这个时候CWND和ssthresh降到CWND的一半那么新的比较大的ssthresh值就能被缓存下来了。
tcp windows scale 网络传输速度:单位时间内(一个 RTT)发送量(再折算到每秒),不是 CWND(Congestion Window 拥塞窗口),而是 min(CWND, RWND)。除了数据发送端有个 CWND 以外,数据接收端还有个 RWND(Receive Window,接收窗口)。在带宽不是瓶颈的情况下,单连接上的速度极限为 MIN(cwnd, slide_windows)*1000ms/rt
1 2 #修改初始拥塞窗口 sudo ip route change default via ip dev eth0 proto dhcp src ip metric 100 initcwnd 20
tcp windows scale用来协商RWND的大小,它在tcp协议中占16个位,如果通讯双方有一方不支持tcp windows scale的话,TCP Windows size 最大只能到2^16 = 65535 也就是64k
如果网络rt是35ms,滑动窗口<CWND,那么单连接的传输速度最大是: 64K*1000/35=1792K(1.8M)
如果网络rt是30ms,滑动窗口>CWND的话,传输速度:CWND*1500(MTU)*1000(ms)/rt
一般通讯双方都是支持tcp windows scale的,但是如果连接中间通过了lvs,并且lvs打开了 synproxy功能的话,就会导致 tcp windows scale 无法起作用,那么传输速度就被滑动窗口限制死了(rt小的话会没那么明显 )。
RTT越大,传输速度越慢 RTT大的话导致拥塞窗口爬升缓慢,慢启动过程持续越久。RTT越大、物理带宽越大、要传输的文件越大这个问题越明显
RTT对性能的影响关键是RTT长了后丢包的概率大,一旦丢包进入拥塞阶段就很慢了。如果一直不丢包,只是RTT长,完全可以做大增加发送窗口和接收窗口来抵消RTT的增加
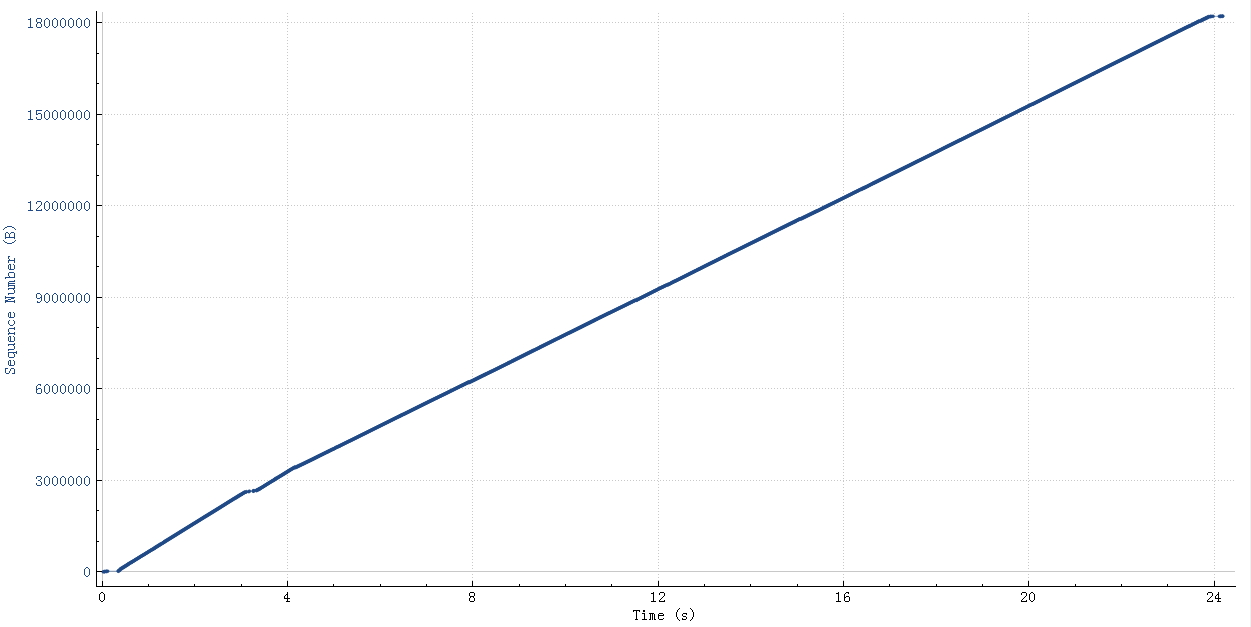
socket send/rcv buf 有些应用会默认设置 socketSendBuffer 为16K,在高rt的环境下,延时20ms,带宽100M,如果一个查询结果22M的话需要25秒
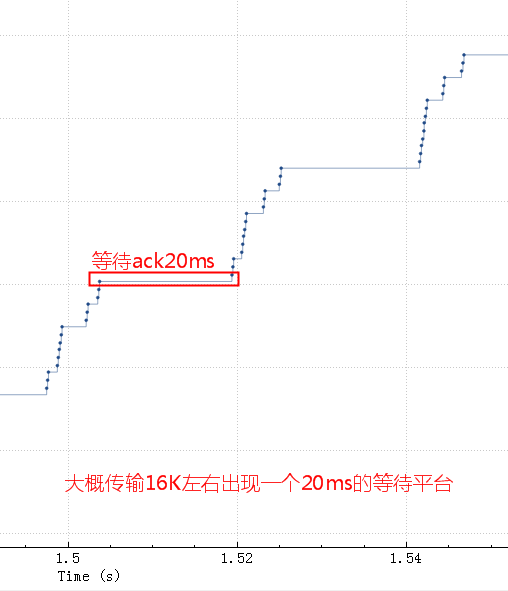
细化看下问题所在:
这个时候也就是buf中的16K数据全部发出去了,但是这16K不能立即释放出来填新的内容进去,因为tcp要保证可靠,万一中间丢包了呢。只有等到这16K中的某些ack了,才会填充一些进来然后继续发出去。由于这里rt基本是20ms,也就是16K发送完毕后,等了20ms才收到一些ack,这20ms应用、OS什么都不能做。
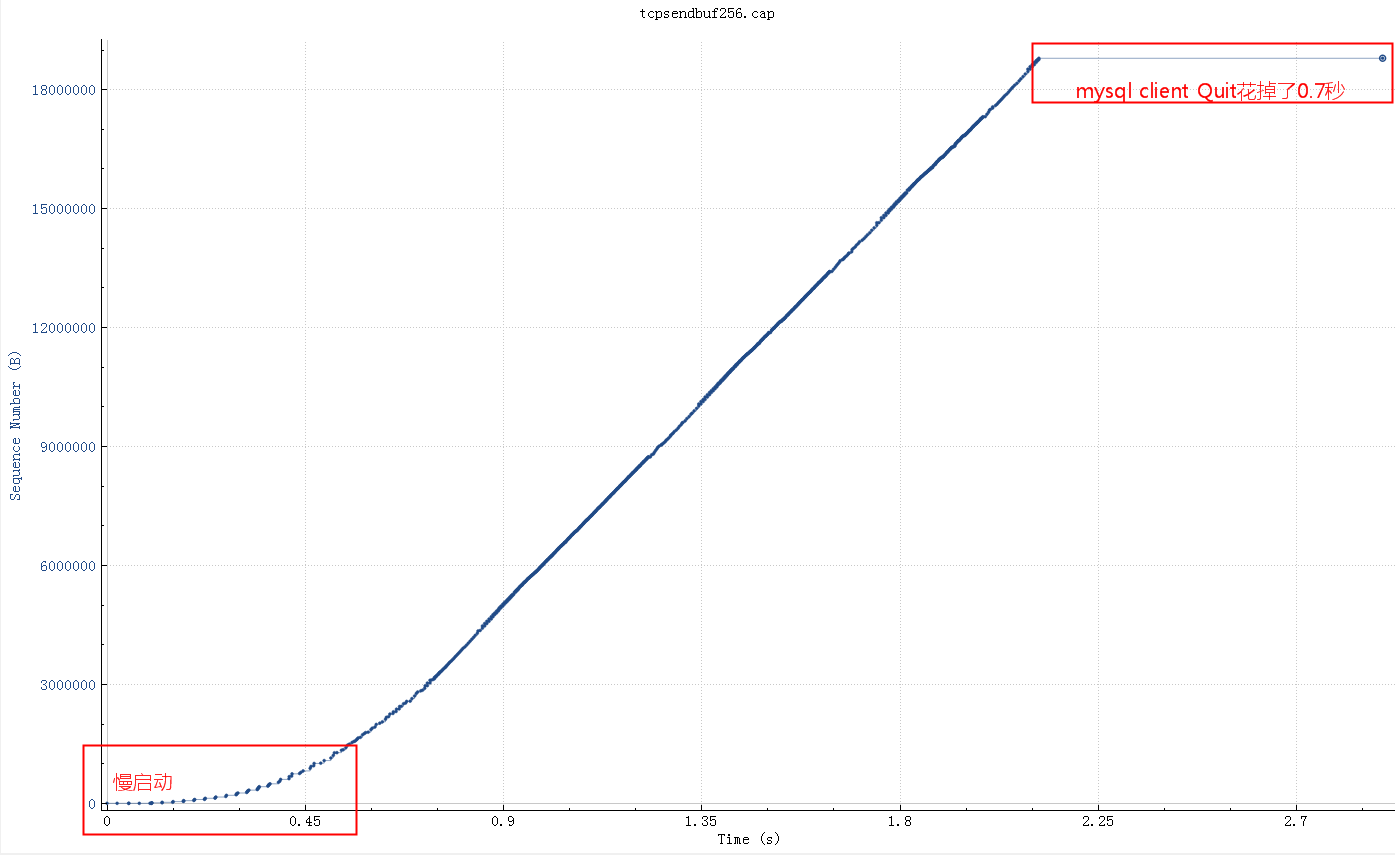
调整 socketSendBuffer 到256K,查询时间从25秒下降到了4秒多,但是比理论带宽所需要的时间略高
继续查看系统 net.core.wmem_max 参数默认最大是130K,所以即使我们代码中设置256K实际使用的也是130K,调大这个系统参数后整个网络传输时间大概2秒(跟100M带宽匹配了,scp传输22M数据也要2秒),整体查询时间2.8秒。测试用的mysql client短连接,如果代码中的是长连接的话会块300-400ms(消掉了慢启动阶段),这基本上是理论上最快速度了
$sudo sysctl -a | grep --color wmem
vm.lowmem_reserve_ratio = 256 256 32
net.core.wmem_max = 131071
net.core.wmem_default = 124928
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.udp_wmem_min = 4096
如果指定了tcp_wmem,则net.core.wmem_default被tcp_wmem的覆盖。send Buffer在tcp_wmem的最小值和最大值之间自动调节。如果调用setsockopt()设置了socket选项SO_SNDBUF,将关闭发送端缓冲的自动调节机制,tcp_wmem将被忽略,SO_SNDBUF的最大值由net.core.wmem_max限制。
默认情况下Linux系统会自动调整这个buf(net.ipv4.tcp_wmem), 也就是不推荐程序中主动去设置SO_SNDBUF,除非明确知道设置的值是最优的。
这个buf调到1M有没有帮助,从理论计算BDP(带宽时延积) 0.02秒*(100MB/8)=250Kb 所以SO_SNDBUF为256Kb的时候基本能跑满带宽了,再大实际意义也不大了。
ip route | while read p; do sudo ip route change $p initcwnd 30 ; done
就是要你懂TCP相关文章:
关于TCP 半连接队列和全连接队列
MSS和MTU导致的悲剧
双11通过网络优化提升10倍性能
就是要你懂TCP的握手和挥手
总结 影响性能的几个点:
nagle,影响主要是针对响应时间;
tcp_metrics(缓存 ssthresh), 影响主要是传输大文件时速度上不去或者上升缓慢,明明带宽还有余;
tcp windows scale(lvs介在中间,不生效,导致接受窗口非常小), 影响主要是传输大文件时速度上不去,明明带宽还有余。
Nagle这个问题确实经典,非常隐晦一般不容易碰到,碰到一次决不放过她。文中所有client、server的概念都是相对的,client也有delay ack的问题。 Nagle算法一般默认开启的。
参考文章: https://access.redhat.com/solutions/407743
http://www.stuartcheshire.org/papers/nagledelayedack/
https://en.wikipedia.org/wiki/Nagle%27s_algorithm
https://en.wikipedia.org/wiki/TCP_delayed_acknowledgment
https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
https://www.atatech.org/articles/109721
https://www.atatech.org/articles/109967
https://www.atatech.org/articles/27189
https://www.atatech.org/articles/45084
高性能网络编程7–tcp连接的内存使用