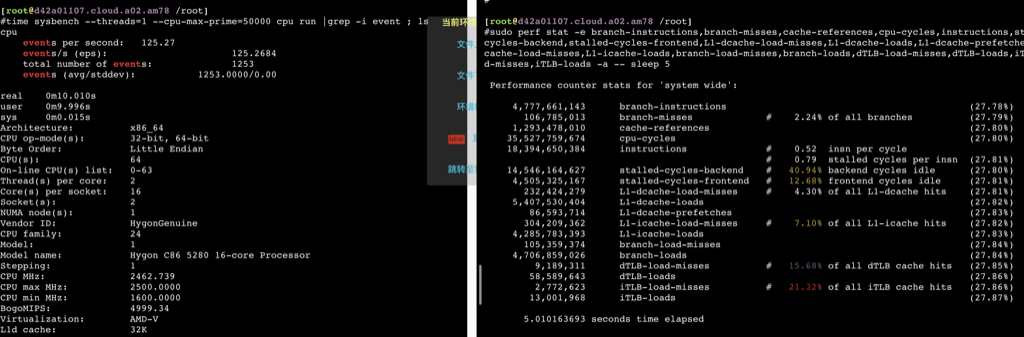
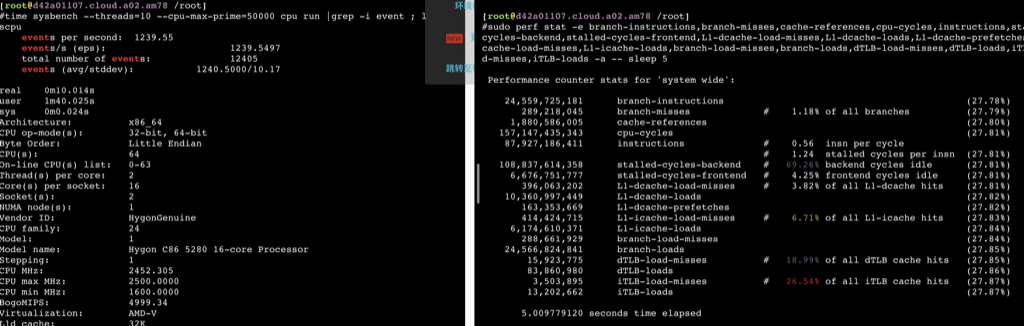
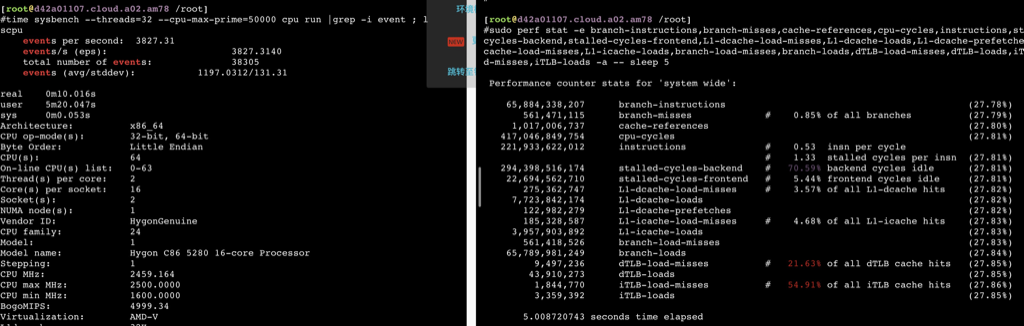
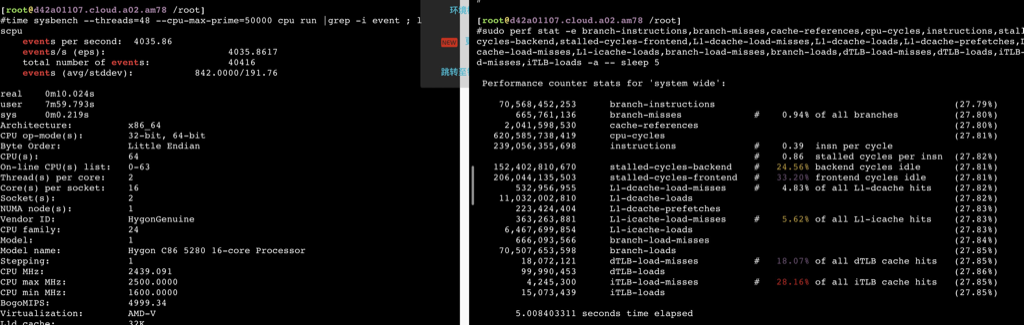
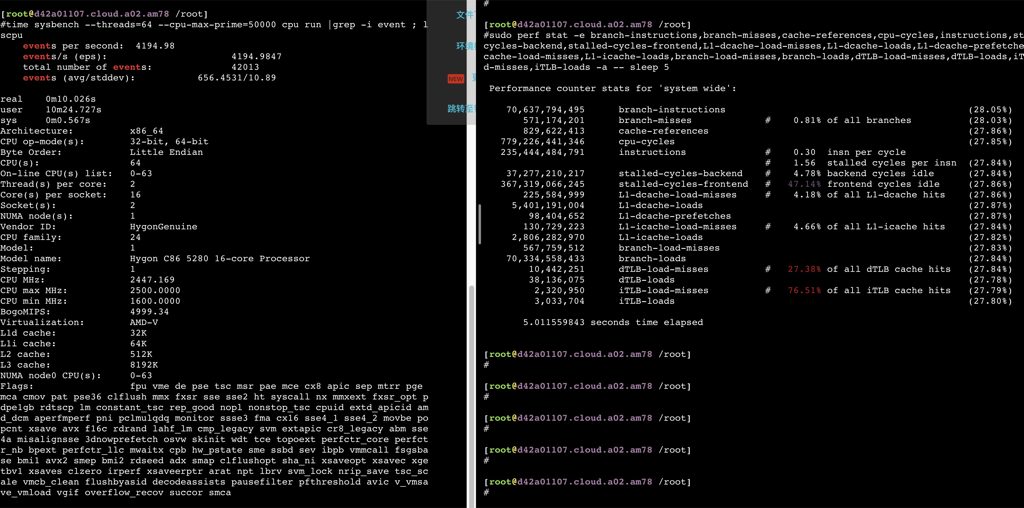
78.692839007 seconds time elapsed #dmidecode -t processor # dmidecode 3.0 Getting SMBIOS data from sysfs. SMBIOS 3.2.0 present. # SMBIOS implementations newer than version 3.0 are not # fully supported by this version of dmidecode.
Handle 0x0004, DMI type 4, 48 bytes Processor Information Socket Designation: BGA3576 Type: Central Processor Family: <OUT OF SPEC> Manufacturer: PHYTIUM ID: 00 00 00 00 70 1F 66 22 Version: S2500 Voltage: 0.8 V External Clock: 50 MHz Max Speed: 2100 MHz Current Speed: 2100 MHz Status: Populated, Enabled Upgrade: Other L1 Cache Handle: 0x0005 L2 Cache Handle: 0x0007 L3 Cache Handle: 0x0008 Serial Number: N/A Asset Tag: No Asset Tag Part Number: NULL Core Count: 64 Core Enabled: 64 Thread Count: 64 Characteristics: 64-bit capable Multi-Core Hardware Thread Execute Protection Enhanced Virtualization Power/Performance Control
#./mlc Intel(R) Memory Latency Checker - v3.9 Measuring idle latencies (in ns)... Numa node Numa node 0 0 145.8
Measuring Peak Injection Memory Bandwidths for the system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using traffic with the following read-write ratios ALL Reads : 110598.7 3:1 Reads-Writes : 93408.5 2:1 Reads-Writes : 89249.5 1:1 Reads-Writes : 64137.3 Stream-triad like: 77310.4
Measuring Memory Bandwidths between nodes within system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using Read-only traffic type Numa node Numa node 0 0 110598.4
Measuring Loaded Latencies for the system Using all the threads from each core if Hyper-threading is enabled Using Read-only traffic type Inject Latency Bandwidth Delay (ns) MB/sec ========================== 00000 506.00 111483.5 00002 505.74 112576.9 00008 505.87 112644.3 00015 508.96 112643.6 00050 574.36 112701.5 00100 501.32 112775.9 00200 475.47 112839.3 00300 224.52 91560.4 00400 194.54 70515.6 00500 185.13 57233.2 00700 178.71 41591.6 01000 170.46 29524.1 01300 165.43 22933.2 01700 164.33 17702.9 02500 164.14 12206.9
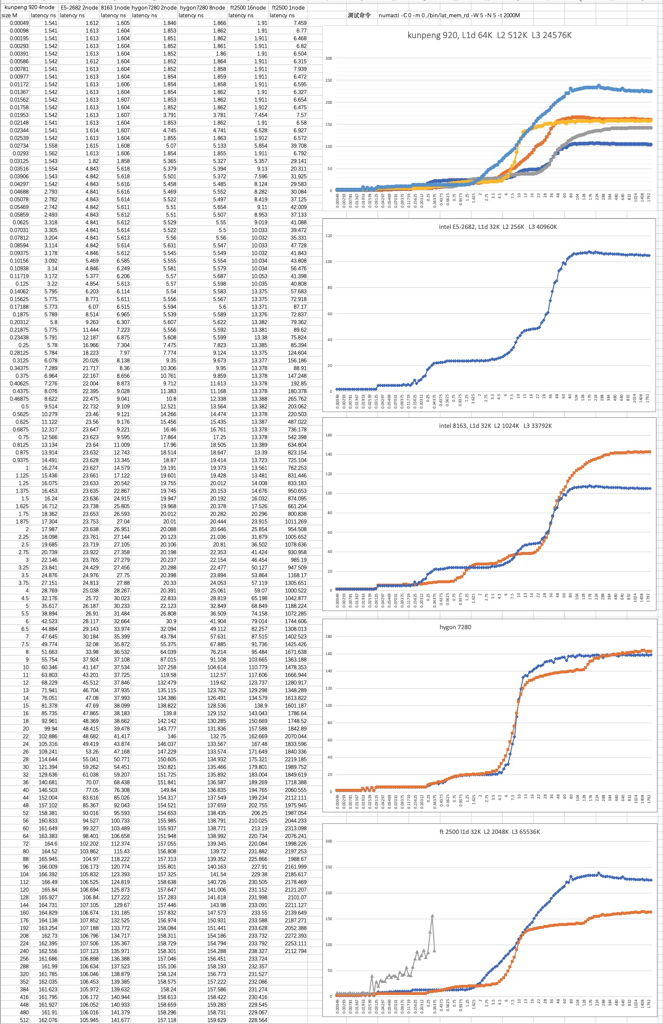
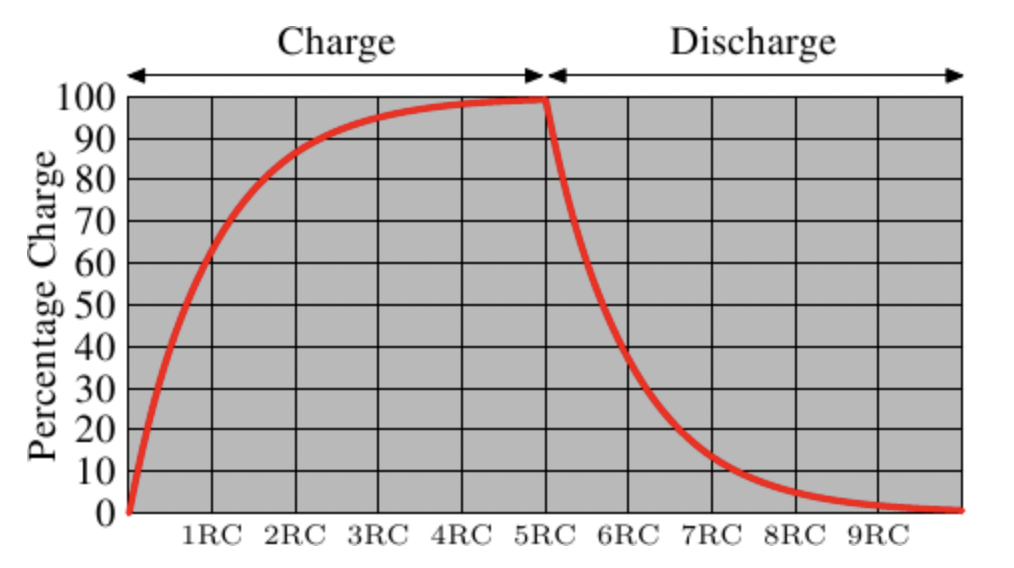
两个值都为on 时的mlc 测试结果
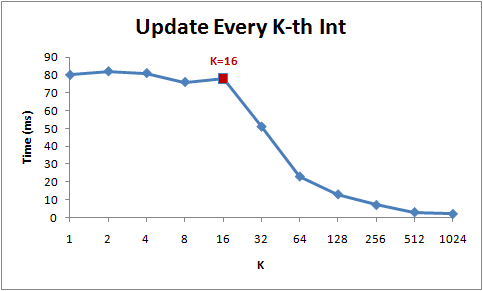
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
#./mlc Intel(R) Memory Latency Checker - v3.9 Measuring idle latencies (in ns)... Numa node Numa node 0 1 0 81.6 145.9 1 144.9 81.2
Measuring Peak Injection Memory Bandwidths for the system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using traffic with the following read-write ratios ALL Reads : 227204.2 3:1 Reads-Writes : 212432.5 2:1 Reads-Writes : 210423.3 1:1 Reads-Writes : 196677.2 Stream-triad like: 189691.4
//抓取一个子网范围 tcpdump -i bond0 port 3001 and net 1.2.3.0/24 and host not 1.2.3.211 -nn -X
//抓取 DNAT 包,tcp options 里面的 246 代表 DNAT tcpdump -nn –vvv -i eth0 tcp dst port 3306 and '(tcp[tcpflags] & (tcp-syn) != 0) and (tcp[20] =246) '
//在上面的基础上,抓取指定 vip:10.142.*.* tcpdump -nn –vvv -i eth0 tcp dst port 3306 and '(tcp[tcpflags] & (tcp-syn) != 0) and tcp[20]=246 and tcp[24]=10 and tcp[25]=142'
//抓取 DNAT 包,tcp options 里面的 252 代表 DNAT tcpdump -nn –vvv -i eth0 tcp dst port 3306 and '(tcp[tcpflags] & (tcp-ack) != 0) and (tcp[20] =252) '
//根据指定的VPC IP抓包,例如172.16.x.x tcpdump -nn –vvv -i eth0 tcp dst port 3306 and '(tcp[tcpflags] & (tcp-ack) != 0) and (tcp[32] =172) and (tcp[33] =16)'
//根据客户端IP抓包FNAT的包,例如172.16.x.x tcpdump -nn –vvv -i eth0 tcp dst port 3306 and '(tcp[tcpflags] & (tcp-ack) != 0) and(tcp[20]=252) and (tcp[24]=172) and (tcp[25]=16)'
用tcpdump抓取并保存包: sudo tcpdump -i eth0 port 3306 -w plantegg.cap
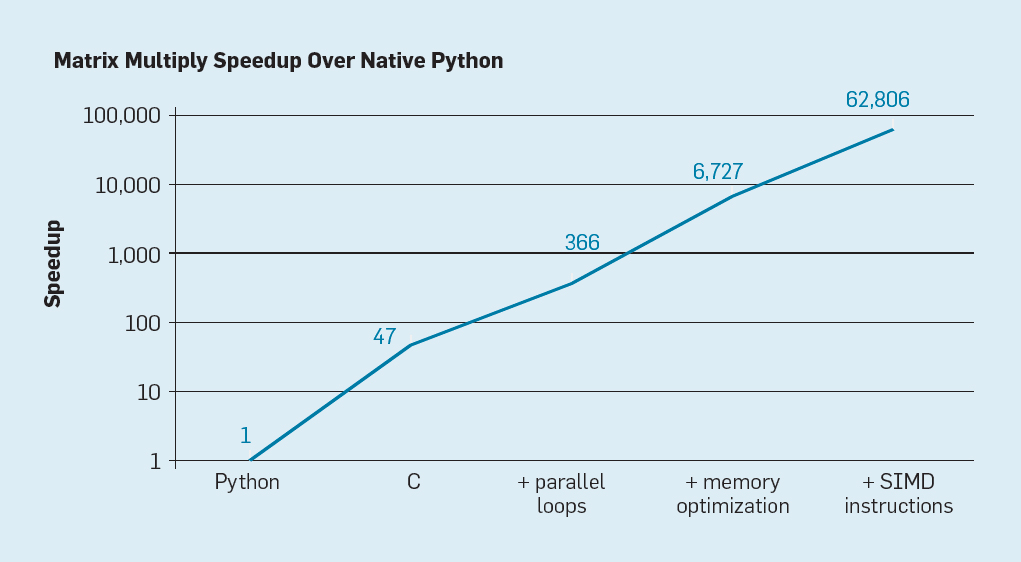
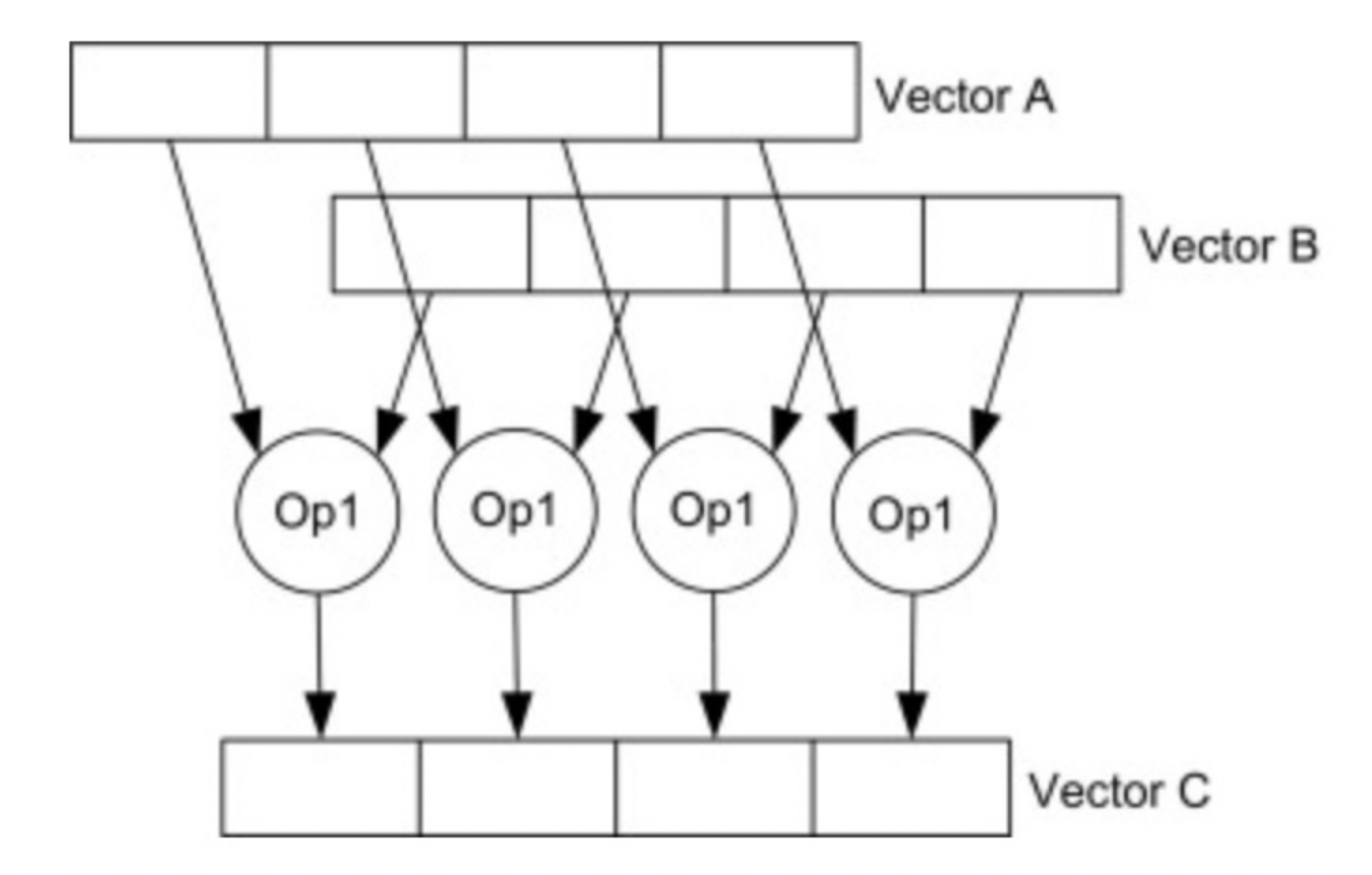
举例来说,对于一个实现两个 int 相加的 expression,在向量化之前,其实现可能是这样的:
1 2 3 4 5 6 7
classExpressionIntAdd extends Expression { Datum eval(Row input){ int left = input.getInt(leftIndex); int right = input.getInt(rightIndex); returnnewDatum(left+right); } }
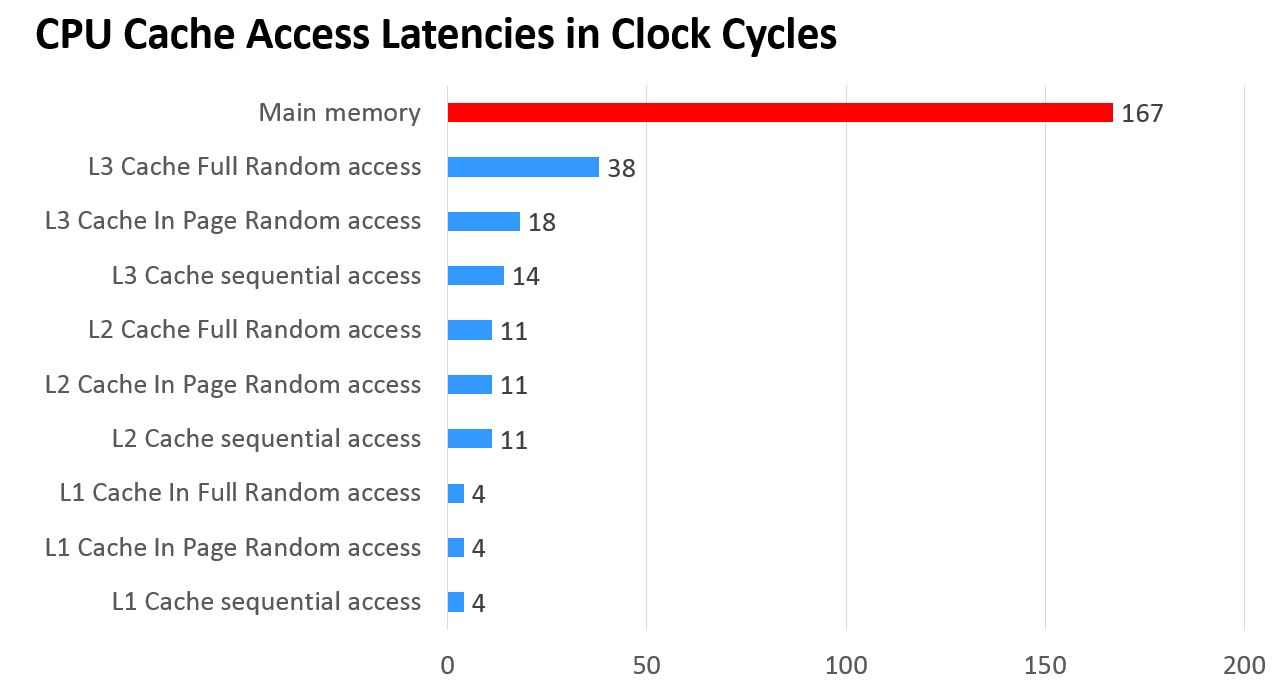
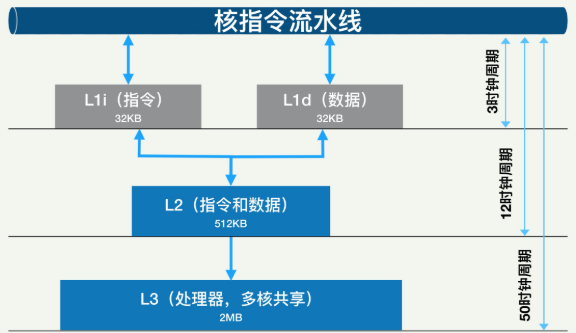
EXEC : instructions per nominal CPU cycle IPC : instructions per CPU cycle FREQ : relation to nominal CPU frequency='unhalted clock ticks'/'invariant timer ticks' (includes Intel Turbo Boost) AFREQ : relation to nominal CPU frequency while in active state (not in power-saving C state)='unhalted clock ticks'/'invariant timer ticks while in C0-state' (includes Intel Turbo Boost) L3MISS: L3 (read) cache misses L3MPKI: L3 misses per kilo instructions L3HIT : L3 (read) cache hit ratio (0.00-1.00) L2DMISS:L2 data cache misses L2DHIT :L2 data cache hit ratio (0.00-1.00) L2DMPKI:number of L2 data cache misses per kilo instruction L2IMISS:L2 instruction cache misses L2IHIT :L2 instructoon cache hit ratio (0.00-1.00) L2IMPKI:number of L2 instruction cache misses per kilo instruction L2MPKI :number of both L2 instruction and data cache misses per kilo instruction
--------------------------------------------------------------------------------------------------------------- TOTAL * 1.29 1.20 1.08 1.00 12 M 0.73 0.04 10 M 0.87 0.03 0.07 19 M 0.00 0.55 N/A
Instructions retired: 336 G ; Active cycles: 281 G ; Time (TSC): 2082 Mticks ; C0 (active,non-halted) core residency: 107.90 %
PHYSICAL CORE IPC : 2.39 => corresponds to 34.14 % utilization for cores in active state Instructions per nominal CPU cycle: 2.58 => corresponds to 36.84 % core utilization over time interval ---------------------------------------------------------------------------------------------------------------
EXEC : instructions per nominal CPU cycle IPC : instructions per CPU cycle FREQ : relation to nominal CPU frequency='unhalted clock ticks'/'invariant timer ticks' (includes Intel Turbo Boost) AFREQ : relation to nominal CPU frequency while in active state (not in power-saving C state)='unhalted clock ticks'/'invariant timer ticks while in C0-state' (includes Intel Turbo Boost) L3MISS: L3 (read) cache misses L3MPKI: L3 misses per kilo instructions L3HIT : L3 (read) cache hit ratio (0.00-1.00) L2DMISS:L2 data cache misses L2DHIT :L2 data cache hit ratio (0.00-1.00) L2DMPKI:number of L2 data cache misses per kilo instruction L2IMISS:L2 instruction cache misses L2IHIT :L2 instructoon cache hit ratio (0.00-1.00) L2IMPKI:number of L2 instruction cache misses per kilo instruction L2MPKI :number of both L2 instruction and data cache misses per kilo instruction
0 0 1.34 1.26 1.06 1.00 8901 K 0.72 3.15 15 M 0.68 5.43 8.58 71 M 4.00 0.60 N/A 1 0 1.42 1.33 1.06 1.00 8491 K 0.73 2.83 14 M 0.68 4.67 7.50 71 M 4.00 0.60 N/A 2 0 1.41 1.33 1.06 1.00 8206 K 0.74 2.75 12 M 0.72 4.25 7.00 71 M 4.00 0.60 N/A 3 0 1.46 1.38 1.06 1.00 7464 K 0.75 2.40 11 M 0.68 3.81 6.21 71 M 4.00 0.60 N/A 4 0 1.31 1.24 1.06 1.00 9118 K 0.71 3.28 15 M 0.69 5.61 8.88 70 M 4.00 0.61 N/A 5 0 1.41 1.33 1.06 1.00 8700 K 0.74 2.92 13 M 0.69 4.66 7.57 70 M 4.00 0.61 N/A 6 0 1.41 1.33 1.06 1.00 8094 K 0.74 2.79 12 M 0.70 4.40 7.18 70 M 4.00 0.61 N/A 7 0 1.43 1.35 1.06 1.00 7873 K 0.74 2.68 12 M 0.71 4.13 6.81 70 M 4.00 0.61 N/A 8 0 1.44 1.36 1.06 1.00 8544 K 0.73 2.79 14 M 0.67 4.87 7.66 20 M 1.00 0.61 N/A 9 0 1.24 1.16 1.06 1.00 524 K 0.51 0.21 86 K 0.94 0.03 0.24 20 M 1.00 0.61 N/A 10 0 1.26 1.18 1.07 1.00 379 K 0.50 0.15 60 K 0.95 0.02 0.17 20 M 1.00 0.61 N/A 11 0 1.24 1.16 1.07 1.00 533 K 0.50 0.20 96 K 0.94 0.04 0.24 20 M 1.00 0.61 N/A 12 0 1.22 1.14 1.07 1.00 1180 K 0.34 0.47 98 K 0.94 0.04 0.51 3872 K 0.12 0.46 N/A 13 0 1.24 1.16 1.07 1.00 409 K 0.49 0.16 64 K 0.94 0.03 0.19 3872 K 0.12 0.46 N/A --------------------------------------------------------------------------------------------------------------- SKT 0 1.18 1.11 1.06 1.00 113 M 0.67 0.73 139 M 0.71 0.89 1.62 186 M 1.12 0.59 N/A SKT 1 1.23 1.14 1.08 1.00 33 M 0.53 0.21 11 M 0.89 0.07 0.28 38 M 0.12 0.45 N/A --------------------------------------------------------------------------------------------------------------- TOTAL * 1.21 1.13 1.07 1.00 147 M 0.65 0.46 150 M 0.74 0.47 0.93 224 M 0.62 0.57 N/A
Instructions retired: 319 G ; Active cycles: 283 G ; Time (TSC): 2108 Mticks ; C0 (active,non-halted) core residency: 107.12 %
PHYSICAL CORE IPC : 2.25 => corresponds to 32.18 % utilization for cores in active state Instructions per nominal CPU cycle: 2.41 => corresponds to 34.48 % core utilization over time interval ---------------------------------------------------------------------------------------------------------------
Cleaning up Zeroed PMU registers
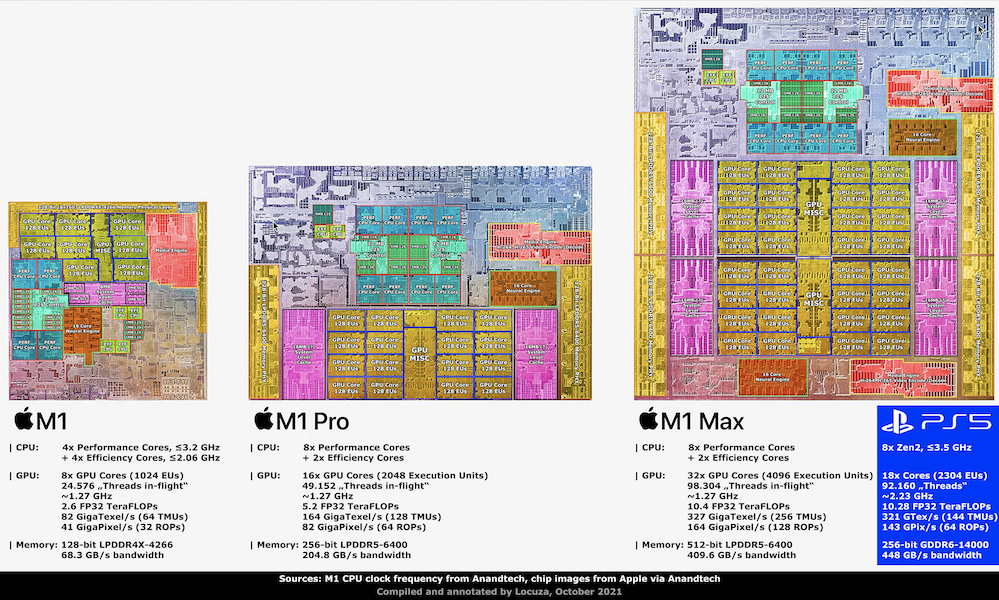
Apple M1
The M1
The critically-acclaimed M1 processor delivers:
16 billion transistors and a 119mm squared-die size.
//compile:gcc -o simd -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ./simd.c // int main (void) { // ... Initialize mul1 and mul2 int i, i2, j, j2, k, k2;
for (i = 0; i < N; ++i) for (j = 0; j < N; ++j) tmp[i][j] = mul2[j][i]; //先转置 for (i = 0; i < N; ++i) for (j = 0; j < N; ++j) for (k = 0; k < N; ++k) res[i][j] += mul1[i][k] * tmp[j][k]; //转置后按行访问,对内存友好
Floating-point fused Multiply-Add (scalar). This instruction multiplies the values of the first two SIMD&FP source registers, adds the product to the value of the third SIMD&FP source register, and writes the result to the SIMD&FP destination register.
#define ONE p = (char **)*p; #define FIVE ONE ONE ONE ONE ONE #define TEN FIVE FIVE #define FIFTY TEN TEN TEN TEN TEN #define HUNDRED FIFTY FIFTY
static void usage() { printf("Usage: ./mem-lat -b xxx -n xxx -s xxx\n"); printf(" -b buffer size in KB\n"); printf(" -n number of read\n\n"); printf(" -s stride skipped before the next access\n\n"); printf("Please don't use non-decimal based number\n"); }
int main(int argc, char* argv[]) { unsigned long i, j, size, tmp; unsigned long memsize = 0x800000; /* 1/4 LLC size of skylake, 1/5 of broadwell */ unsigned long count = 1048576; /* memsize / 64 * 8 */ unsigned int stride = 64; /* skipped amount of memory before the next access */ unsigned long sec, usec; struct timeval tv1, tv2; struct timezone tz; unsigned int *indices;
while (argc-- > 0) { if ((*argv)[0] == '-') { /* look at first char of next */ switch ((*argv)[1]) { /* look at second */ case 'b': argv++; argc--; memsize = atoi(*argv) * 1024; break;
case 'n': argv++; argc--; count = atoi(*argv); break;
case 's': argv++; argc--; stride = atoi(*argv); break;
// trick 2: fill mem with pointer references for (i = 0; i < size - 1; i++) *(char **)&mem[indices[i]*stride]= (char*)&mem[indices[i+1]*stride]; *(char **)&mem[indices[size-1]*stride]= (char*)&mem[indices[0]*stride];
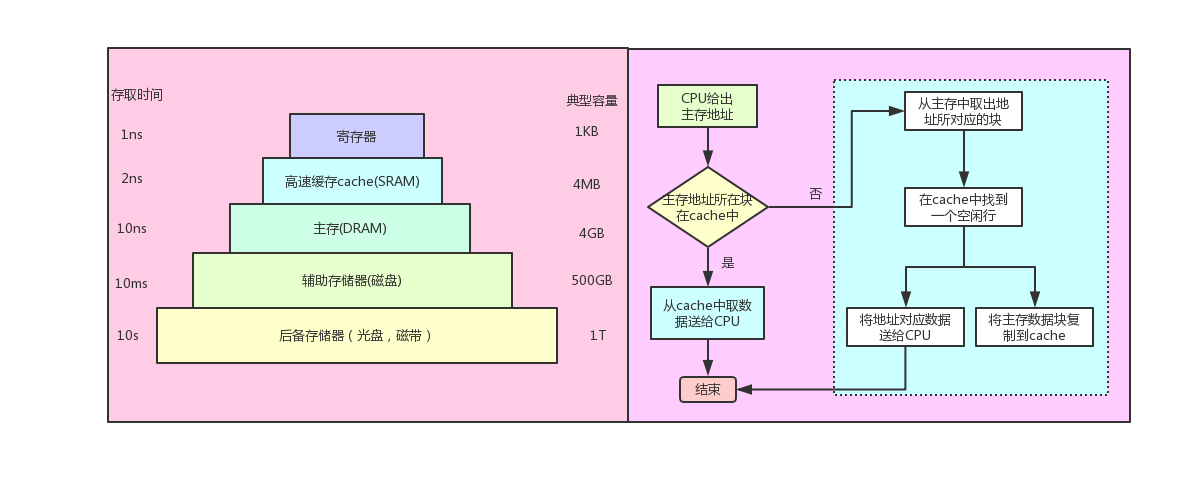
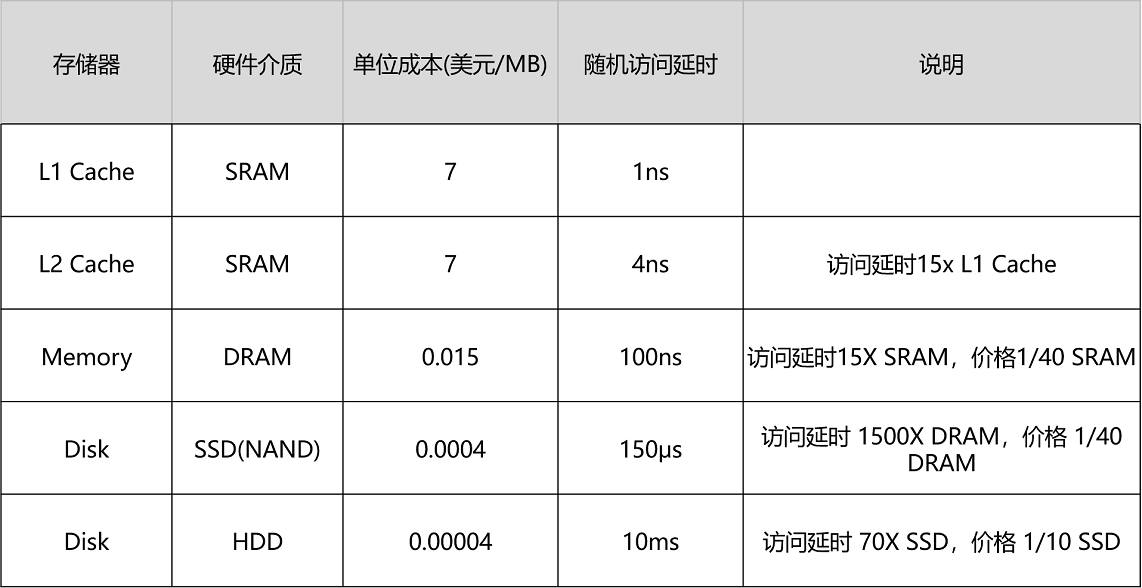
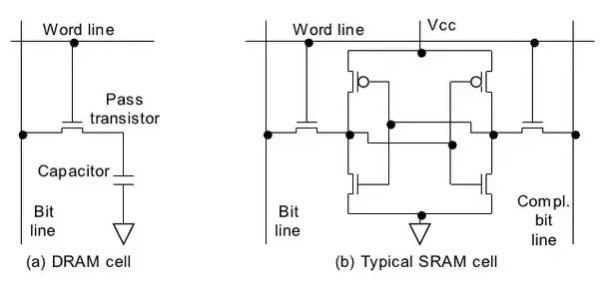
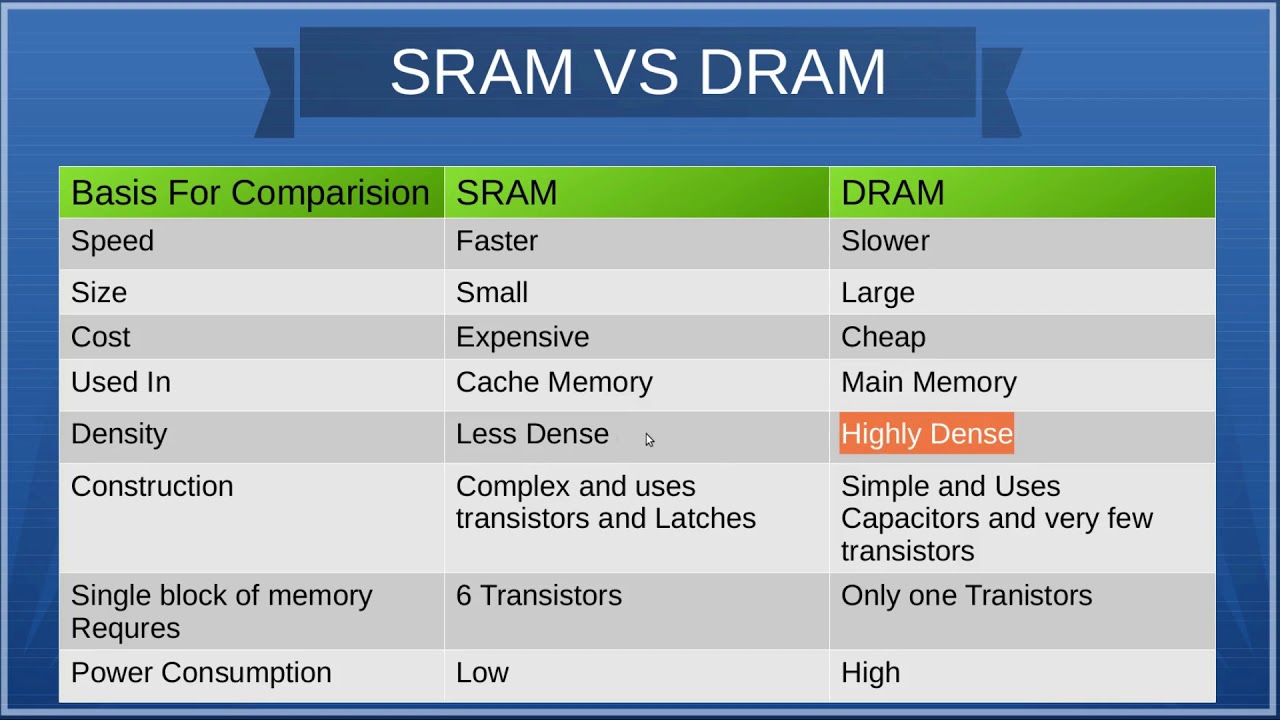
为磁芯存储器画上句号的是集成电路随机存储器件。1966年,IBM Thomas J. Watson研究中心的Dr. Robert H. Dennard开发出了单个单元的动态随机存储器DRAM,DRAM每个单元包含一个开关晶体管和一个电容,利用电容中的电荷存储数据。因为电容中的电荷会泄露,需要每个周期都进行刷新重新补充电量,所以称其为动态随机存储器。
我们俗称DDR4-2666实际指的是等效频率,是通过上升下降沿进行数据预取放大后的实际数据传输频率,DDR4 prefetch是8,通过bank group提升到核心频率的16倍,所以DDR4的最低起频是133.333MHz*16=2133MHz。DDR(Double Data Rate)因为是在一个时钟周期的上升沿和下降沿个执行预取,所以时钟频率=等效频率/2
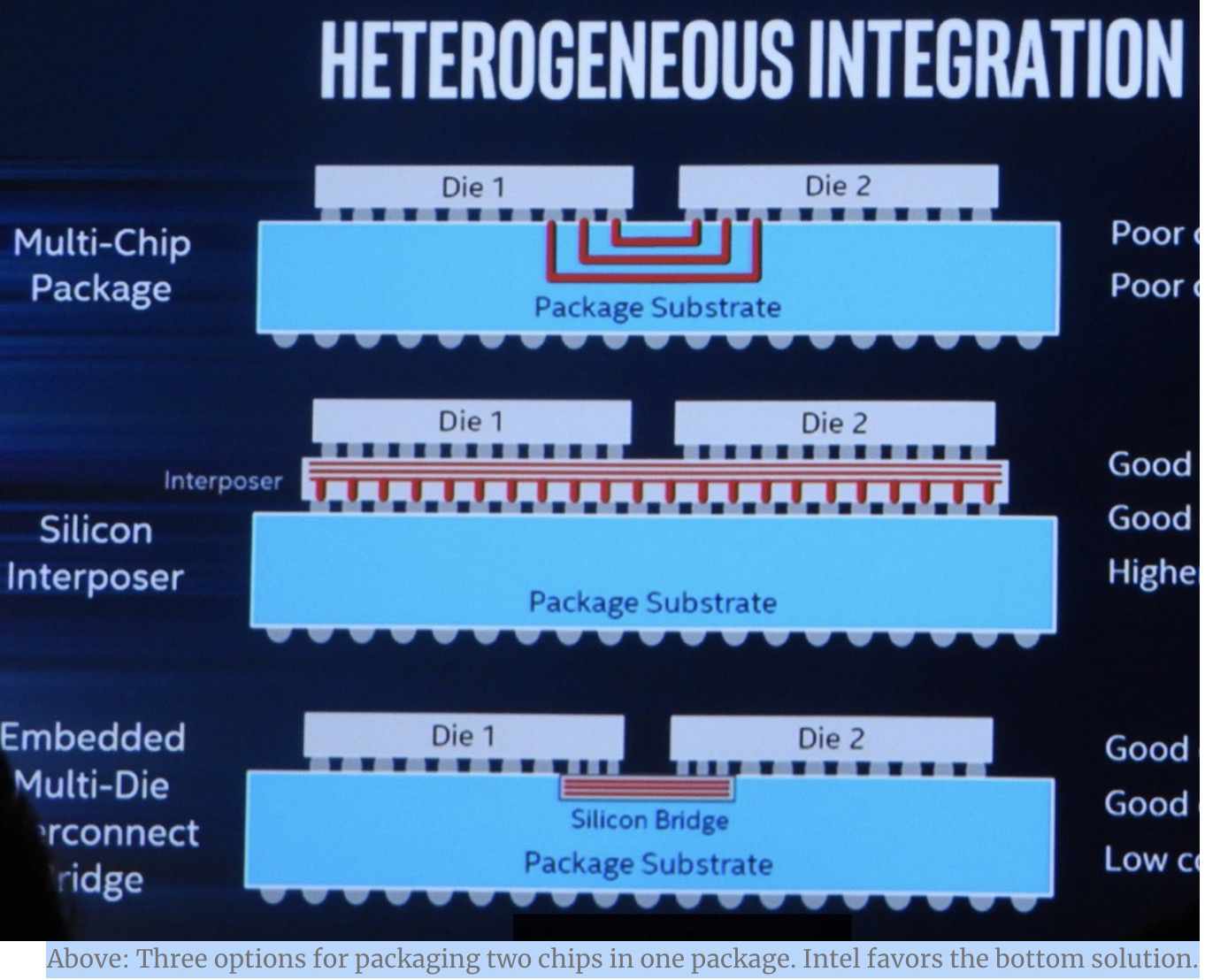
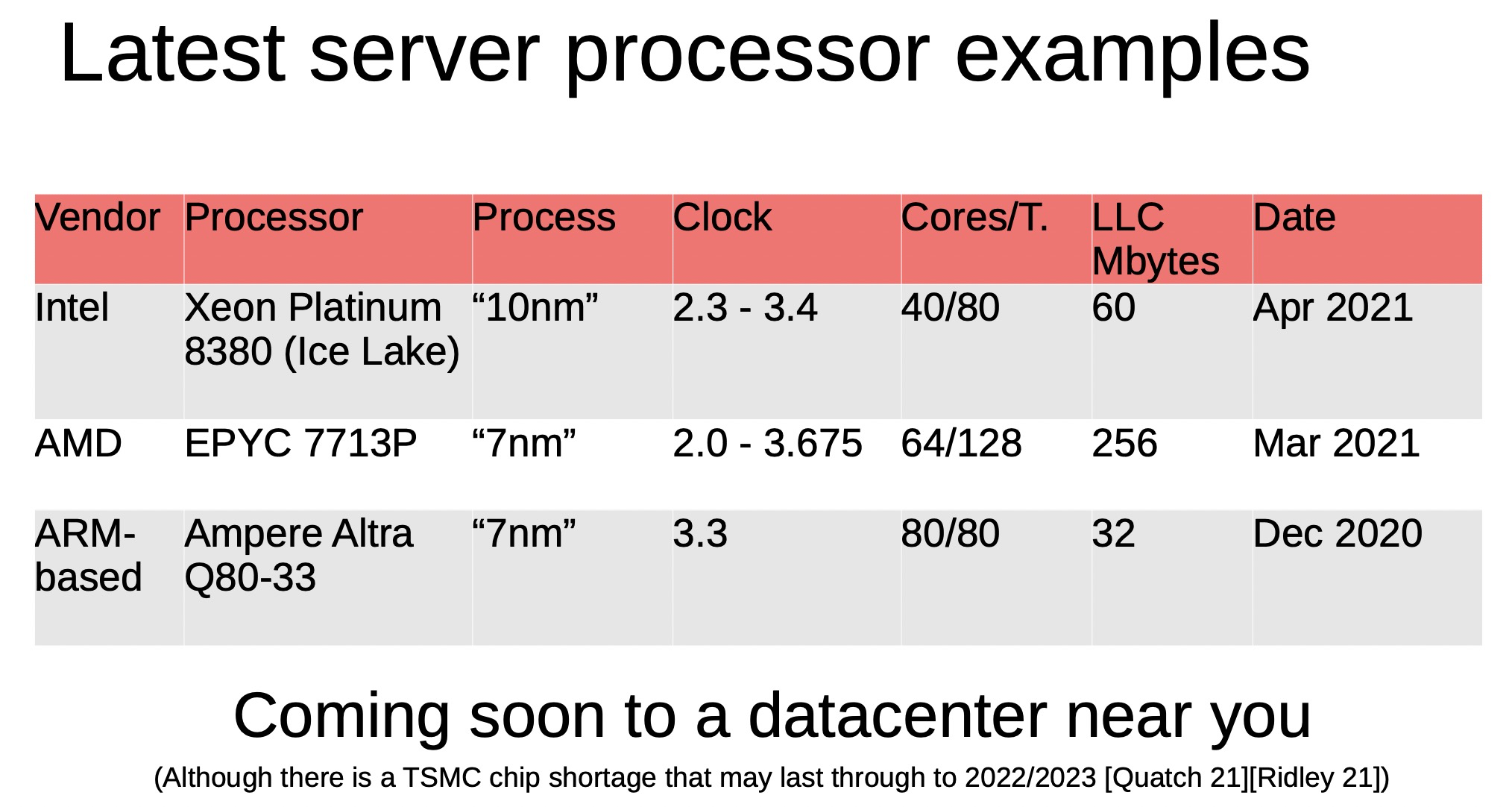
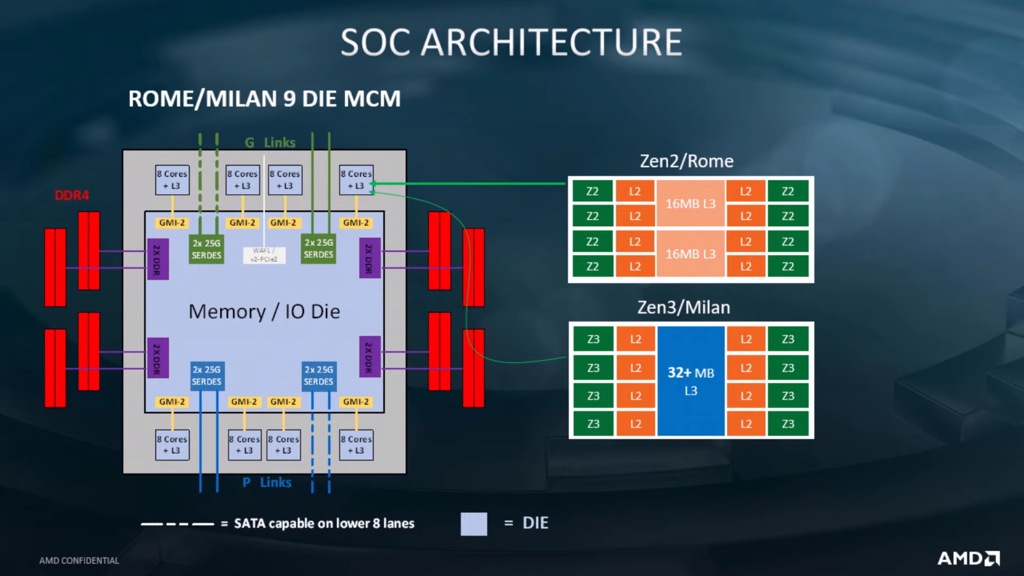
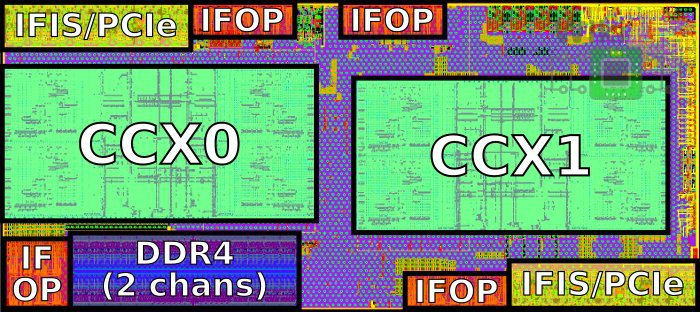
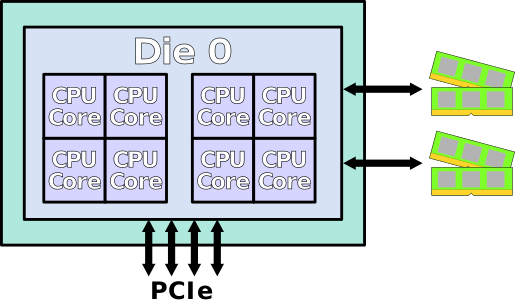
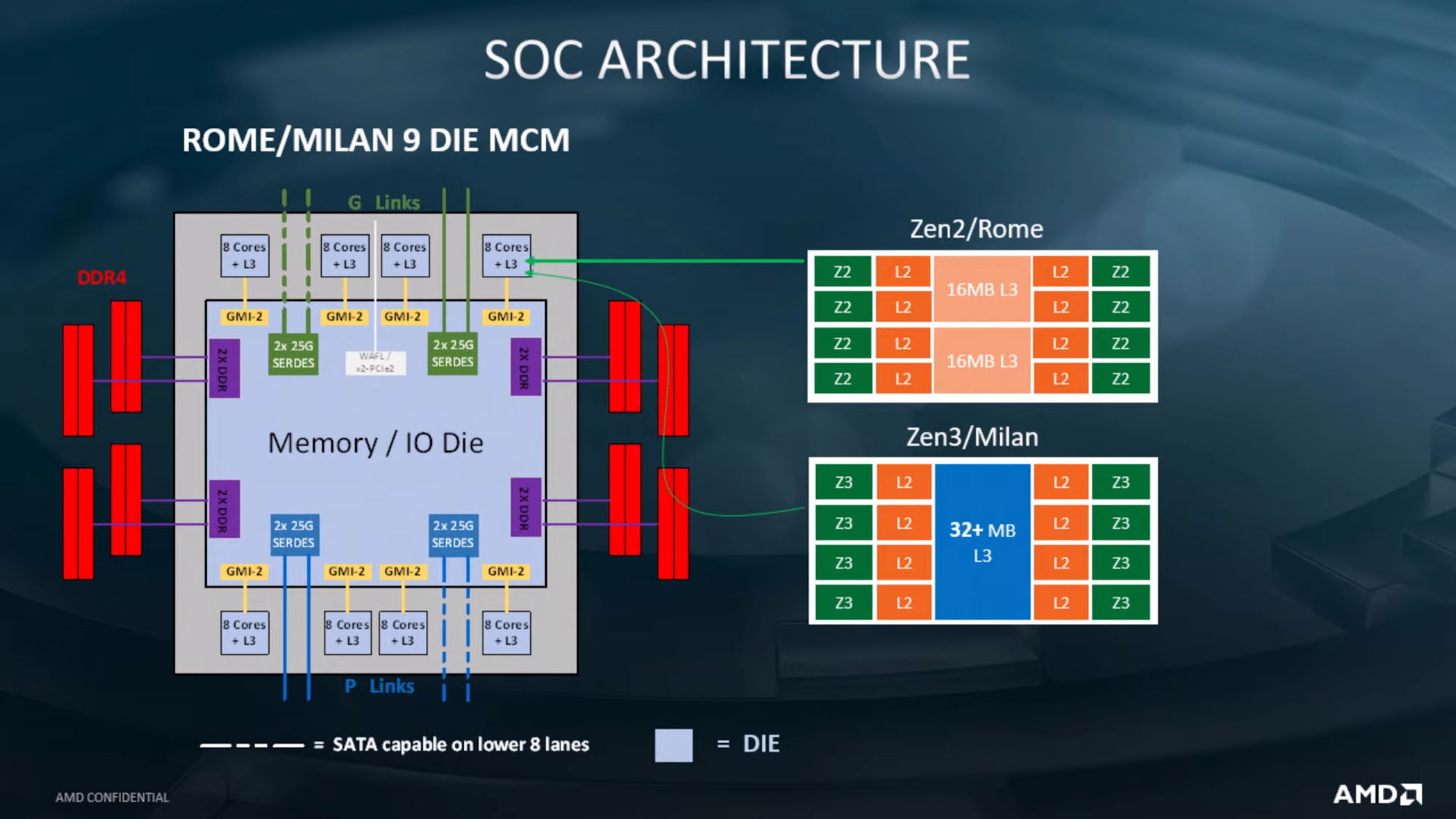
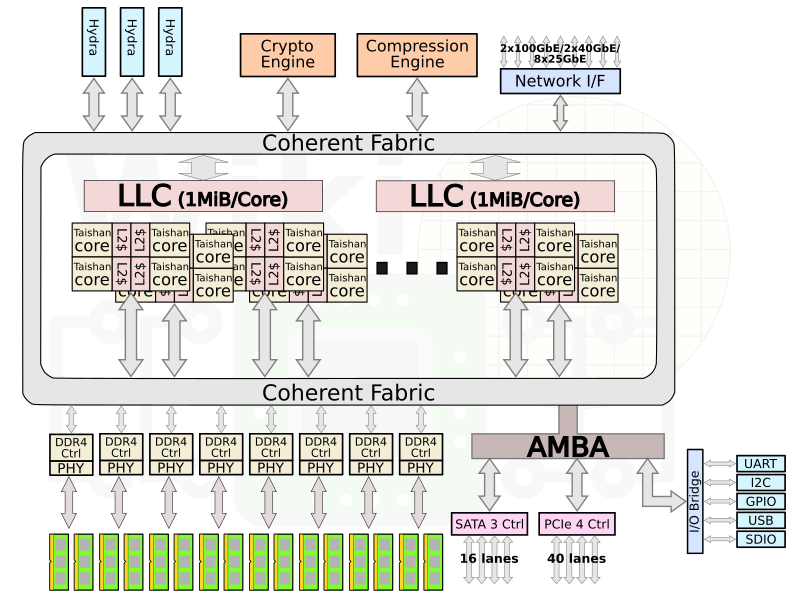
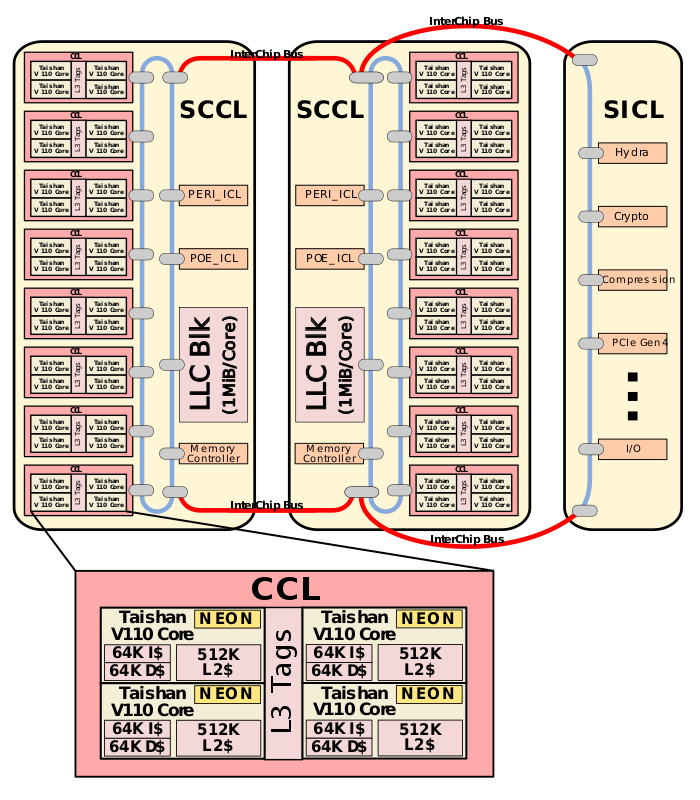
Though Huawei has been keeping a tight lip on the chip design itself, the Hi1620 is actually a multi-chip design. Actually, we believe are three dies. The chip itself comprise two compute dies called the Super CPU cluster (SCCL), each one packing 32 cores. It’s also possible the SCCL only have 24 cores, in which case there are three such dies with a theoretical maximum core count of 72 cores possible but are not offered for yield reasons. Regardless of this, there are at least two SCCL dies for sure. Additionally, there is also an I/O die called the Super IO Cluster (SICL) which contains all the high-speed SerDes and low-speed I/Os.
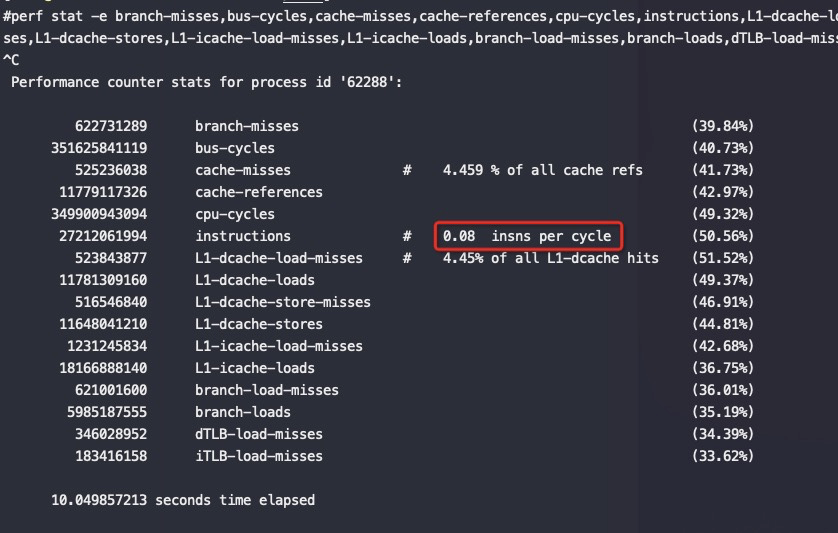
#perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads,cpu-migrations -p 20799 ^C Performance counter stats for process id '20799':
2,866,418,154 branch-misses (59.84%) 549,673,215,827 bus-cycles (59.89%) 2,179,816,578 cache-misses # 2.360 % of all cache refs (59.93%) 92,377,674,343 cache-references (60.04%) 549,605,057,475 cpu-cycles (65.05%) 229,958,980,614 instructions # 0.42 insn per cycle # 1.31 stalled cycles per insn (65.05%) 146,201,062,116 stalled-cycles-backend # 26.60% backend cycles idle (65.08%) 301,814,831,043 stalled-cycles-frontend # 54.91% frontend cycles idle (65.08%) 2,177,062,319 L1-dcache-load-misses # 2.35% of all L1-dcache hits (65.04%) 92,481,797,426 L1-dcache-loads (65.11%) 2,175,030,428 L1-dcache-store-misses (65.15%) 92,507,474,710 L1-dcache-stores (65.14%) 9,299,812,249 L1-icache-load-misses # 12.47% of all L1-icache hits (65.20%) 74,579,909,037 L1-icache-loads (65.16%) 2,862,664,443 branch-load-misses (65.08%) 52,826,930,842 branch-loads (65.04%) 3,729,265,130 dTLB-load-misses # 3.11% of all dTLB cache hits (64.95%) 119,896,014,498 dTLB-loads (59.90%) 1,350,782,047 iTLB-load-misses # 1.83% of all iTLB cache hits (59.84%) 74,005,620,378 iTLB-loads (59.82%) 510 cpu-migrations
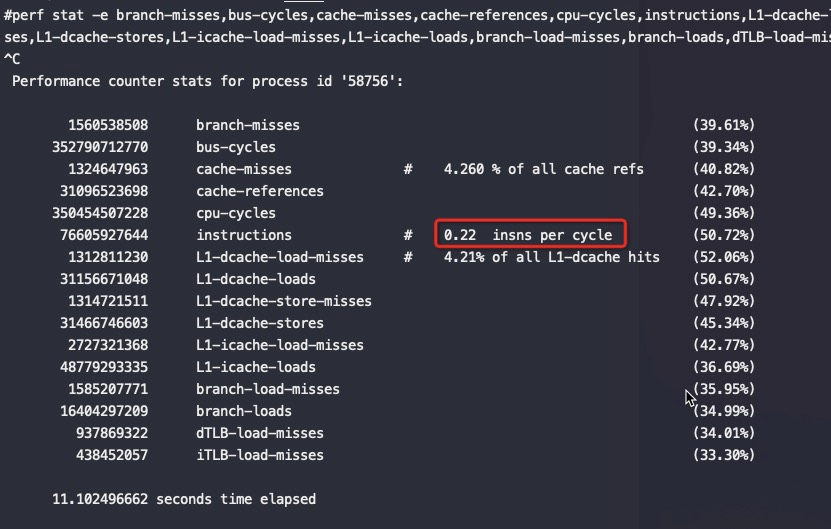
#perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads,cpu-migrations -p 20799 ^C Performance counter stats for process id '20799':
2,665,583,722 branch-misses (59.90%) 500,184,789,050 bus-cycles (59.95%) 1,997,726,097 cache-misses # 2.254 % of all cache refs (59.94%) 88,628,013,529 cache-references (59.93%) 500,111,712,450 cpu-cycles (64.98%) 221,098,464,920 instructions # 0.44 insn per cycle # 1.35 stalled cycles per insn (65.02%) 105,957,124,479 stalled-cycles-backend # 21.19% backend cycles idle (65.02%) 298,186,439,955 stalled-cycles-frontend # 59.62% frontend cycles idle (65.02%) 1,996,313,908 L1-dcache-load-misses # 2.25% of all L1-dcache hits (65.04%) 88,701,699,646 L1-dcache-loads (65.09%) 1,997,851,364 L1-dcache-store-misses (65.10%) 88,614,658,960 L1-dcache-stores (65.10%) 8,635,807,737 L1-icache-load-misses # 12.30% of all L1-icache hits (65.13%) 70,233,323,630 L1-icache-loads (65.16%) 2,665,567,783 branch-load-misses (65.10%) 50,482,936,168 branch-loads (65.09%) 3,614,564,473 dTLB-load-misses # 3.15% of all dTLB cache hits (65.04%) 114,619,822,486 dTLB-loads (59.96%) 1,270,926,362 iTLB-load-misses # 1.81% of all iTLB cache hits (59.97%) 70,248,645,721 iTLB-loads (59.94%) 128 cpu-migrations
#perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads,cpu-migrations -p 49512 ^C Performance counter stats for process id '49512':
1,849,313,199 branch-misses (59.99%) 319,122,053,367 bus-cycles (60.02%) 1,319,212,546 cache-misses # 2.238 % of all cache refs (59.95%) 58,950,581,370 cache-references (60.02%) 319,088,767,311 cpu-cycles (65.01%) 146,580,891,374 instructions # 0.46 insn per cycle # 1.32 stalled cycles per insn (65.01%) 61,109,919,226 stalled-cycles-backend # 19.15% backend cycles idle (65.04%) 193,963,590,196 stalled-cycles-frontend # 60.79% frontend cycles idle (65.06%) 1,319,593,051 L1-dcache-load-misses # 2.24% of all L1-dcache hits (65.03%) 58,967,303,454 L1-dcache-loads (65.04%) 1,318,842,690 L1-dcache-store-misses (65.13%) 58,988,059,583 L1-dcache-stores (65.07%) 5,769,871,870 L1-icache-load-misses # 12.25% of all L1-icache hits (65.12%) 47,085,299,316 L1-icache-loads (65.10%) 1,850,419,802 branch-load-misses (65.03%) 33,687,548,636 branch-loads (65.08%) 2,375,028,039 dTLB-load-misses # 3.12% of all dTLB cache hits (65.08%) 76,113,084,244 dTLB-loads (60.01%) 825,388,210 iTLB-load-misses # 1.75% of all iTLB cache hits (59.99%) 47,092,738,092 iTLB-loads (59.95%) 49 cpu-migrations
#dmidecode -t processor # dmidecode 3.0 Getting SMBIOS data from sysfs. SMBIOS 3.2.0 present. # SMBIOS implementations newer than version 3.0 are not # fully supported by this version of dmidecode.
Handle 0x0004, DMI type 4, 48 bytes Processor Information Socket Designation: BGA3576 Type: Central Processor Family: <OUT OF SPEC> Manufacturer: PHYTIUM ID: 00 00 00 00 70 1F 66 22 Version: FT2500 Voltage: 0.8 V External Clock: 50 MHz Max Speed: 2100 MHz Current Speed: 2100 MHz Status: Populated, Enabled Upgrade: Other L1 Cache Handle: 0x0005 L2 Cache Handle: 0x0007 L3 Cache Handle: 0x0008 Serial Number: 1234567 Asset Tag: No Asset Tag Part Number: NULL Core Count: 64 Core Enabled: 64 Thread Count: 64 Characteristics: 64-bit capable Multi-Core Hardware Thread Execute Protection Enhanced Virtualization Power/Performance Control
#dmidecode -t processor # dmidecode 3.0 Getting SMBIOS data from sysfs. SMBIOS 3.2.0 present. # SMBIOS implementations newer than version 3.0 are not # fully supported by this version of dmidecode.
Handle 0x0022, DMI type 4, 48 bytes Processor Information Socket Designation: CPU 0 Type: Central Processor Family: Other Manufacturer: SW3231 ID: 28 00 C8 80 01 00 00 00 Version: Product Voltage: 3.3 V External Clock: 200 MHz Max Speed: 2400 MHz Current Speed: 2400 MHz Status: Unpopulated Upgrade: Other L1 Cache Handle: 0x2000 L2 Cache Handle: 0x2002 L3 Cache Handle: 0x2003 Serial Number: ....... Asset Tag: Asset Tag#To Be Filled By O.E.M. Part Number: Part Number#To Be Filled By O.E.M. Core Count: 32 Core Enabled: 32 Thread Count: 0 Characteristics: 64-bit capable
Handle 0x0023, DMI type 4, 48 bytes Processor Information Socket Designation: CPU 1 Type: Central Processor Family: Other Manufacturer: SW3231 ID: 28 00 C8 80 01 00 00 00 Version: Product Voltage: 3.3 V External Clock: 200 MHz Max Speed: 2400 MHz Current Speed: 2400 MHz Status: Unpopulated Upgrade: Other L1 Cache Handle: 0x2000 L2 Cache Handle: 0x2002 L3 Cache Handle: 0x2003 Serial Number: ....... Asset Tag: Asset Tag#To Be Filled By O.E.M. Part Number: Part Number#To Be Filled By O.E.M. Core Count: 32 Core Enabled: 32 Thread Count: 0 Characteristics: 64-bit capable
for i in {0..95}; do time echo “scale=5000; 4*a(1)” | bc -l -q >/dev/null & done
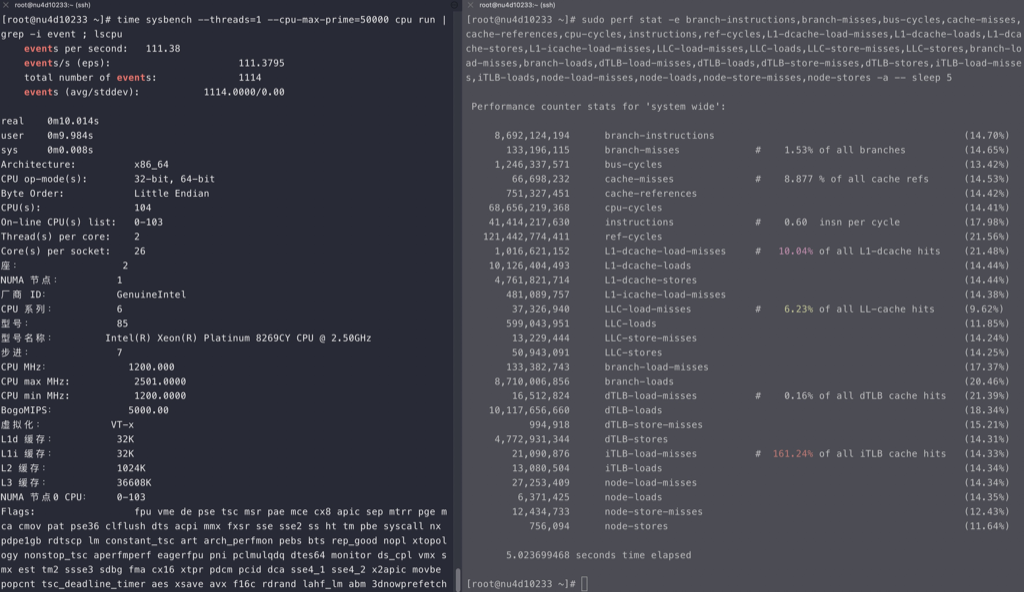
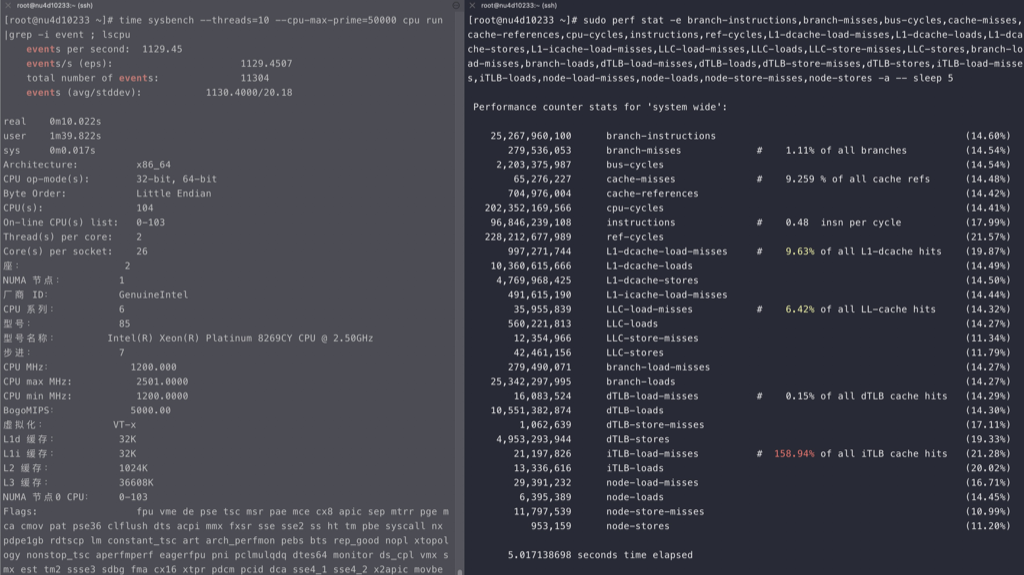
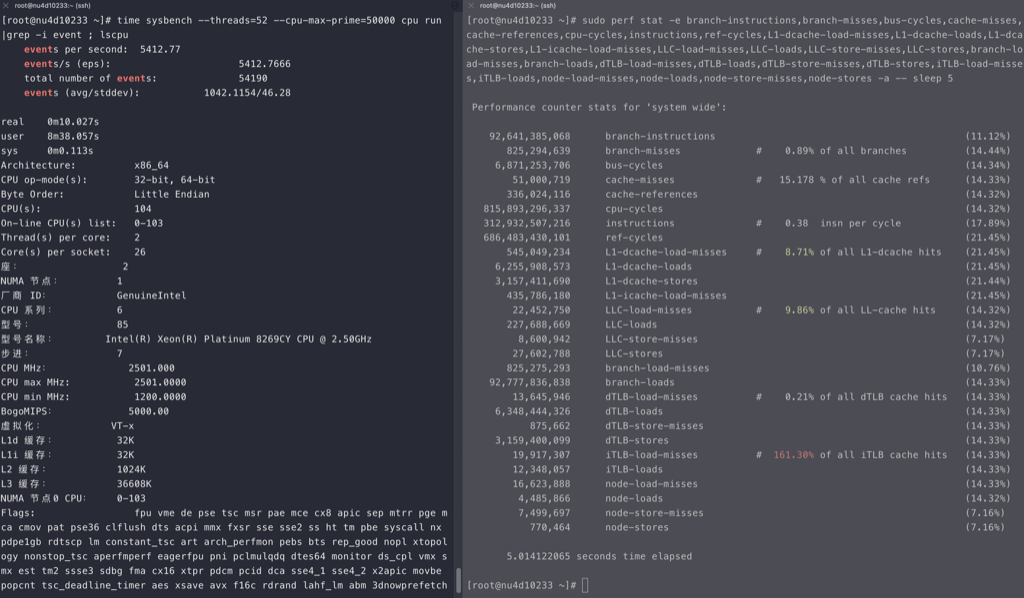
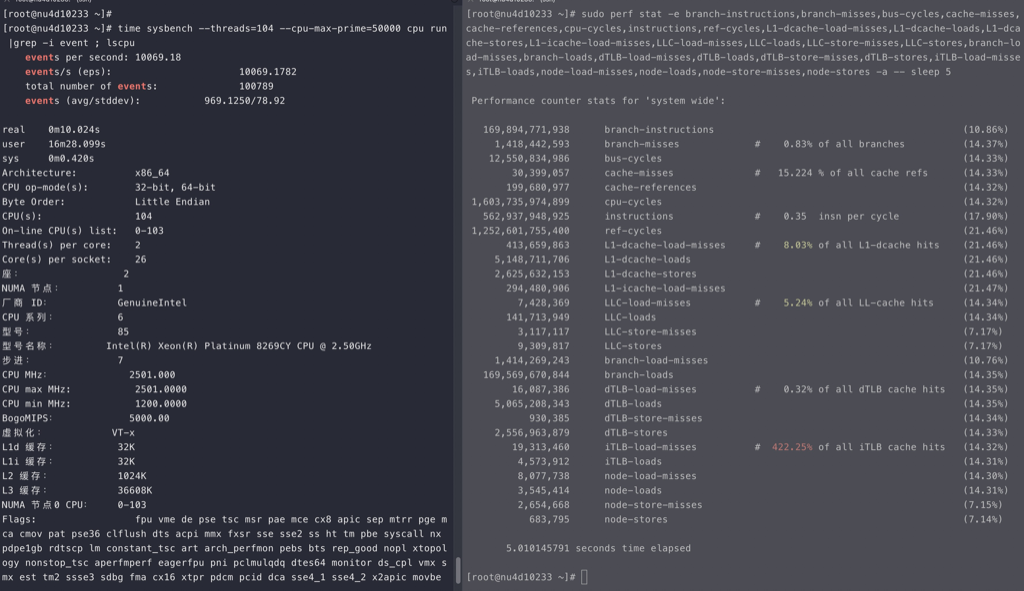
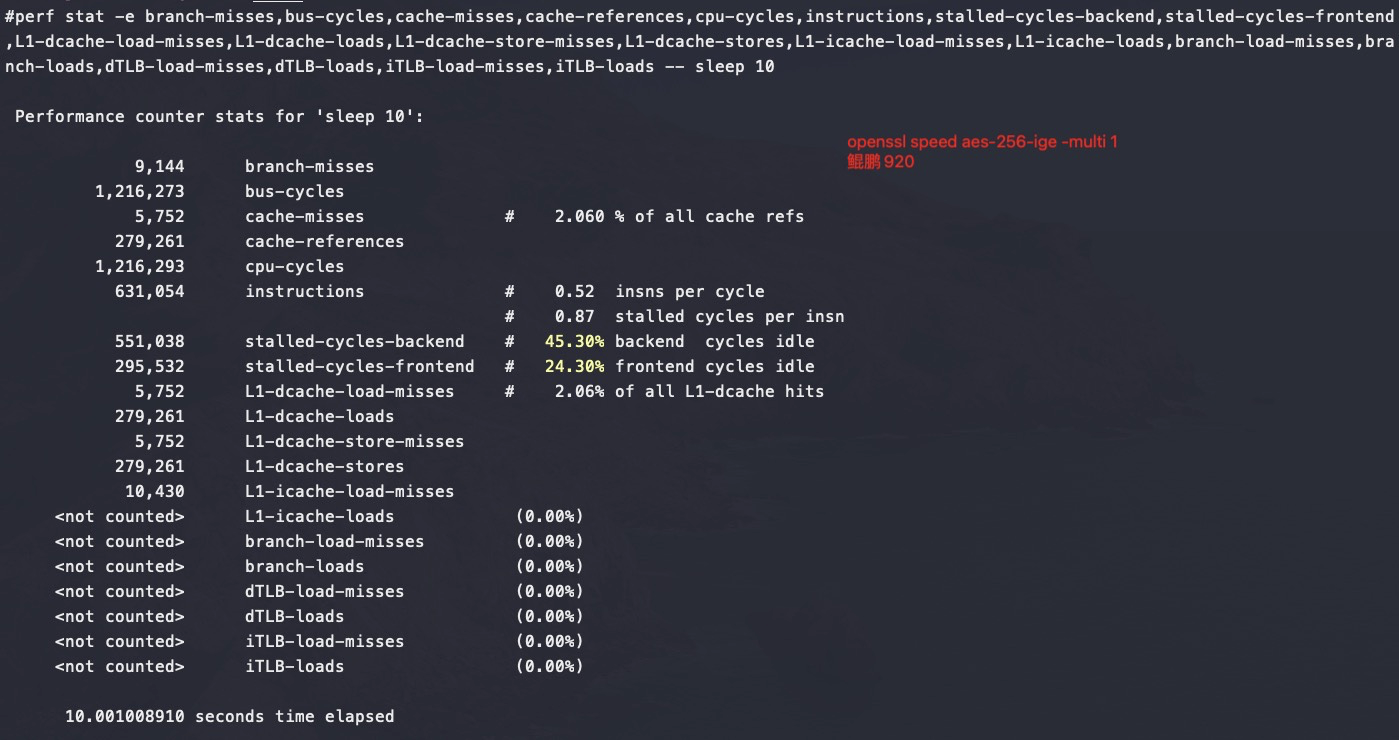
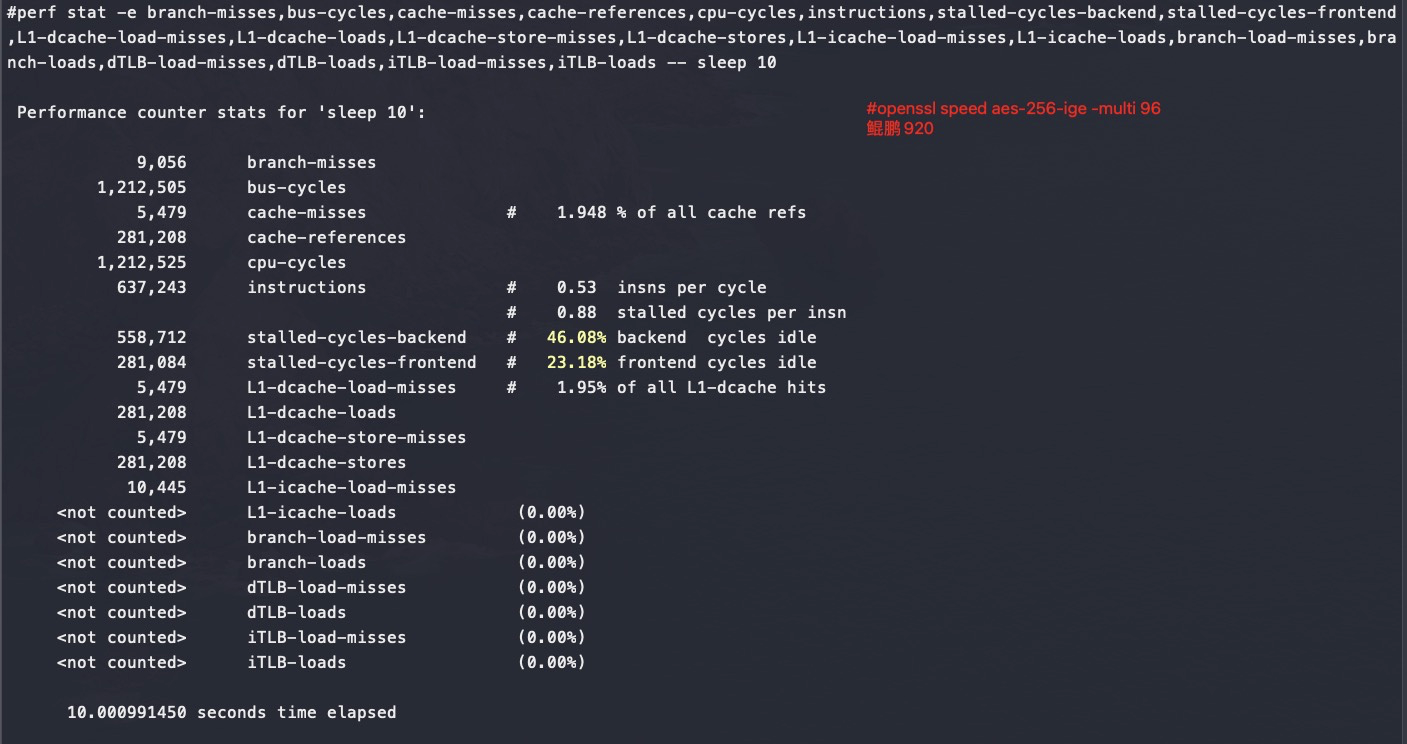
perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads –
710
耗时15.83秒,ipc 2.64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,alignment-faults,bpf-output,context-switches,cpu-clock,cpu-migrations,dummy,emulation-faults,major-faults,minor-faults,page-faults,task-clock,L1-dcache-load-misses,L1-dcache-loads,L1-icache-load-misses,L1-icache-loads,LLC-load-misses,LLC-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads -- bash -c 'echo "7^999999" | bc > /dev/null'
Performance counter stats for 'bash -c echo "7^999999" | bc > /dev/null':
sudo perf stat -e branch-instructions,branch-misses,cache-references,cpu-cycles,instructions,stalled-cycles-backend,stalled-cycles-frontend,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-prefetches,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,iTLB-load-misses,iTLB-loads -a -- bash -c 'echo "7^999999" | bc > /dev/null'
Performance counter stats for 'system wide':
57,795,675,025 branch-instructions (27.78%) 2,459,509,459 branch-misses # 4.26% of all branches (27.78%) 12,171,133,272 cache-references (27.79%) 317,353,262,523 cpu-cycles (27.79%) 293,162,940,548 instructions # 0.92 insn per cycle # 0.19 stalled cycles per insn (27.79%) 55,152,807,029 stalled-cycles-backend # 17.38% backend cycles idle (27.79%) 44,410,732,991 stalled-cycles-frontend # 13.99% frontend cycles idle (27.79%) 4,065,273,083 L1-dcache-load-misses # 3.58% of all L1-dcache hits (27.79%) 113,699,208,151 L1-dcache-loads (27.79%) 1,351,513,191 L1-dcache-prefetches (27.79%) 2,091,035,340 L1-icache-load-misses # 4.43% of all L1-icache hits (27.79%) 47,240,289,316 L1-icache-loads (27.79%) 2,459,838,728 branch-load-misses (27.79%) 57,855,156,991 branch-loads (27.78%) 69,731,473 dTLB-load-misses # 20.40% of all dTLB cache hits (27.78%) 341,773,319 dTLB-loads (27.78%) 26,351,132 iTLB-load-misses # 15.91% of all iTLB cache hits (27.78%) 165,656,863 iTLB-loads (27.78%)
time perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,iTLB-load-misses -a -- bash -c 'echo "7^999999" | bc > /dev/null'
# sudo perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores -a ./memory_bound
Performance counter stats for 'system wide':
36,162,872,212 branch-instructions (14.21%) 586,644,153 branch-misses # 1.62% of all branches (12.95%) 4,632,787,085 bus-cycles (14.40%) 476,189,785 cache-misses # 17.714 % of all cache refs (14.38%) 2,688,284,129 cache-references (14.35%) 258,946,713,506 cpu-cycles (17.93%) 181,069,328,200 instructions # 0.70 insn per cycle (21.51%) 456,889,428,341 ref-cycles (22.31%) 3,928,434,098 L1-dcache-load-misses # 7.46% of all L1-dcache hits (14.21%) 52,656,559,902 L1-dcache-loads (14.31%) 26,711,751,387 L1-dcache-stores (14.30%) 2,618,739,340 L1-icache-load-misses (18.05%) 154,326,888 LLC-load-misses # 8.60% of all LL-cache hits (19.84%) 1,795,112,198 LLC-loads (9.81%) 66,802,375 LLC-store-misses (10.19%) 206,810,811 LLC-stores (11.16%) 586,120,789 branch-load-misses (14.28%) 36,121,237,395 branch-loads (14.29%) 114,927,298 dTLB-load-misses # 0.22% of all dTLB cache hits (14.29%) 52,902,163,128 dTLB-loads (14.29%) 7,010,297 dTLB-store-misses (14.29%) 26,587,353,417 dTLB-stores (18.00%) 106,209,281 iTLB-load-misses # 174.17% of all iTLB cache hits (19.33%) 60,978,626 iTLB-loads (21.53%) 117,197,042 node-load-misses (19.71%) 35,764,508 node-loads (11.65%) 57,655,994 node-store-misses (7.80%) 11,563,328 node-stores (9.45%)
16.700731355 seconds time elapsed # sudo perf stat -e branch-instructions,branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,ref-cycles,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-stores,L1-icache-load-misses,LLC-load-misses,LLC-loads,LLC-store-misses,LLC-stores,branch-load-misses,branch-loads,dTLB-load-misses,dTLB-loads,dTLB-store-misses,dTLB-stores,iTLB-load-misses,iTLB-loads,node-load-misses,node-loads,node-store-misses,node-stores -a ./cpu_bound
Performance counter stats for 'system wide':
43,013,055,562 branch-instructions (14.33%) 436,722,063 branch-misses # 1.02% of all branches (11.58%) 3,154,327,457 bus-cycles (14.31%) 306,977,772 cache-misses # 17.837 % of all cache refs (14.42%) 1,721,062,233 cache-references (14.39%) 176,119,834,487 cpu-cycles (17.98%) 276,038,539,571 instructions # 1.57 insn per cycle (21.55%) 309,334,354,268 ref-cycles (22.31%) 2,551,915,790 L1-dcache-load-misses # 6.78% of all L1-dcache hits (13.12%) 37,638,319,334 L1-dcache-loads (14.32%) 19,132,537,445 L1-dcache-stores (15.73%) 1,834,976,400 L1-icache-load-misses (18.90%) 131,307,343 LLC-load-misses # 11.46% of all LL-cache hits (19.94%) 1,145,964,874 LLC-loads (16.60%) 45,561,247 LLC-store-misses (8.11%) 140,236,535 LLC-stores (9.60%) 423,294,349 branch-load-misses (14.27%) 46,645,623,485 branch-loads (14.28%) 73,377,533 dTLB-load-misses # 0.19% of all dTLB cache hits (14.28%) 37,905,428,246 dTLB-loads (15.69%) 4,969,973 dTLB-store-misses (17.21%) 18,729,947,580 dTLB-stores (19.71%) 72,073,313 iTLB-load-misses # 167.86% of all iTLB cache hits (20.60%) 42,935,532 iTLB-loads (19.16%) 112,306,453 node-load-misses (15.35%) 37,239,267 node-loads (7.44%) 37,455,335 node-store-misses (10.00%) 8,134,155 node-stores (8.87%)
#time perf stat -e branch-misses,bus-cycles,cache-misses,cache-references,cpu-cycles,instructions,L1-dcache-load-misses,L1-dcache-loads,L1-dcache-store-misses,L1-dcache-stores,L1-icache-load-misses,L1-icache-loads,branch-load-misses,branch-loads,dTLB-load-misses,iTLB-load-misses -a ./cpu_bound
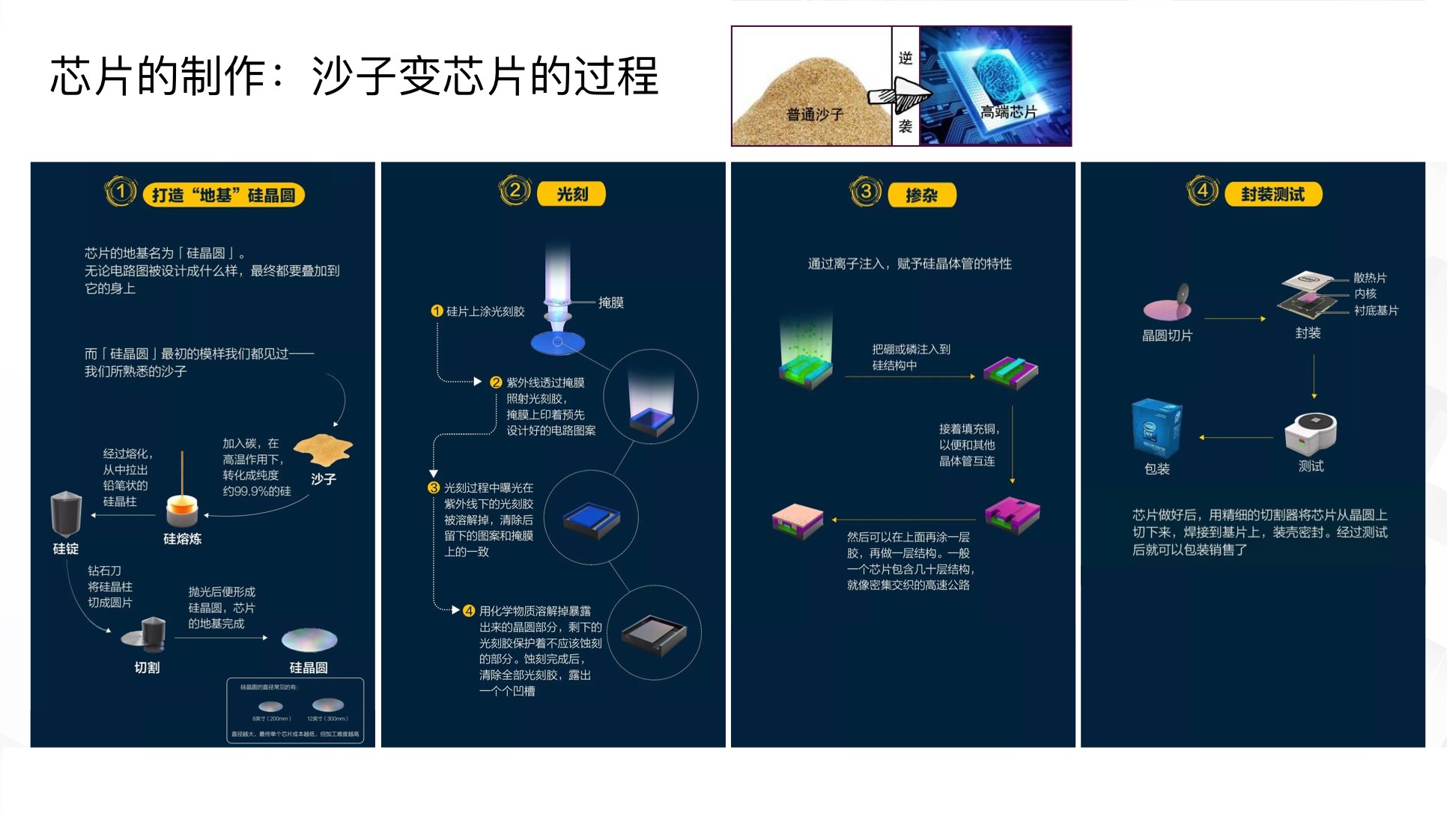
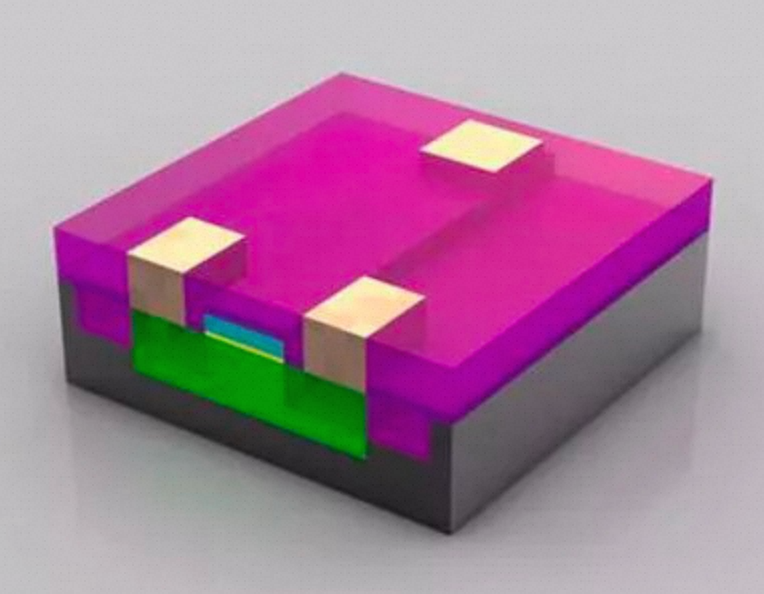
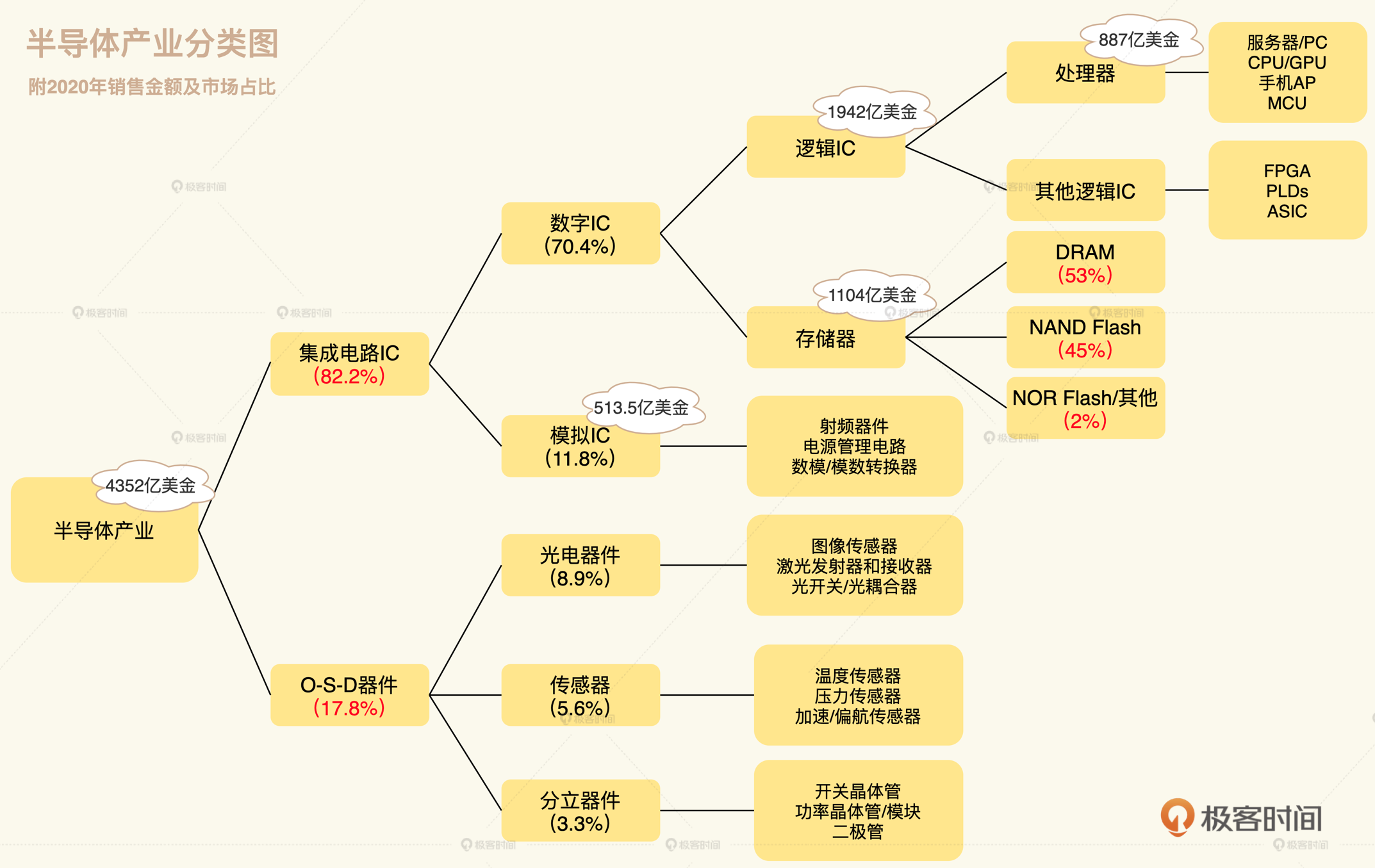
MOS :金属-氧化物-半导体,而拥有这种结构的晶体管我们称之为MOS晶体管。 MOS晶体管有P型MOS管和N型MOS管之分。 由MOS管构成的集成电路称为MOS集成电路,由NMOS组成的电路就是NMOS集成电路,由PMOS管组成的电路就是PMOS集成电路,由NMOS和PMOS两种管子组成的互补MOS电路,即CMOS电路
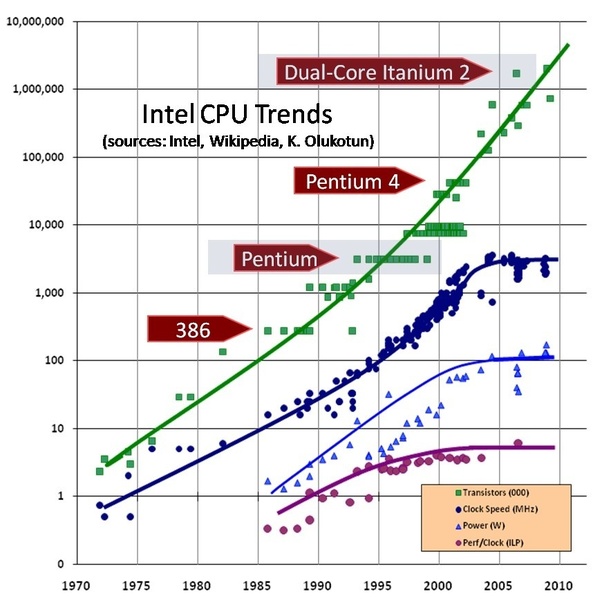
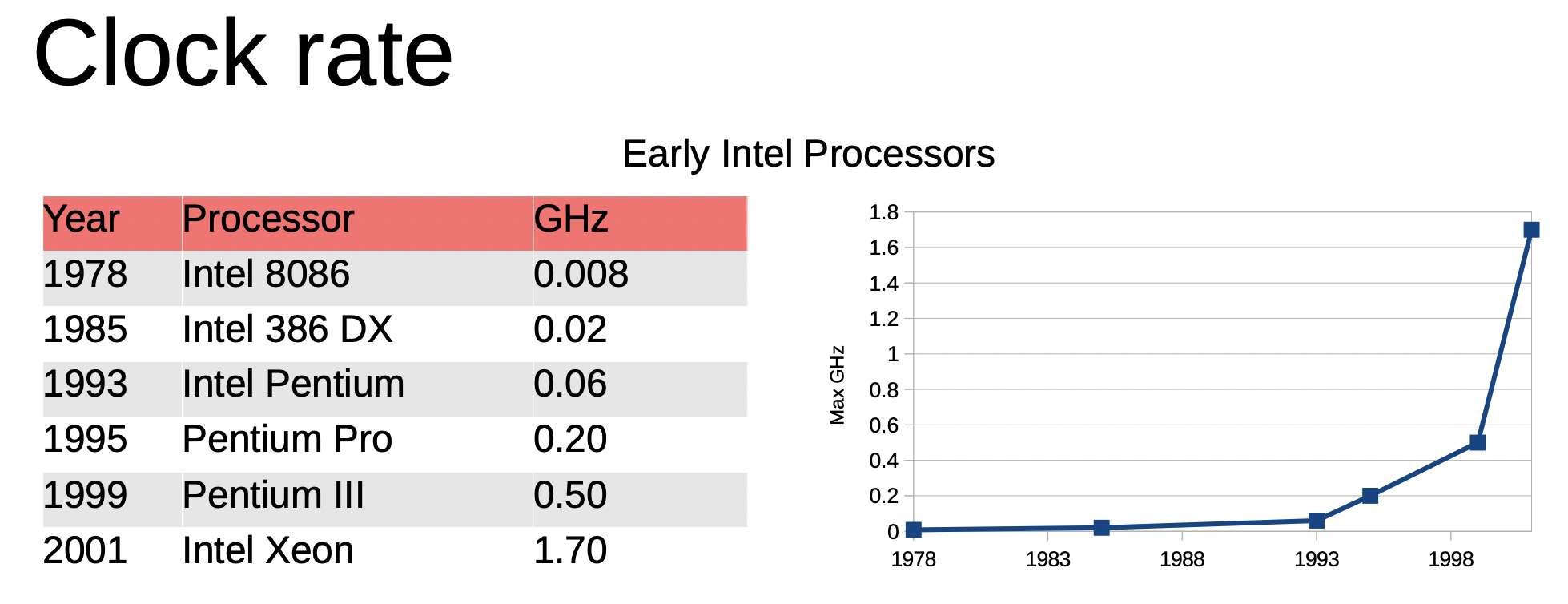
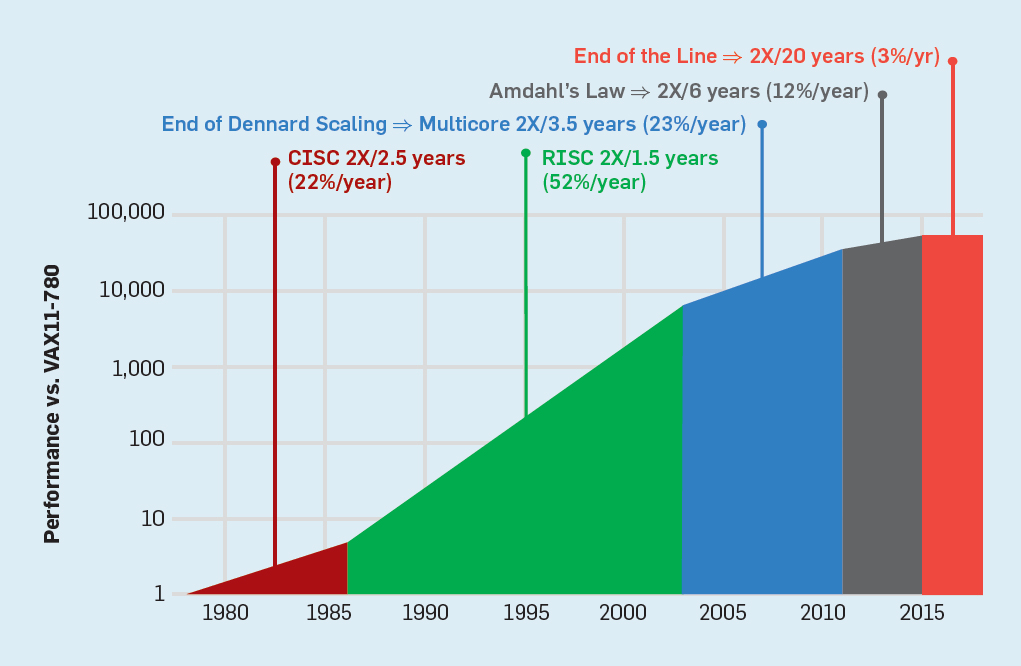
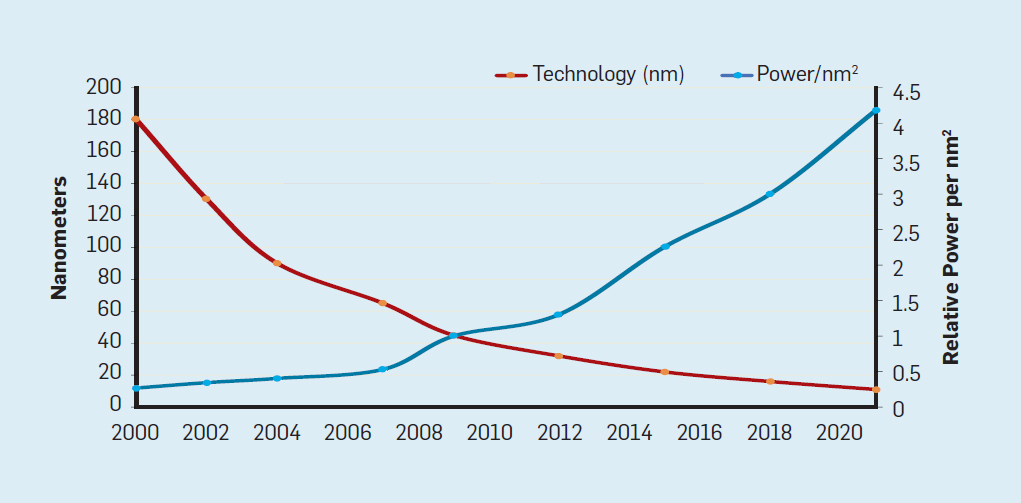
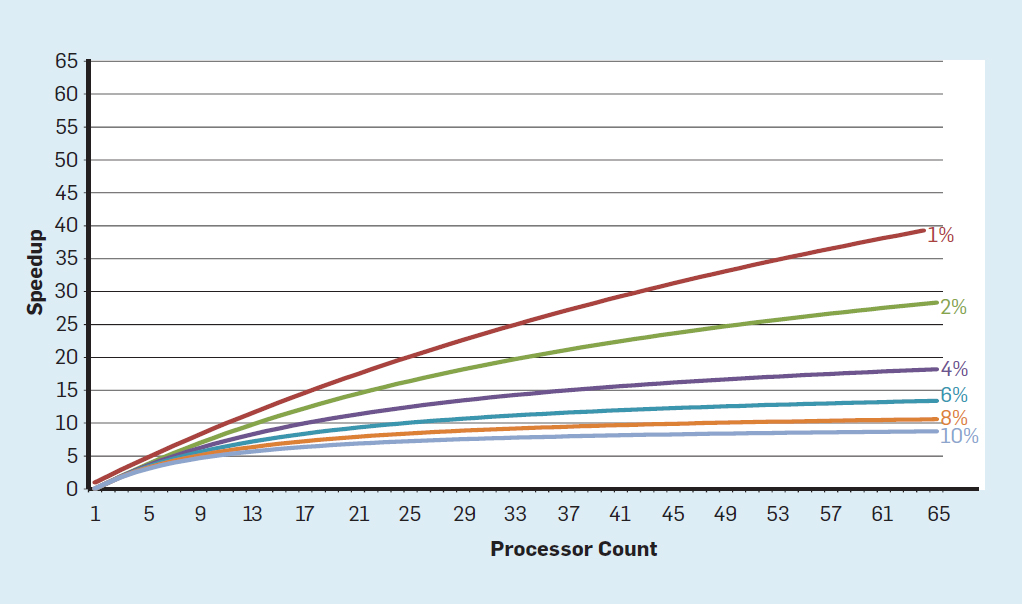
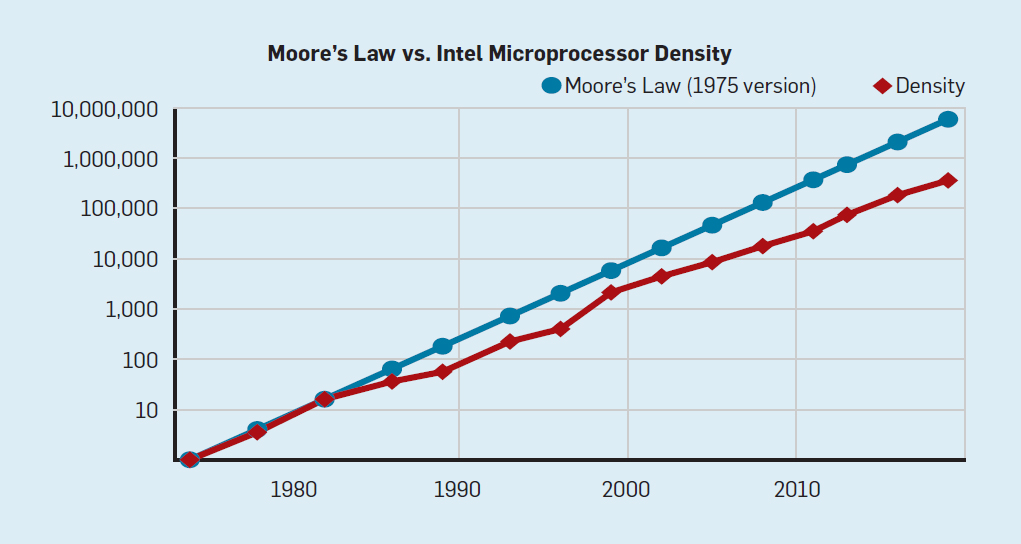
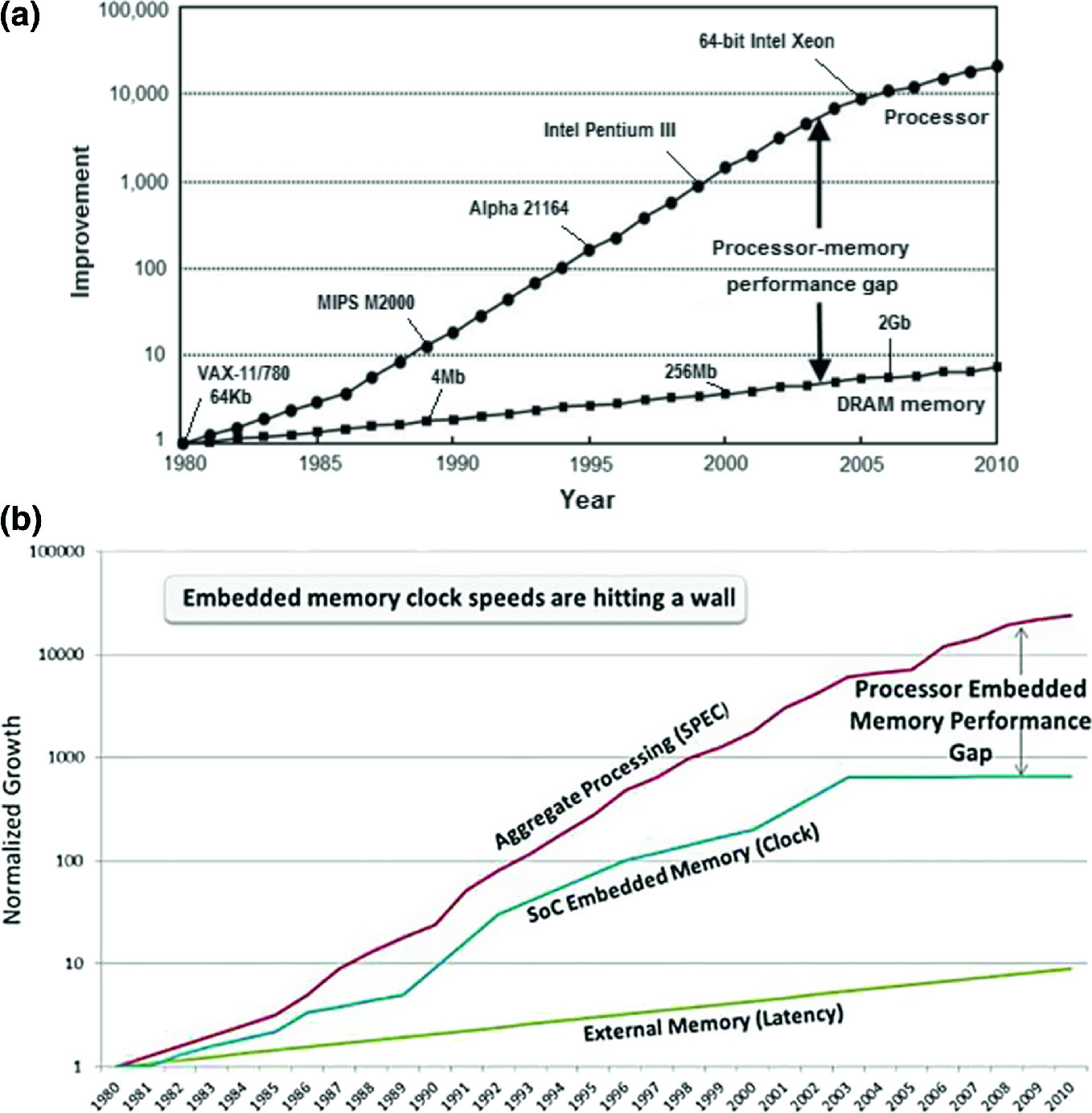
the industry came up with many different solution to create better computers w/o (or almost without) increasing the clock speed.
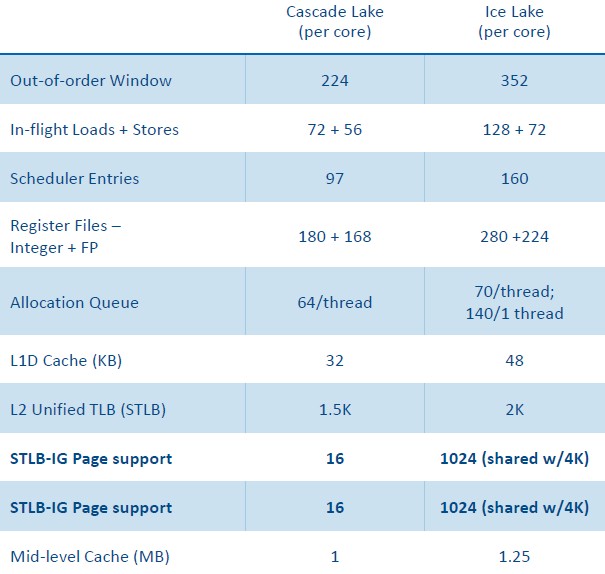
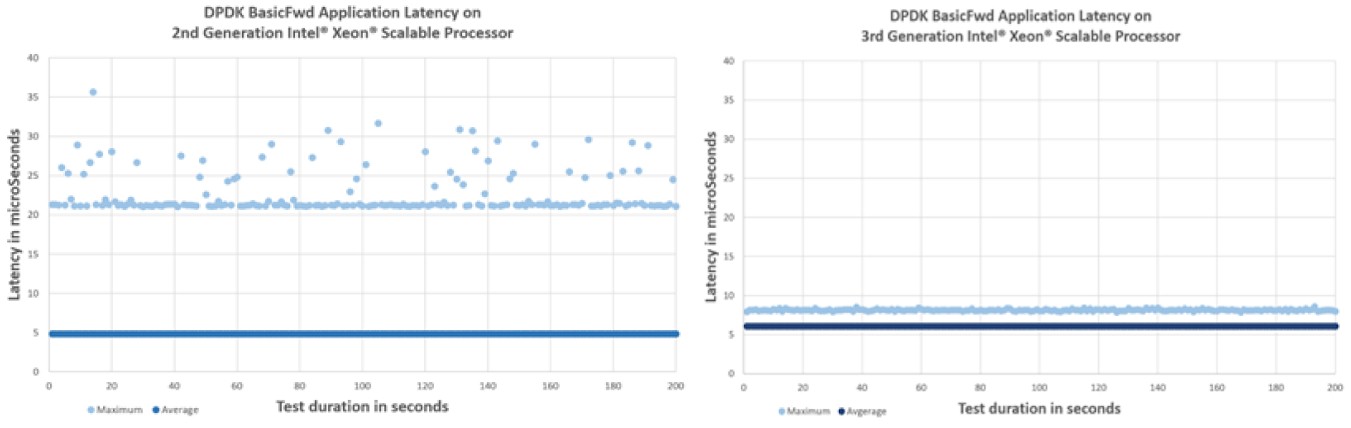
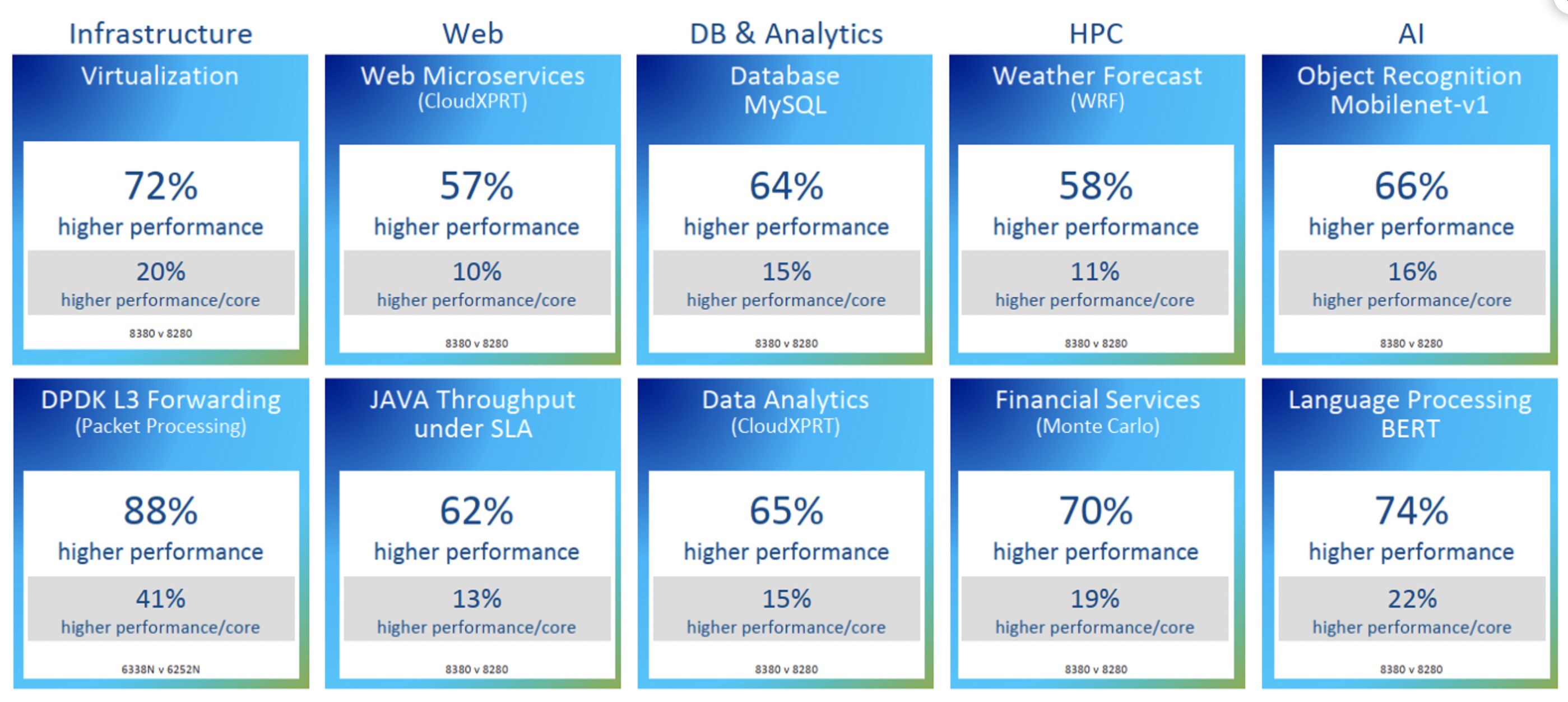
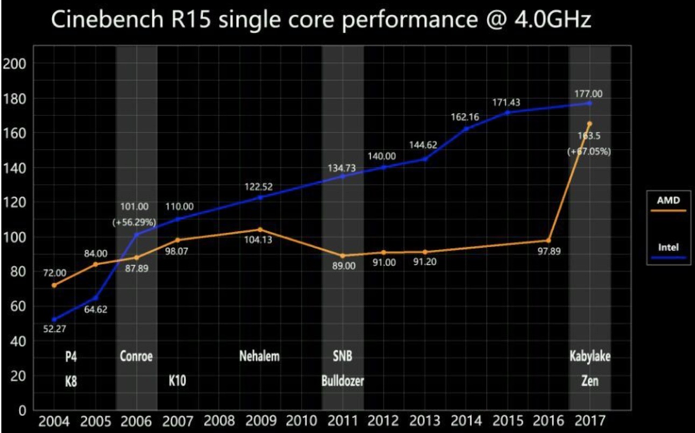
比较两代CPU性能变化
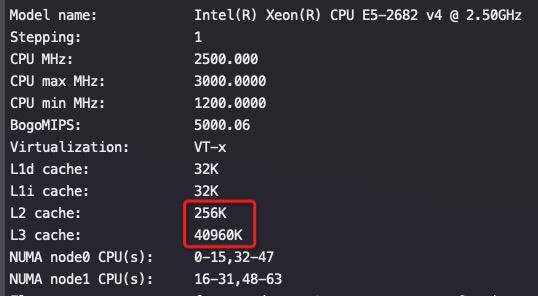
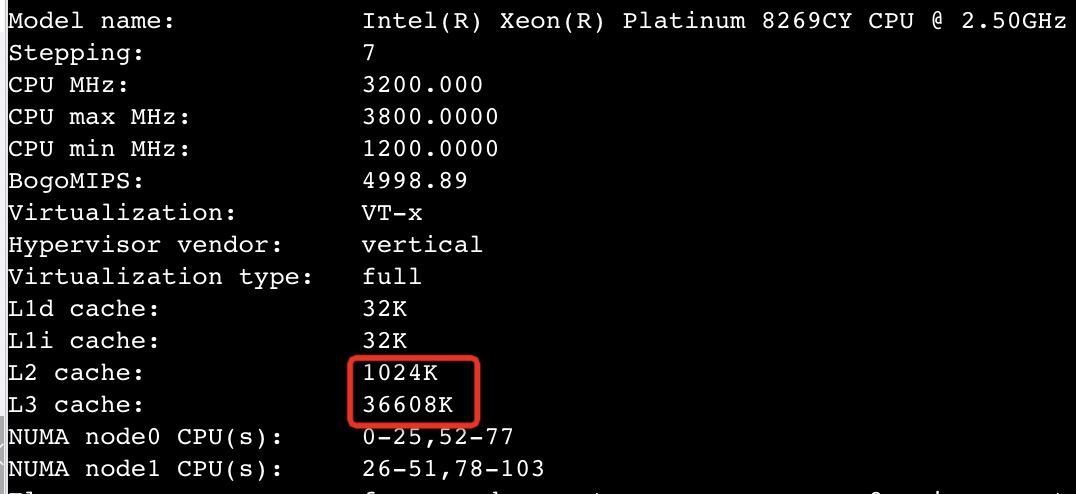
Intel 最新的CPU Ice Lake(8380)和其上一代(8280)的性能对比数据:
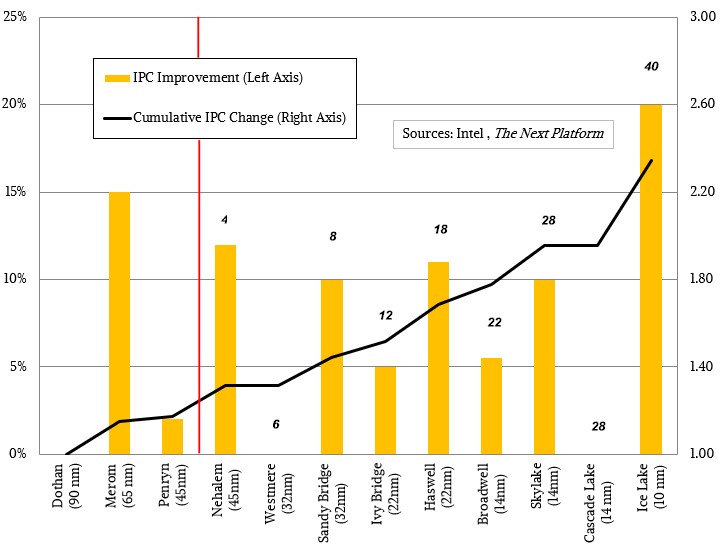
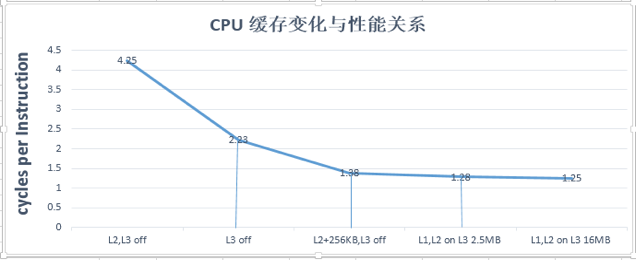
上图最终结果导致了IPC提升了20%
But tock Intel did with the Ice Lake processors and their Sunny Cove cores, and the tock, at 20 percent instructions per clock (IPC) improvement on integer work
The successive nodes of CMOS technologies lead to x1.4 decrease of the gate delays. It led to a 25% increase per year of clock frequencies from 740 kHz (Intel 4004) to 3 GHz (Intel Xeons with 45-nm nodes).
Measuring Peak Injection Memory Bandwidths for the system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using traffic with the following read-write ratios ALL Reads : 232777.7 3:1 Reads-Writes : 216680.7 2:1 Reads-Writes : 213856.4 1:1 Reads-Writes : 197430.7 Stream-triad like: 194310.3
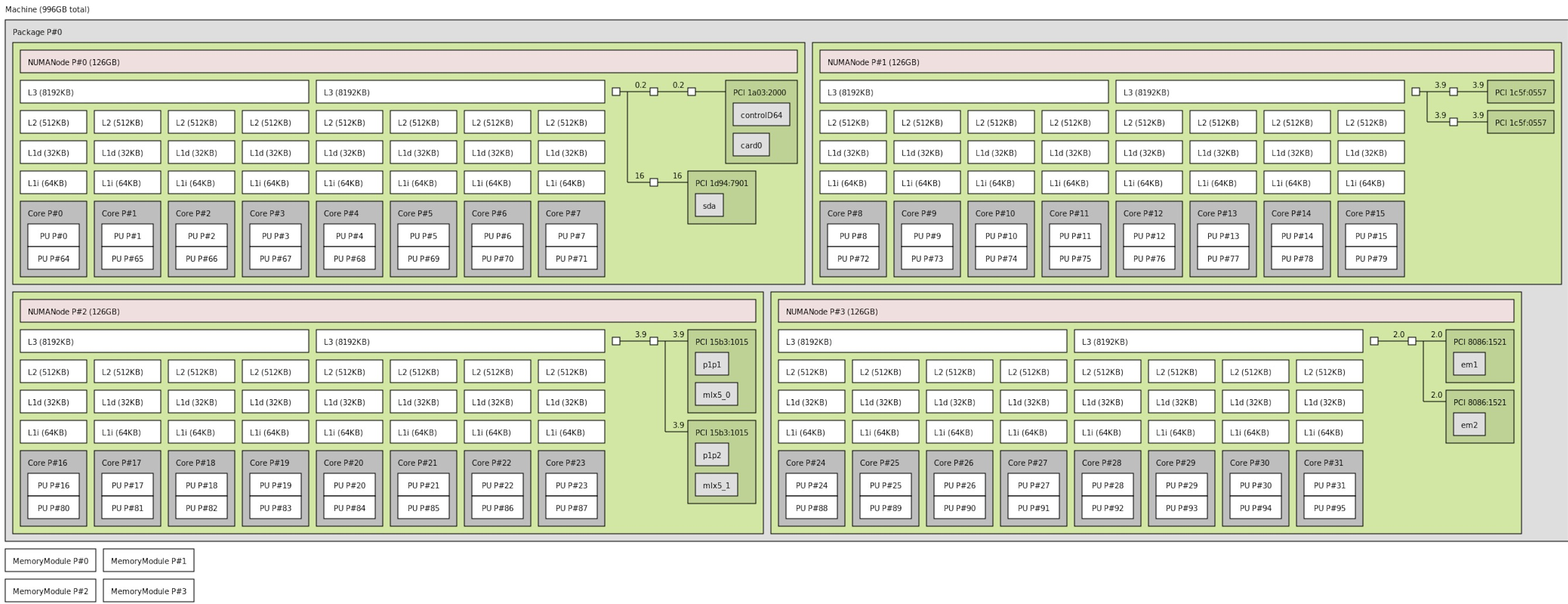
Measuring Memory Bandwidths between nodes within system Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec) Using all the threads from each core if Hyper-threading is enabled Using Read-only traffic type Numa node Numa node 0 1 2 3 0 58908.9 59066.0 50548.0 50479.6 1 59111.3 58882.6 50539.0 50479.3 2 50541.7 50495.8 58950.2 58934.0 3 50526.3 50492.4 59171.9 58701.5
Measuring Loaded Latencies for the system Using all the threads from each core if Hyper-threading is enabled Using Read-only traffic type Inject Latency Bandwidth Delay (ns) MB/sec ========================== 00000 242.78 232249.0 00002 242.90 232248.8 00008 242.63 232226.0 00015 247.47 233159.0 00050 250.26 233489.7 00100 245.88 233253.4 00200 109.72 183071.9 00300 93.95 128676.2 00400 88.51 98678.4 00500 85.15 80026.2 00700 83.74 58136.1 01000 82.16 41372.4 01300 81.59 32184.0 01700 81.14 24896.1 02500 80.80 17248.5 03500 80.32 12571.3 05000 79.58 9060.5 09000 78.27 5411.6 20000 76.09 2911.5
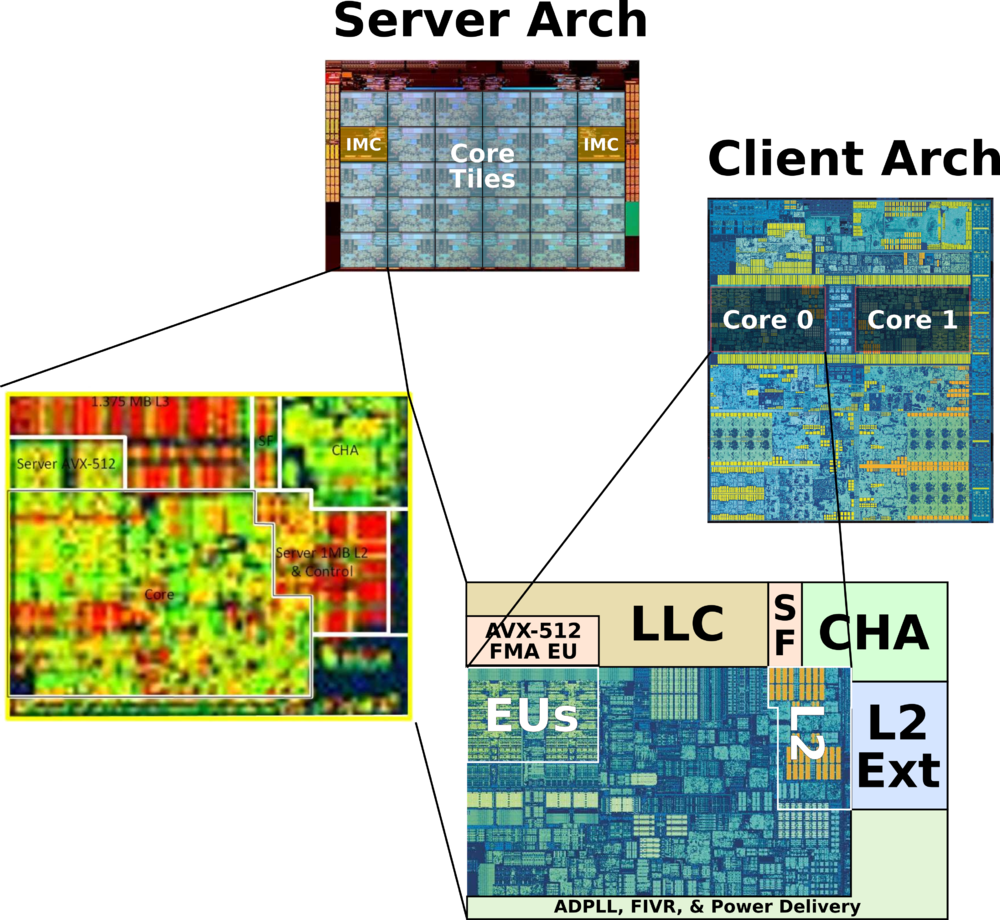
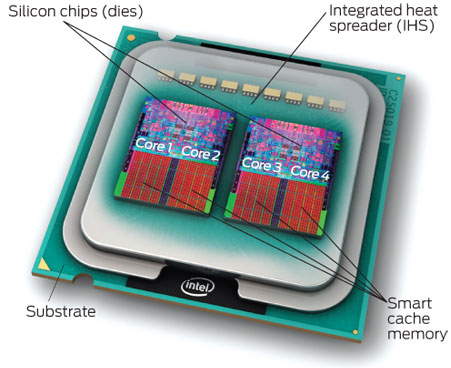
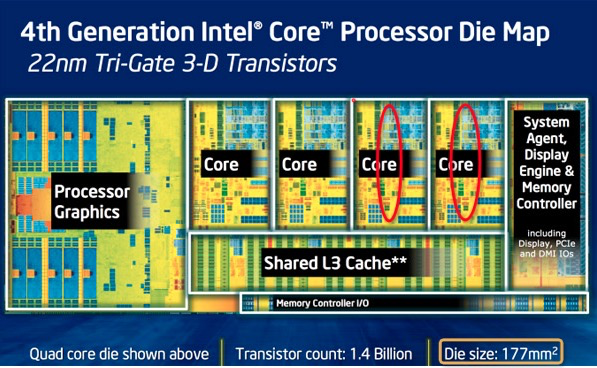
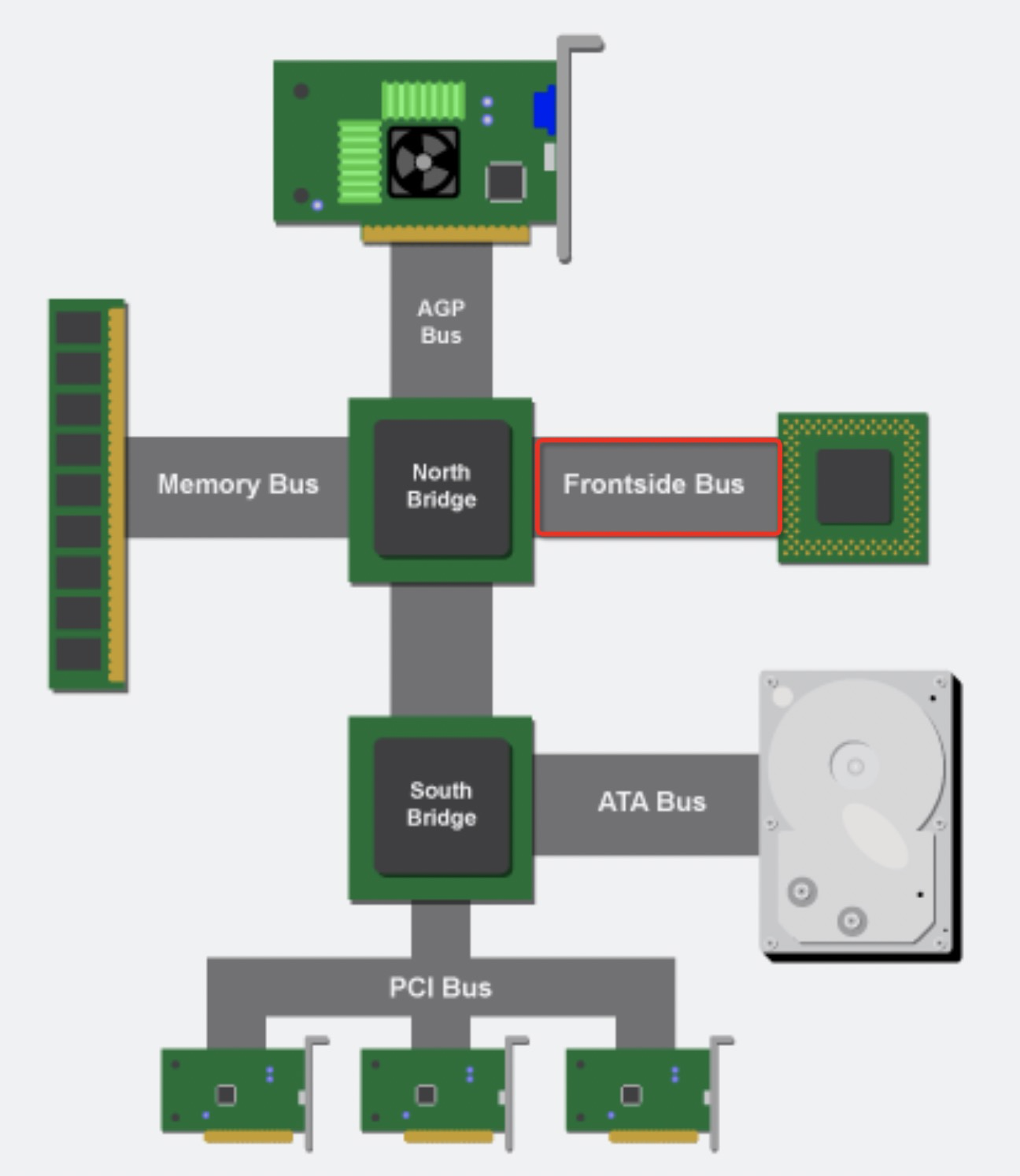
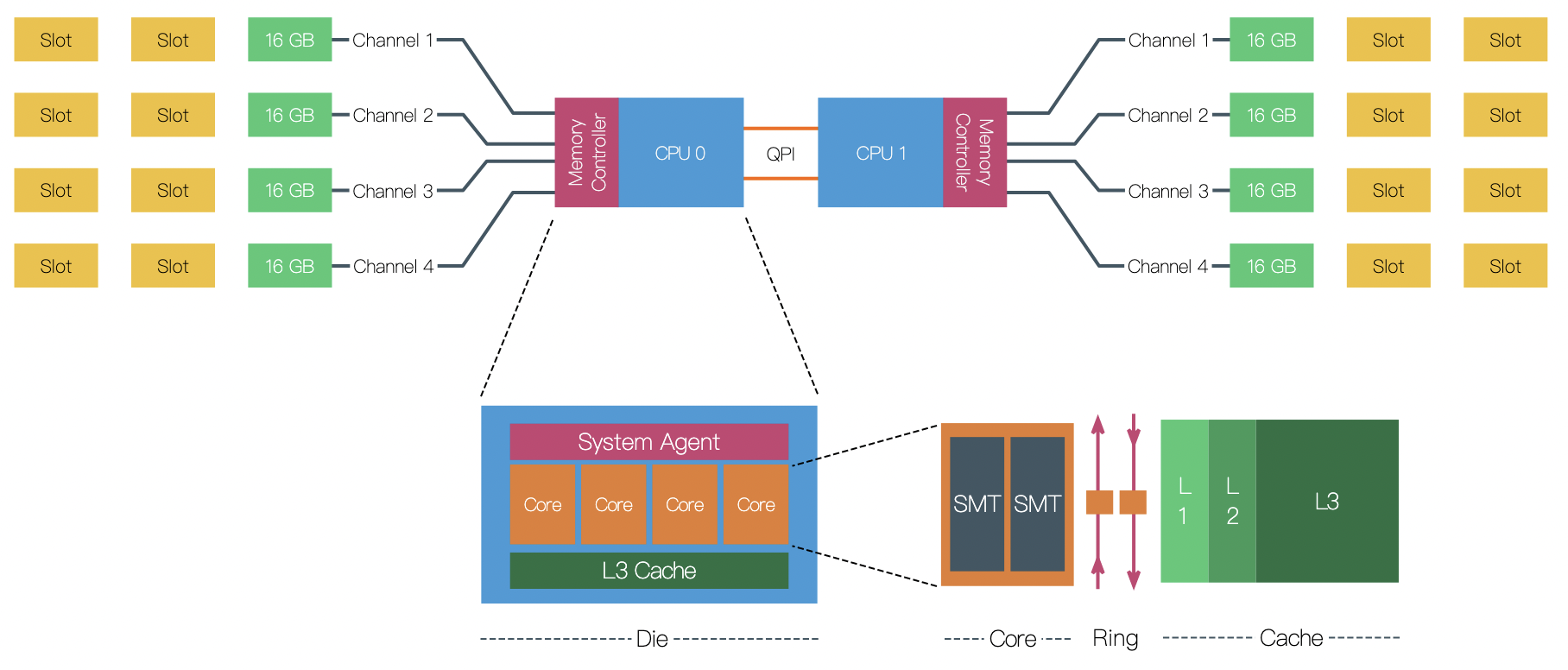
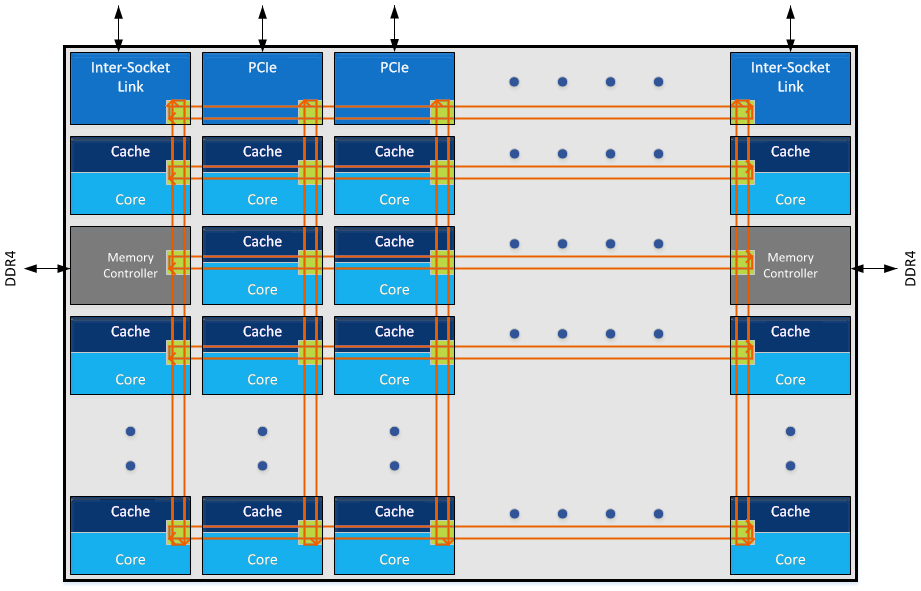
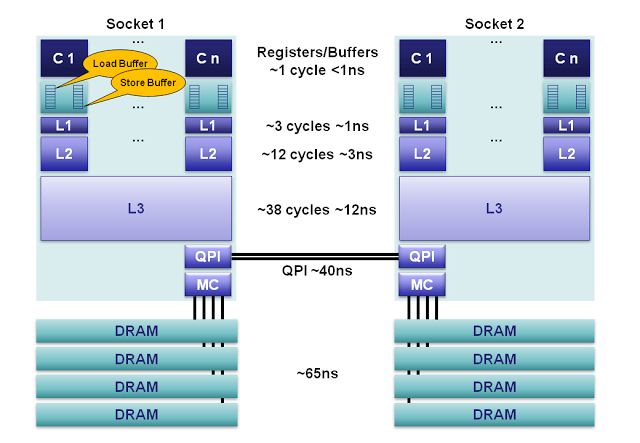
“Uncore“ is a term used by Intel to describe the functions of a microprocessor that are not in the core, but which must be closely connected to the core to achieve high performance.[1] It has been called “system agent“ since the release of the Sandy Bridgemicroarchitecture.[2]
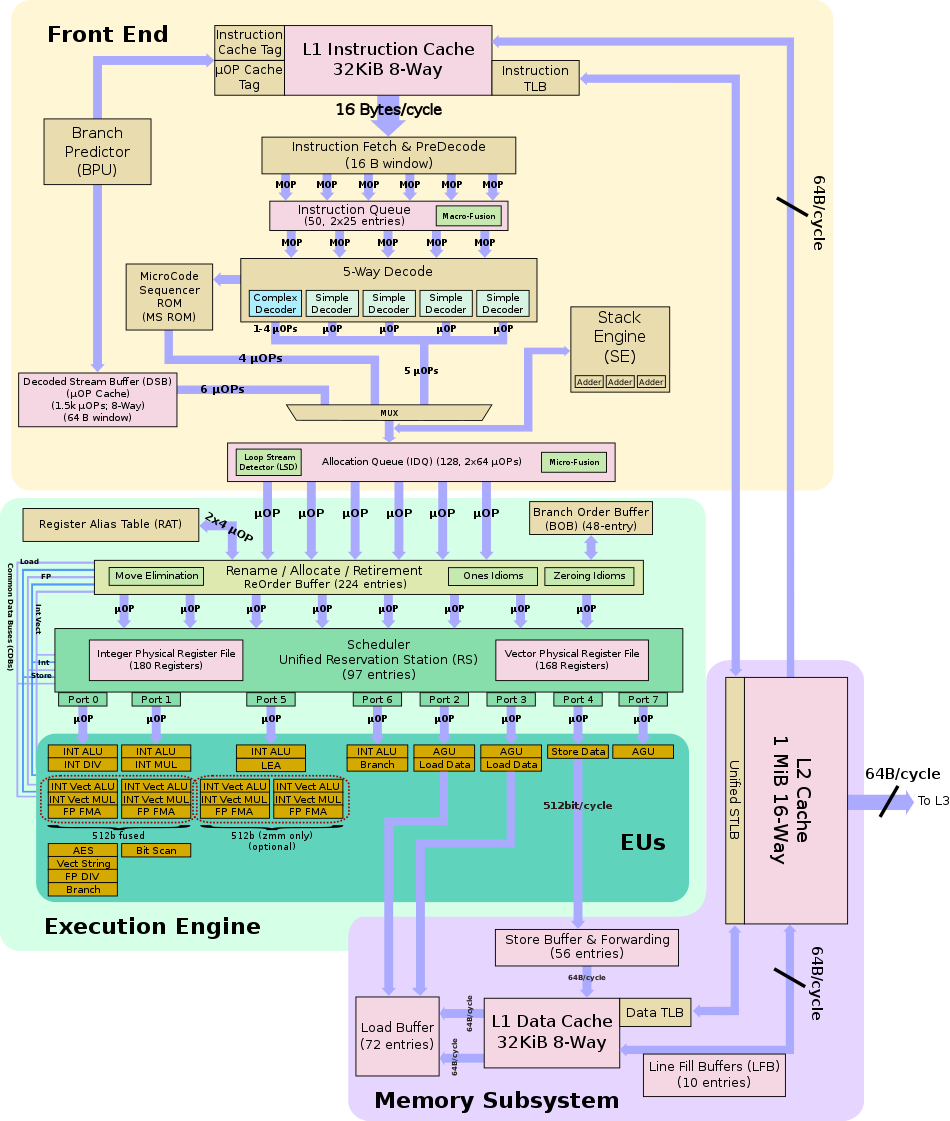
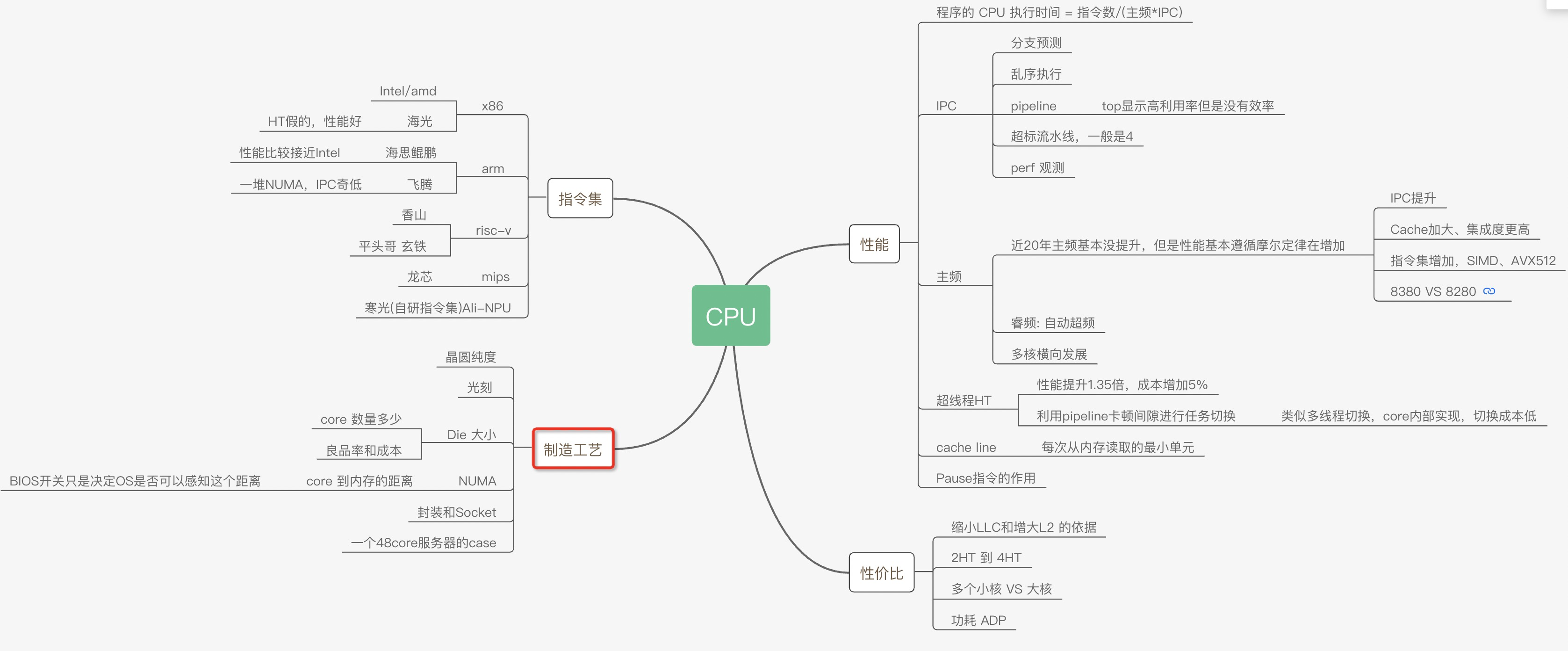
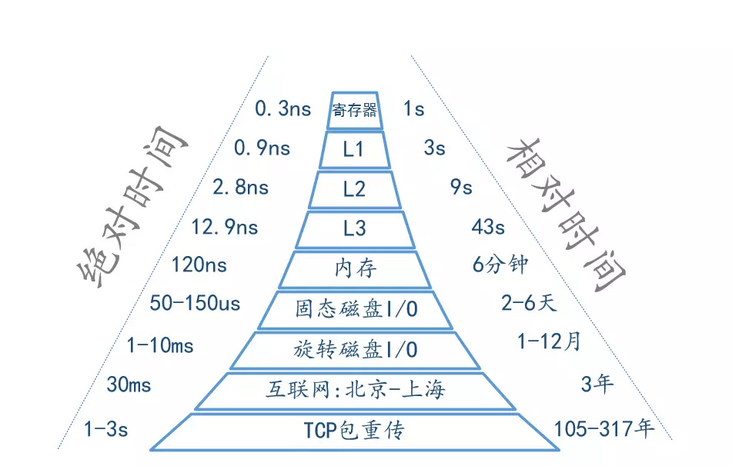
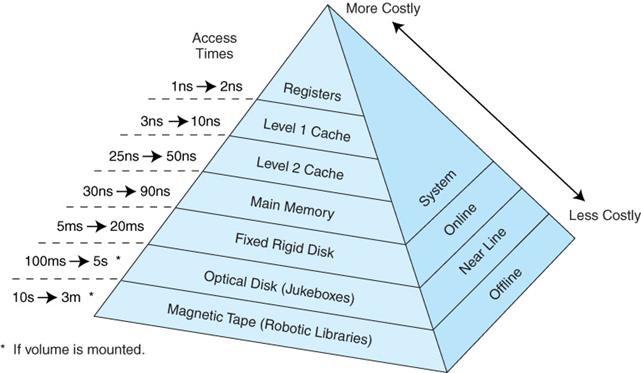
从最简单的单指令周期 CPU 来说,其实时钟周期应该是放下最复杂的一条指令的时间长度。但是,我们现在实际用的都没有单指令周期 CPU 了,而是采用了流水线技术。采用了流水线技术之后,单个时钟周期里面,能够执行的就不是一个指令了。我们会把一条机器指令,拆分成很多个小步骤。不同的指令的步骤数量可能还不一样。不同的步骤的执行时间,也不一样。所以,一个时钟周期里面,能够放下的是最耗时间的某一个指令步骤。
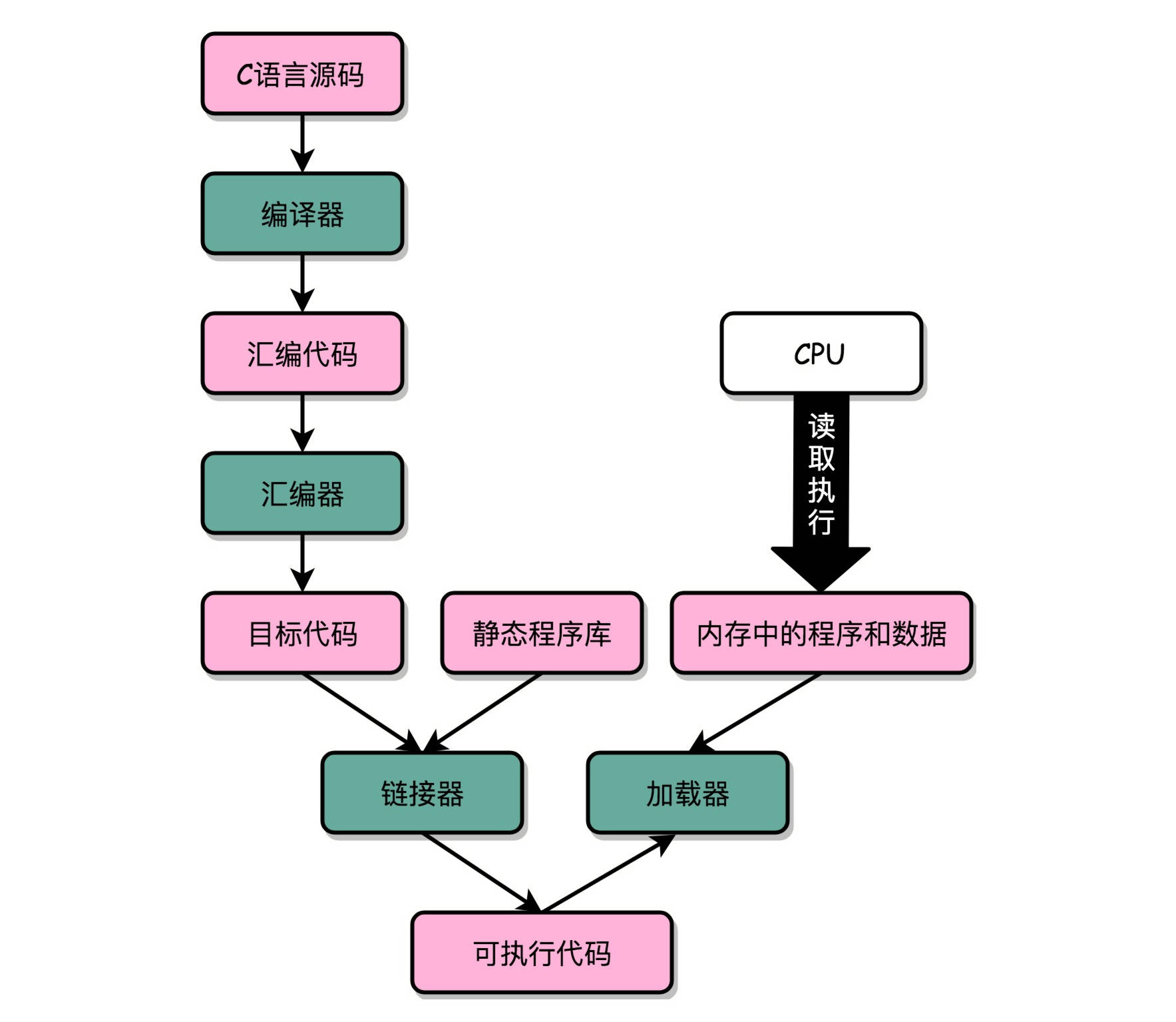
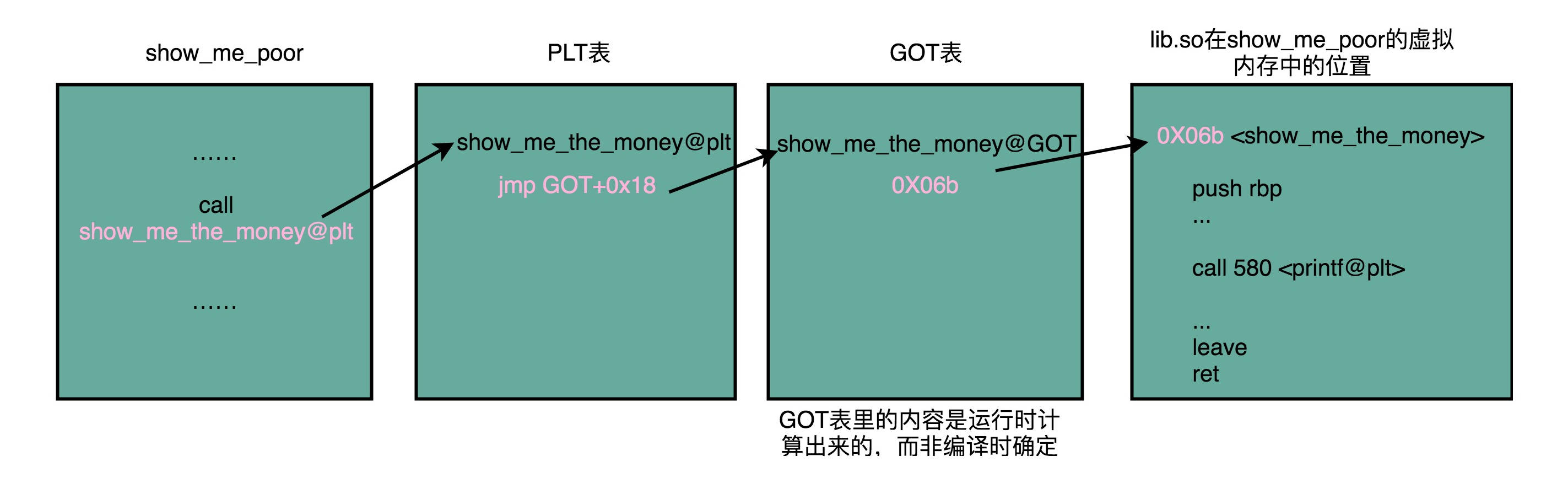
共享库:在 Windows 下,这些共享库文件就是.dll 文件,也就是 Dynamic-Link Libary(DLL,动态链接库)。在 Linux 下,这些共享库文件就是.so 文件,也就是 Shared Object(一般我们也称之为动态链接库). 不同的进程,调用同样的 lib.so,各自 全局偏移表(GOT,Global Offset Table) 里面指向最终加载的动态链接库里面的虚拟内存地址是不同的, 各个程序各自维护好自己的 GOT,能够找到对应的动态库就好了, 有点像函数指针。
符号表:/boot/System.map 和 /proc/kallsyms
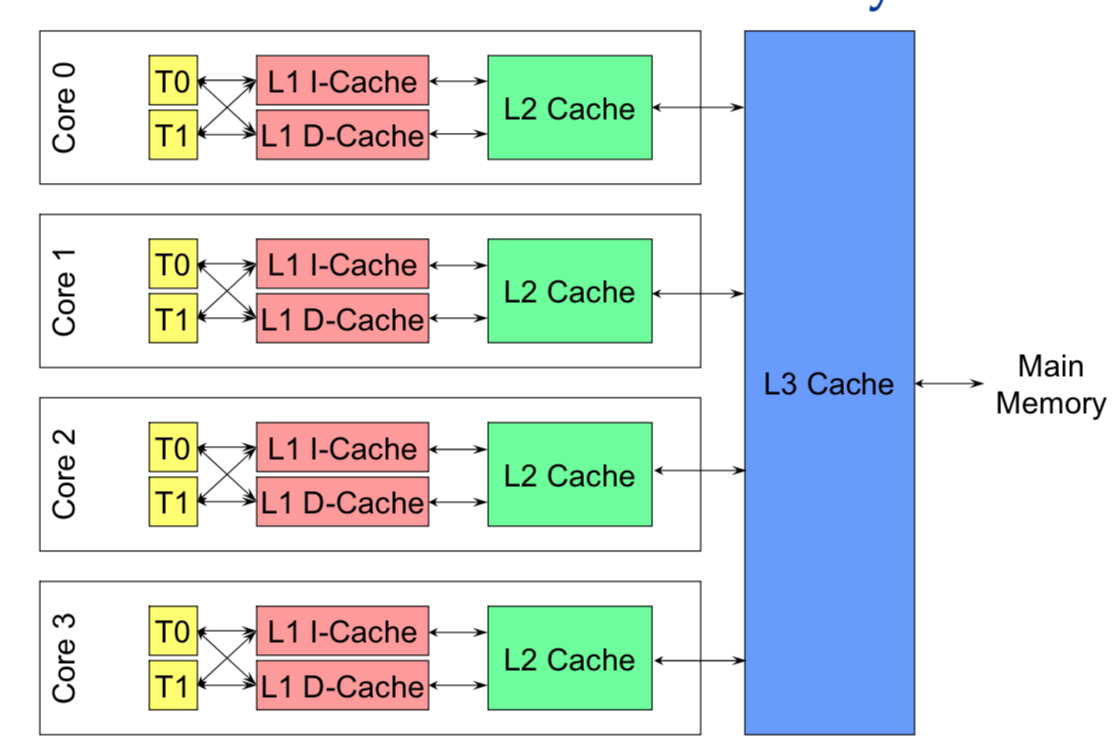
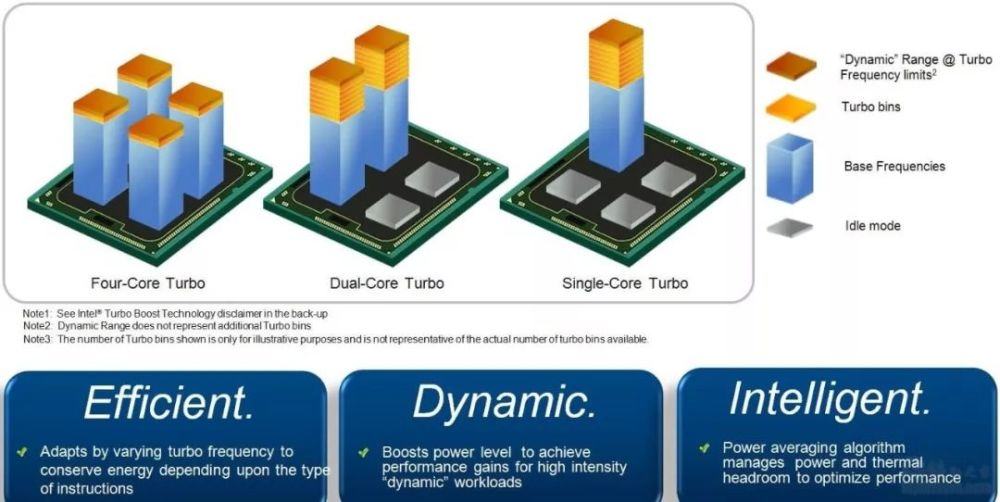
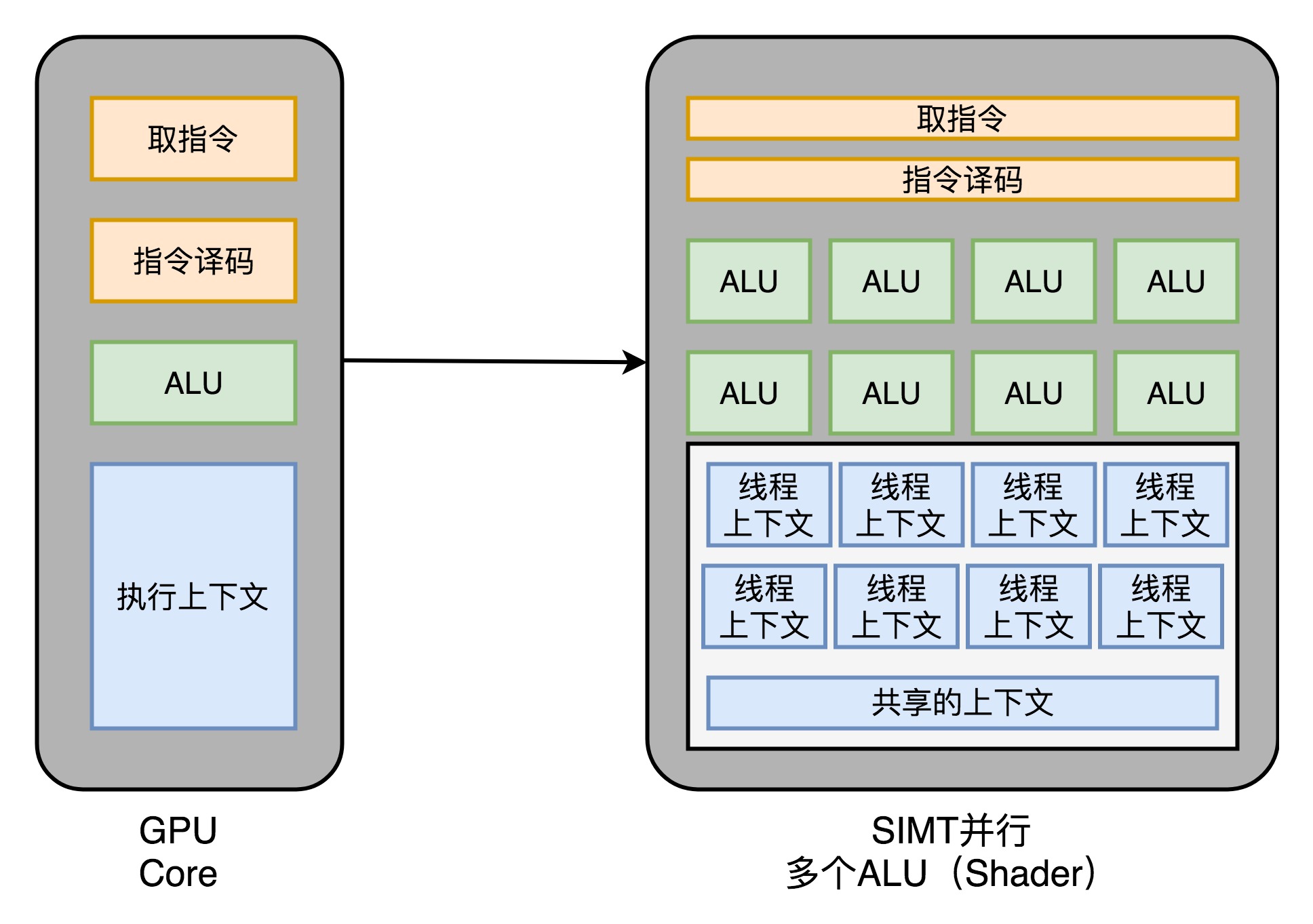
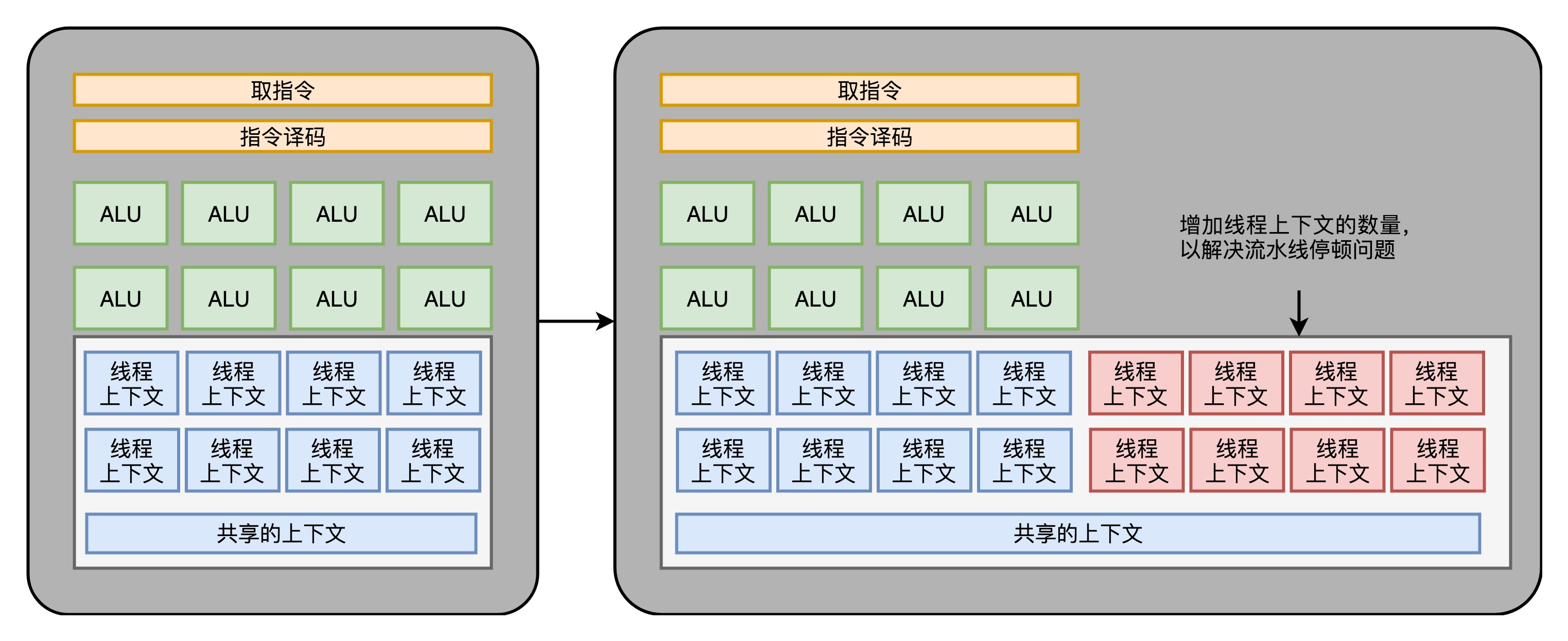
超线程(Hyper-Threading): 在CPU内部增加寄存器等硬件设施,但是ALU、译码器等关键单元还是共享。在一个物理 CPU 核心内部,会有双份的 PC 寄存器、指令寄存器乃至条件码寄存器。超线程的目的,是在一个线程 A 的指令,在流水线里停顿的时候,让另外一个线程去执行指令。因为这个时候,CPU 的译码器和 ALU 就空出来了,那么另外一个线程 B,就可以拿来干自己需要的事情。这个线程 B 可没有对于线程 A 里面指令的关联和依赖。
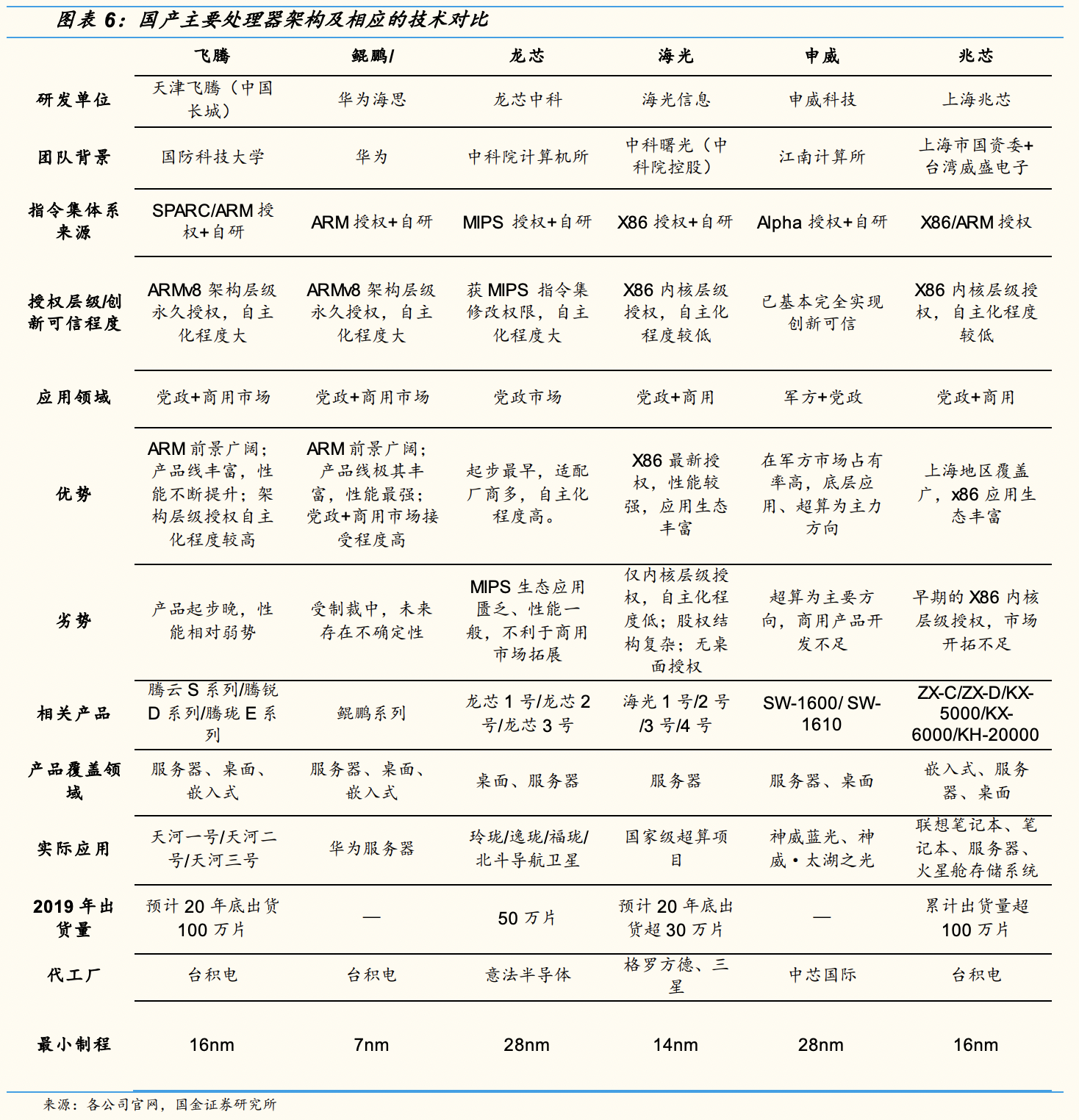



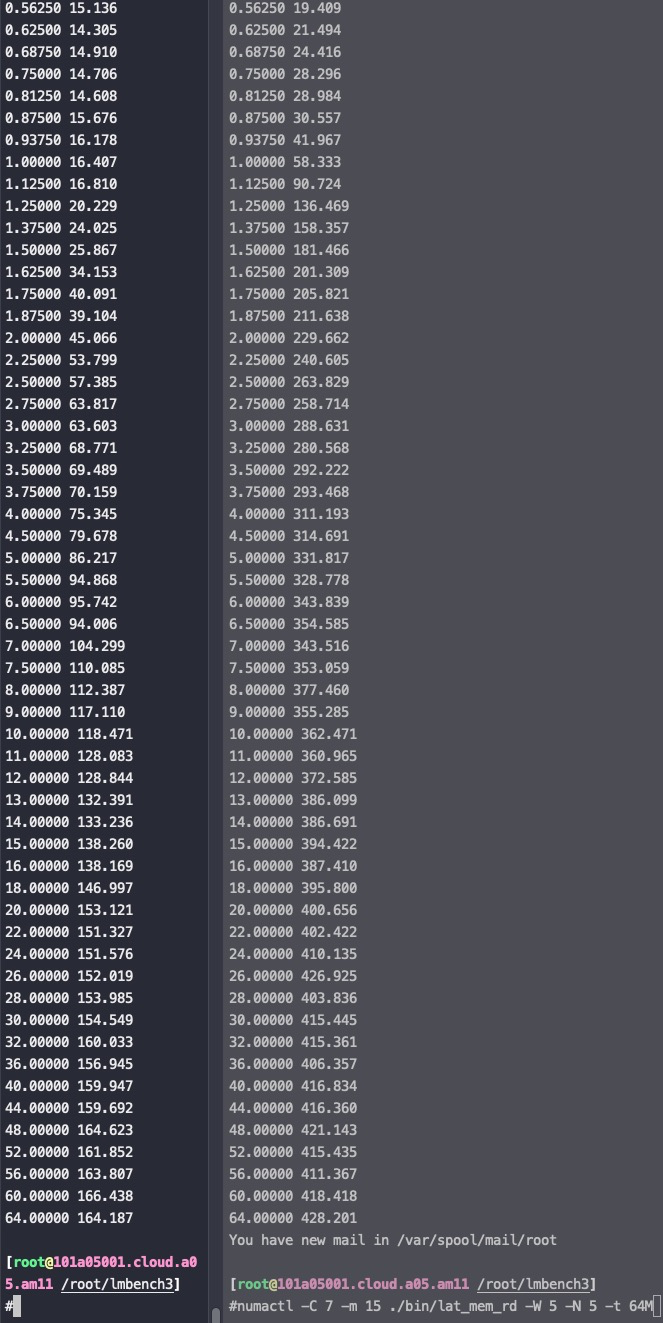


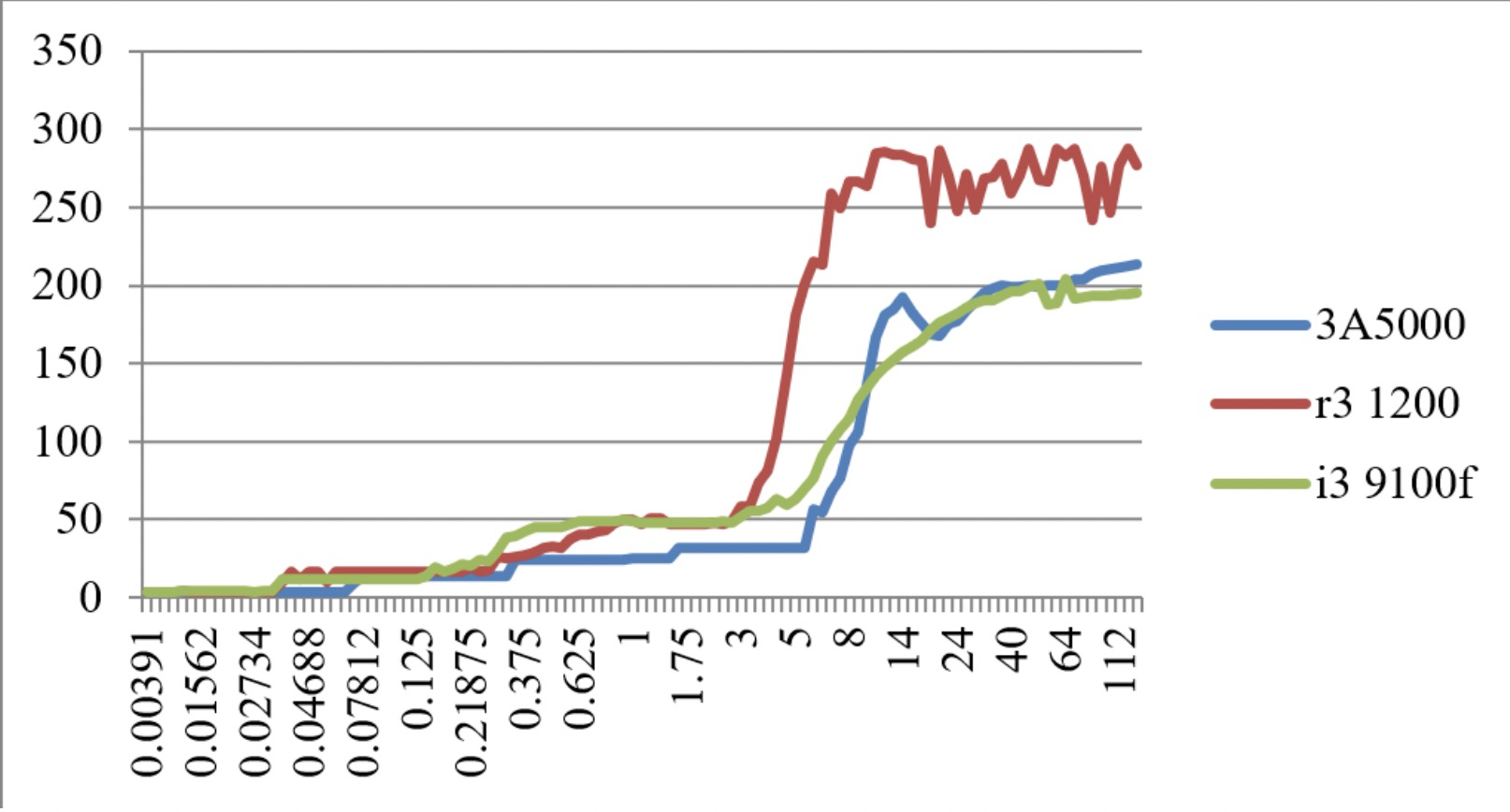
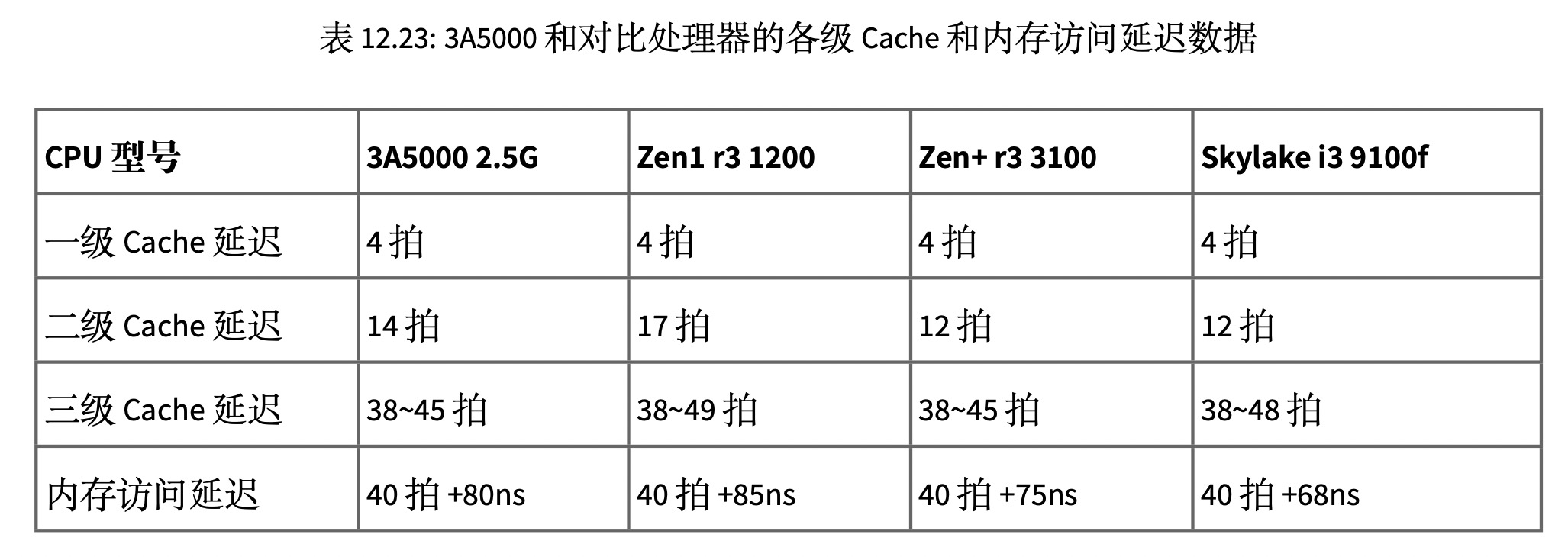
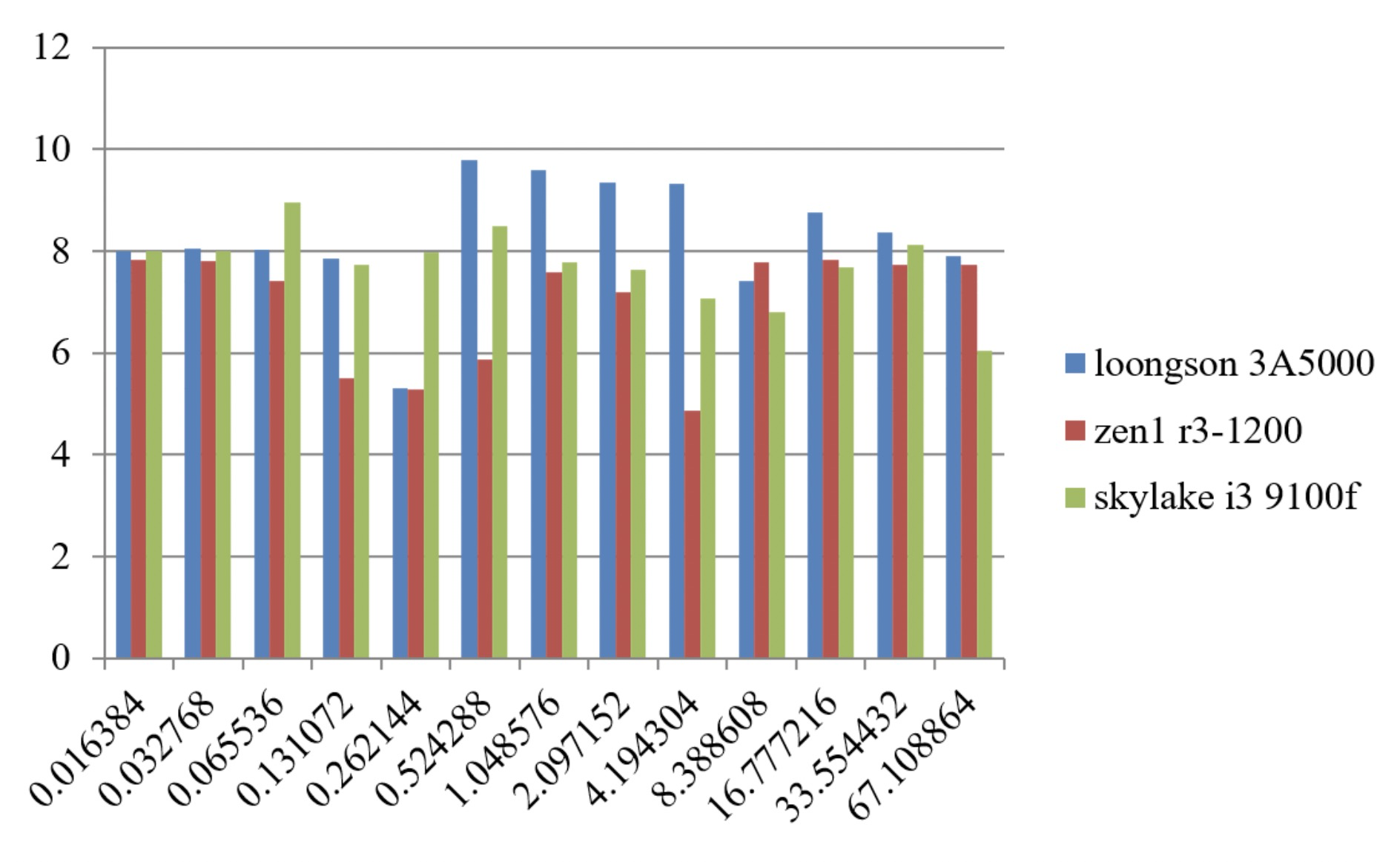







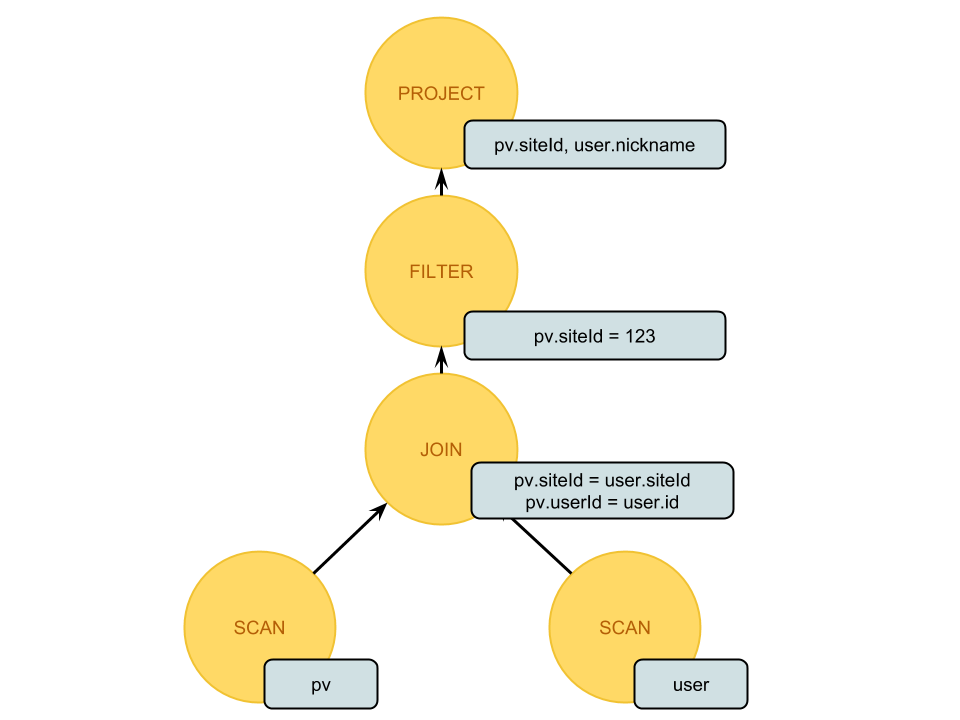






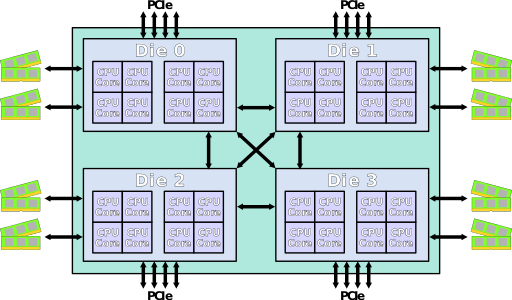
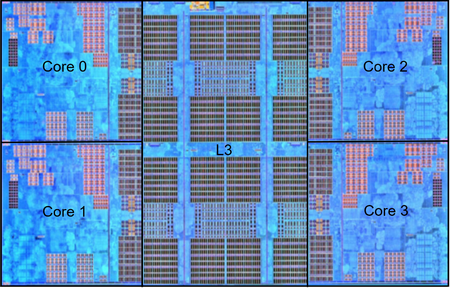
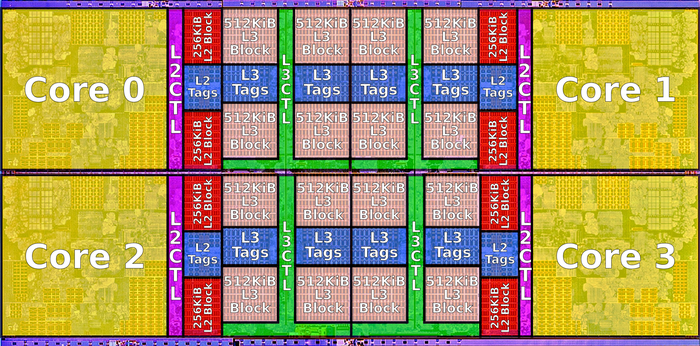
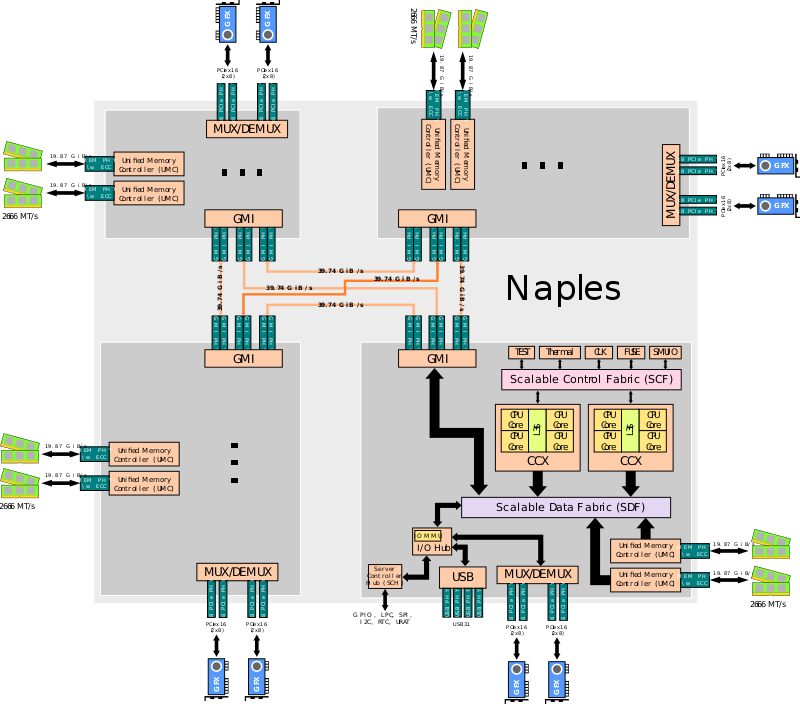
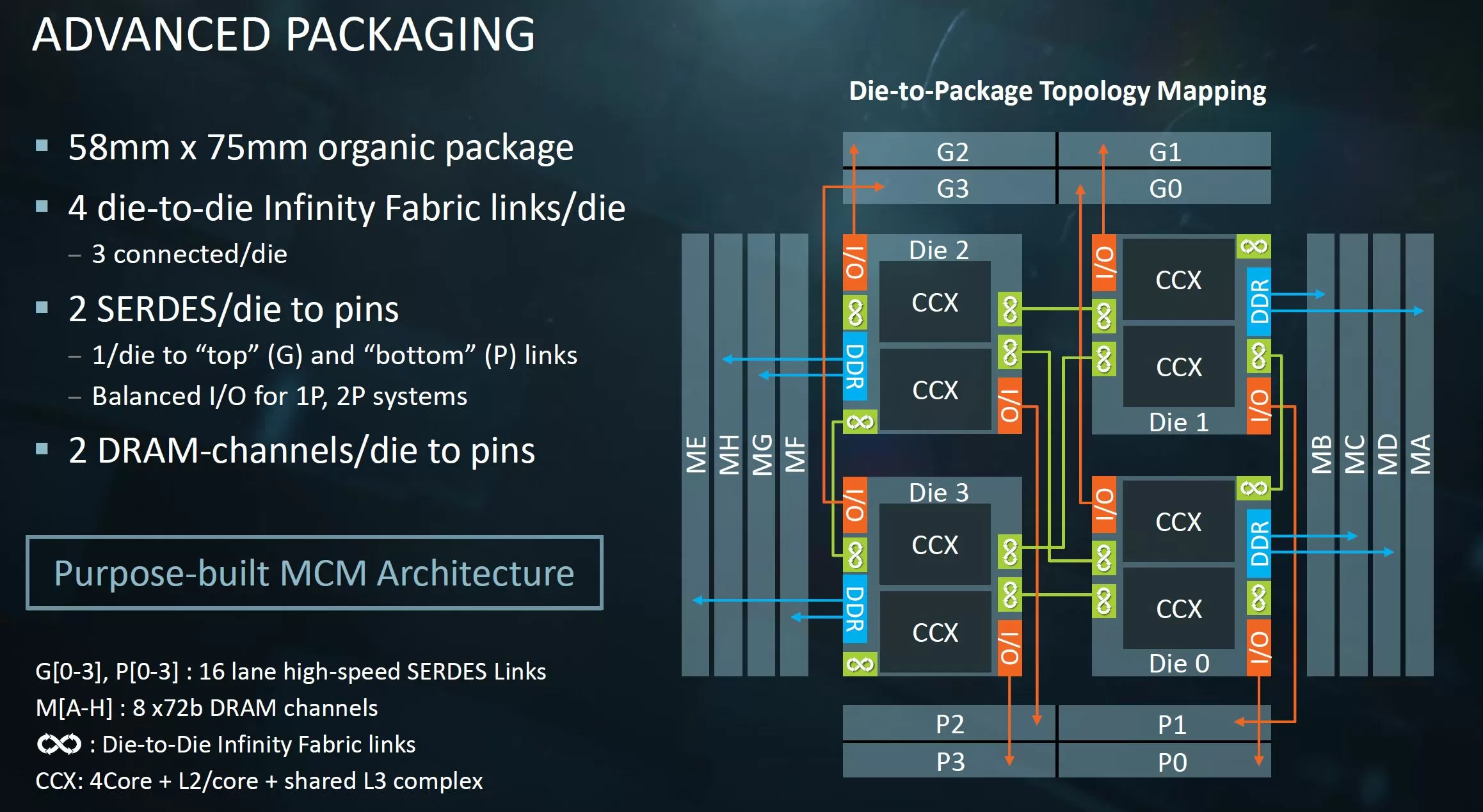

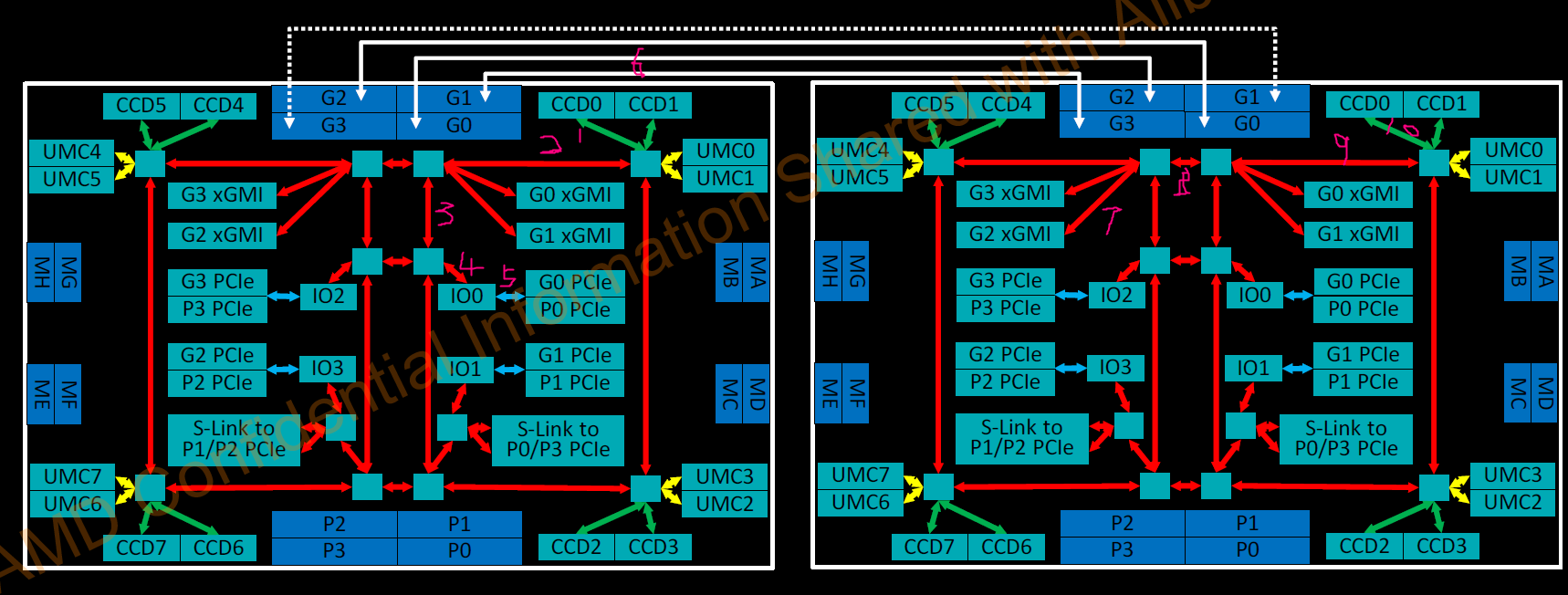

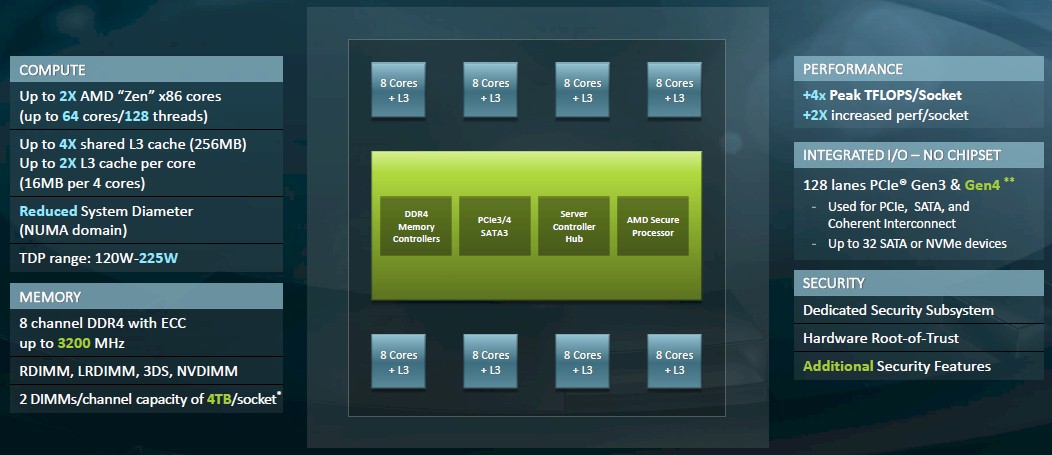
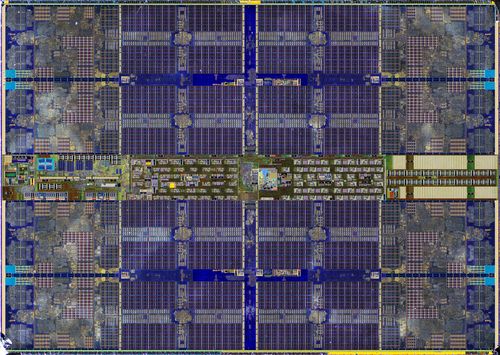

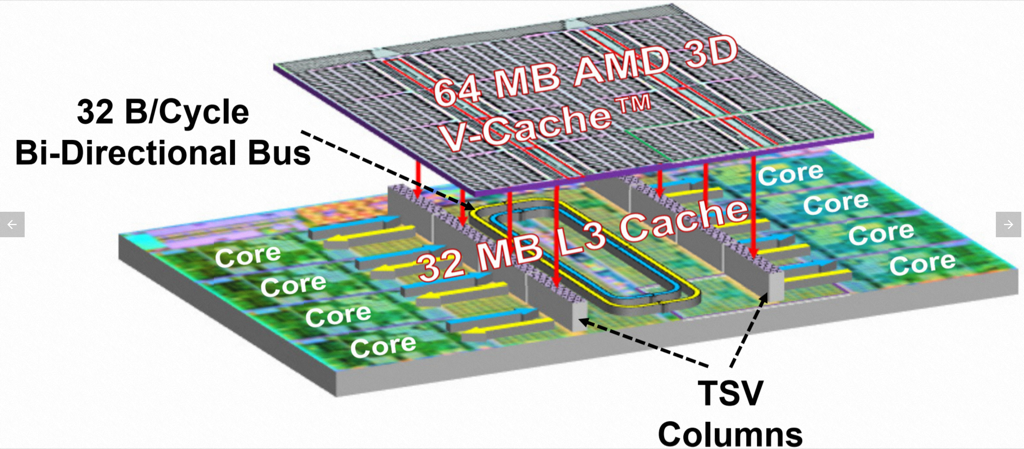
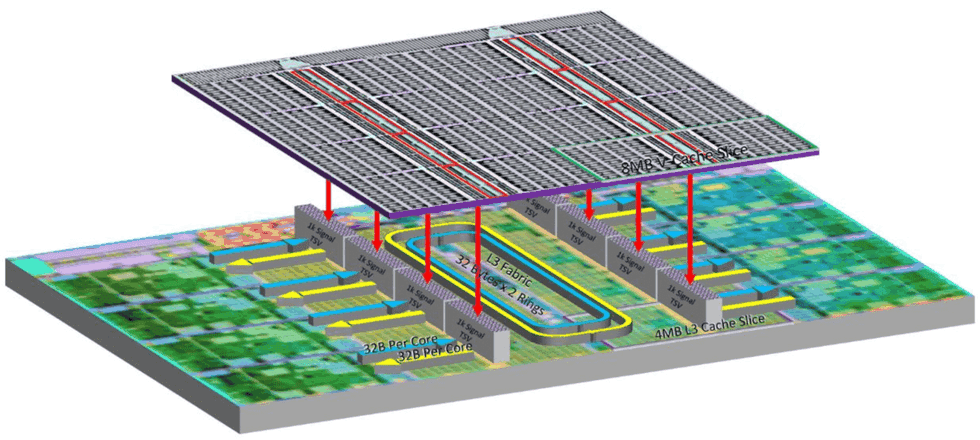
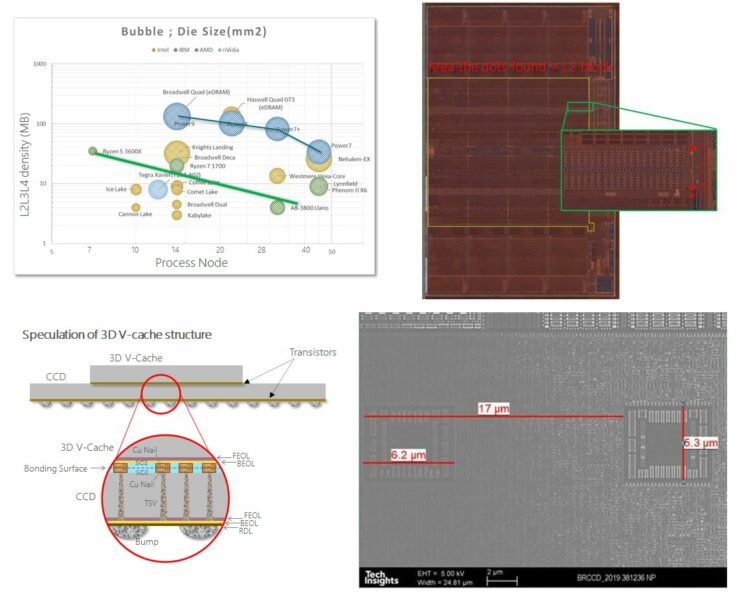
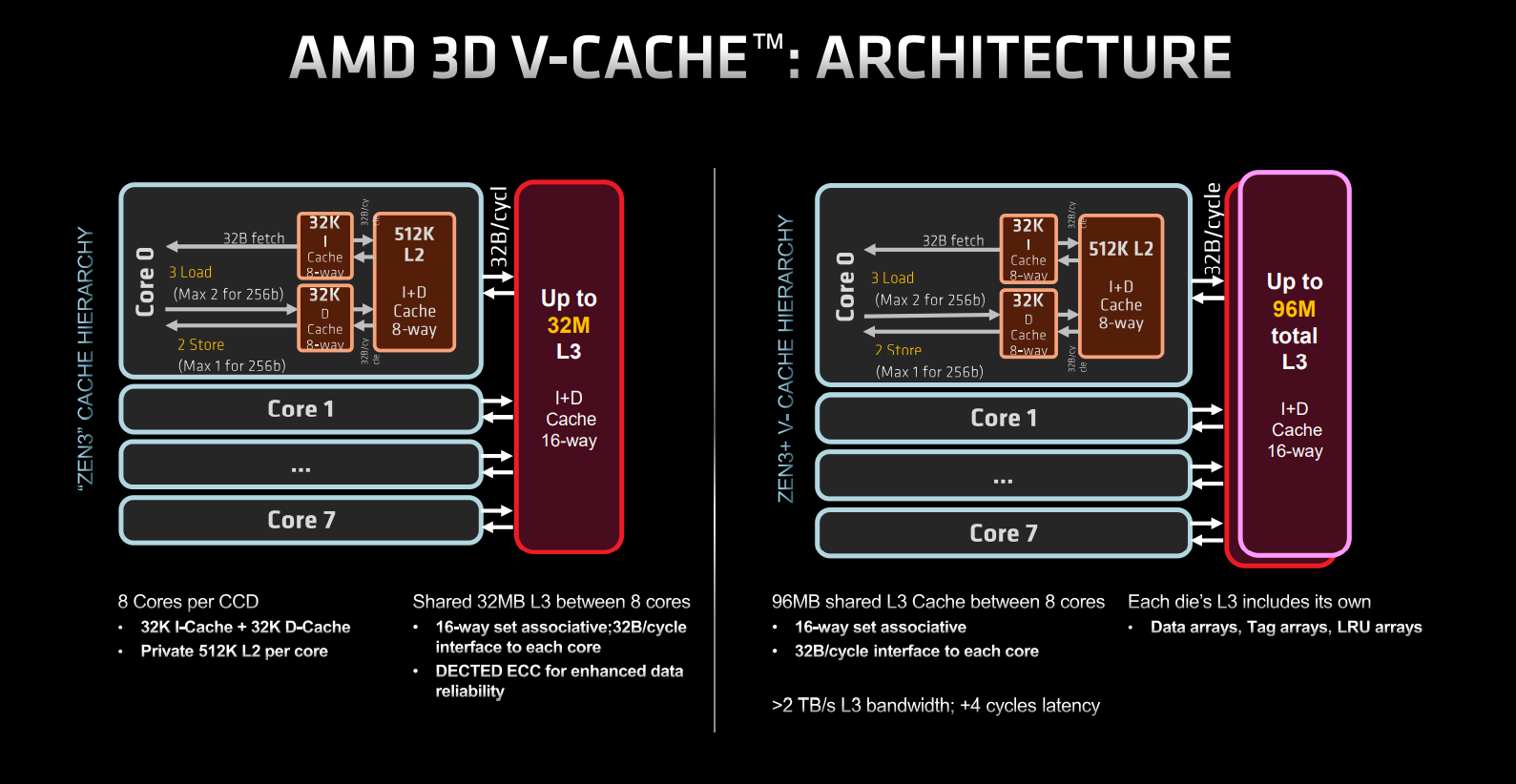

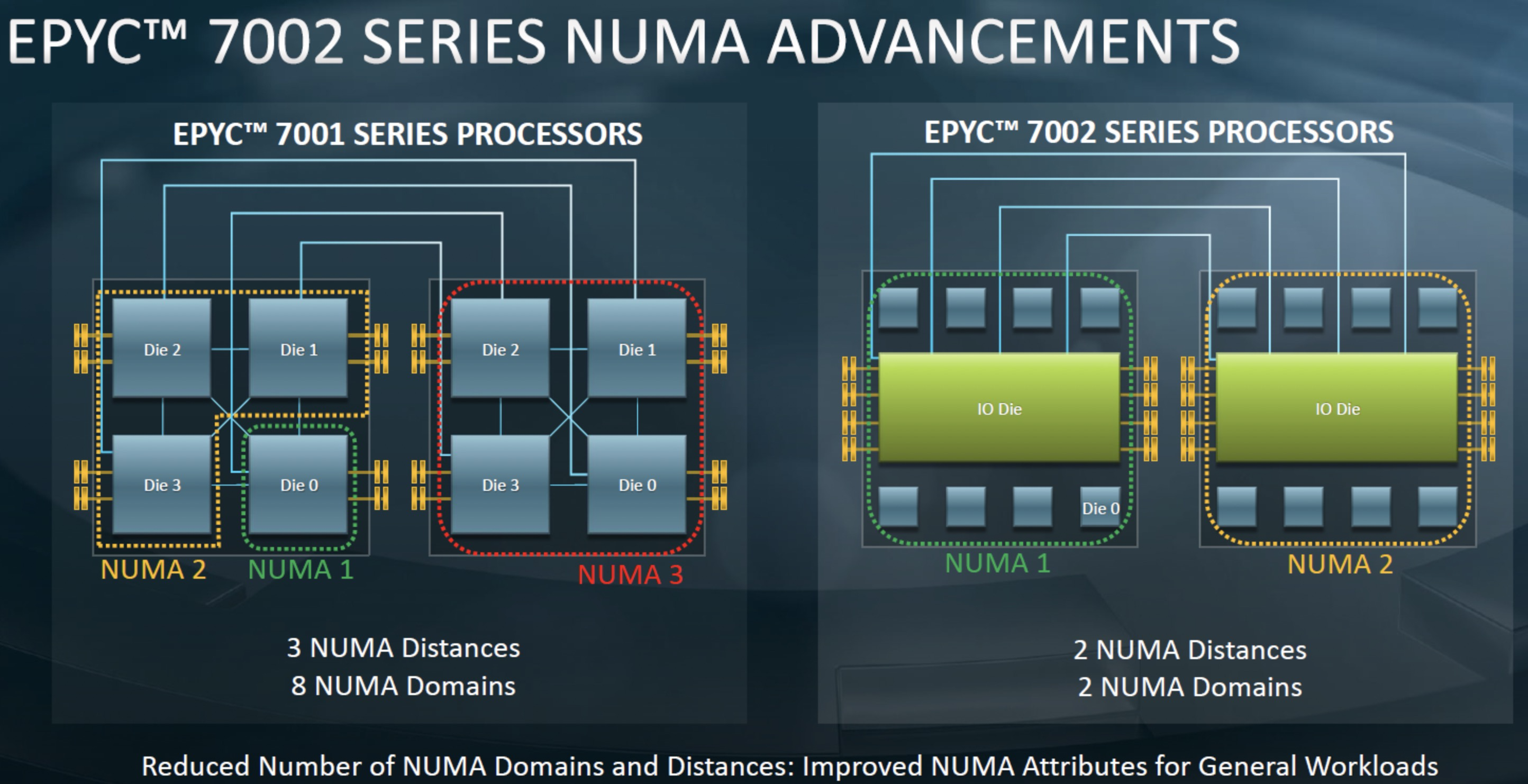
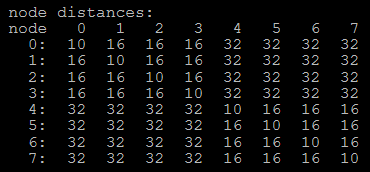
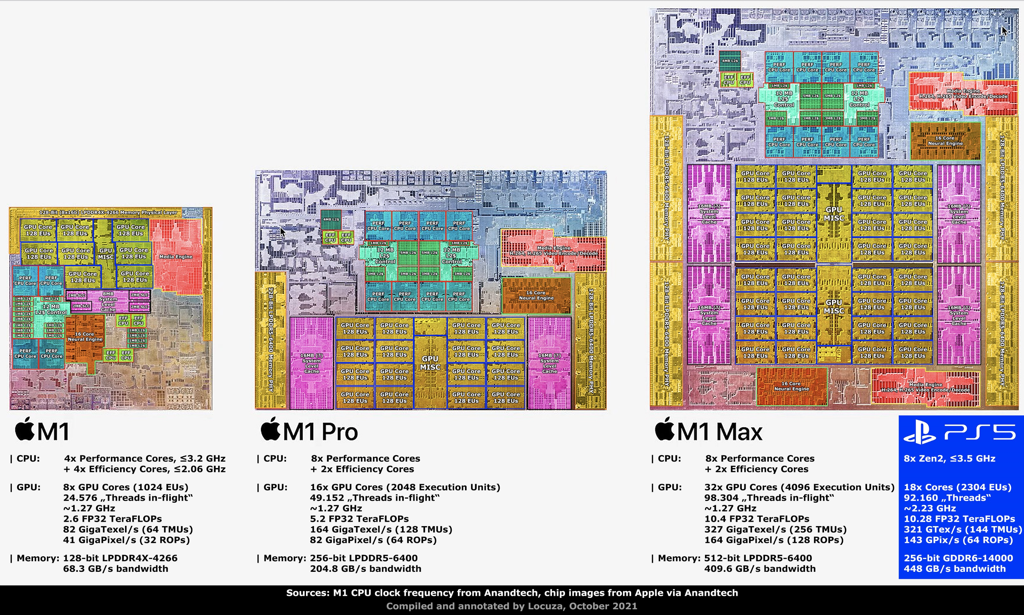



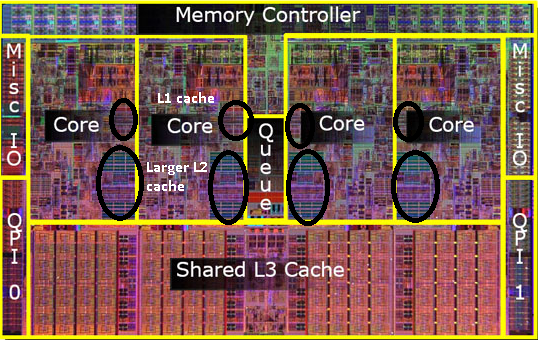
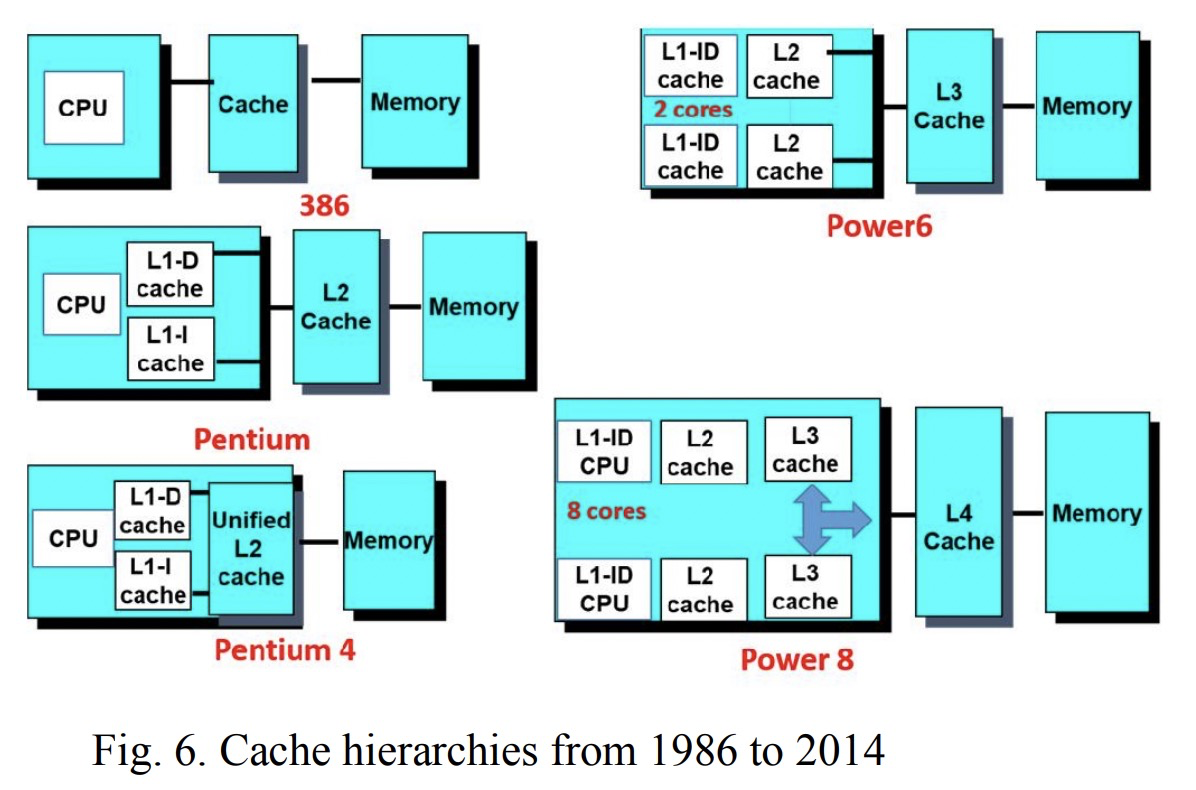
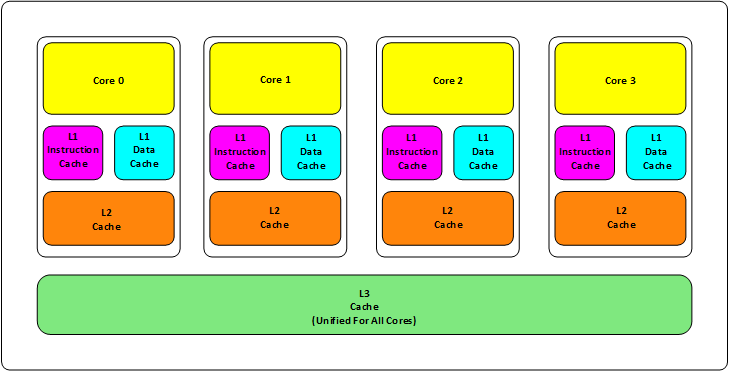
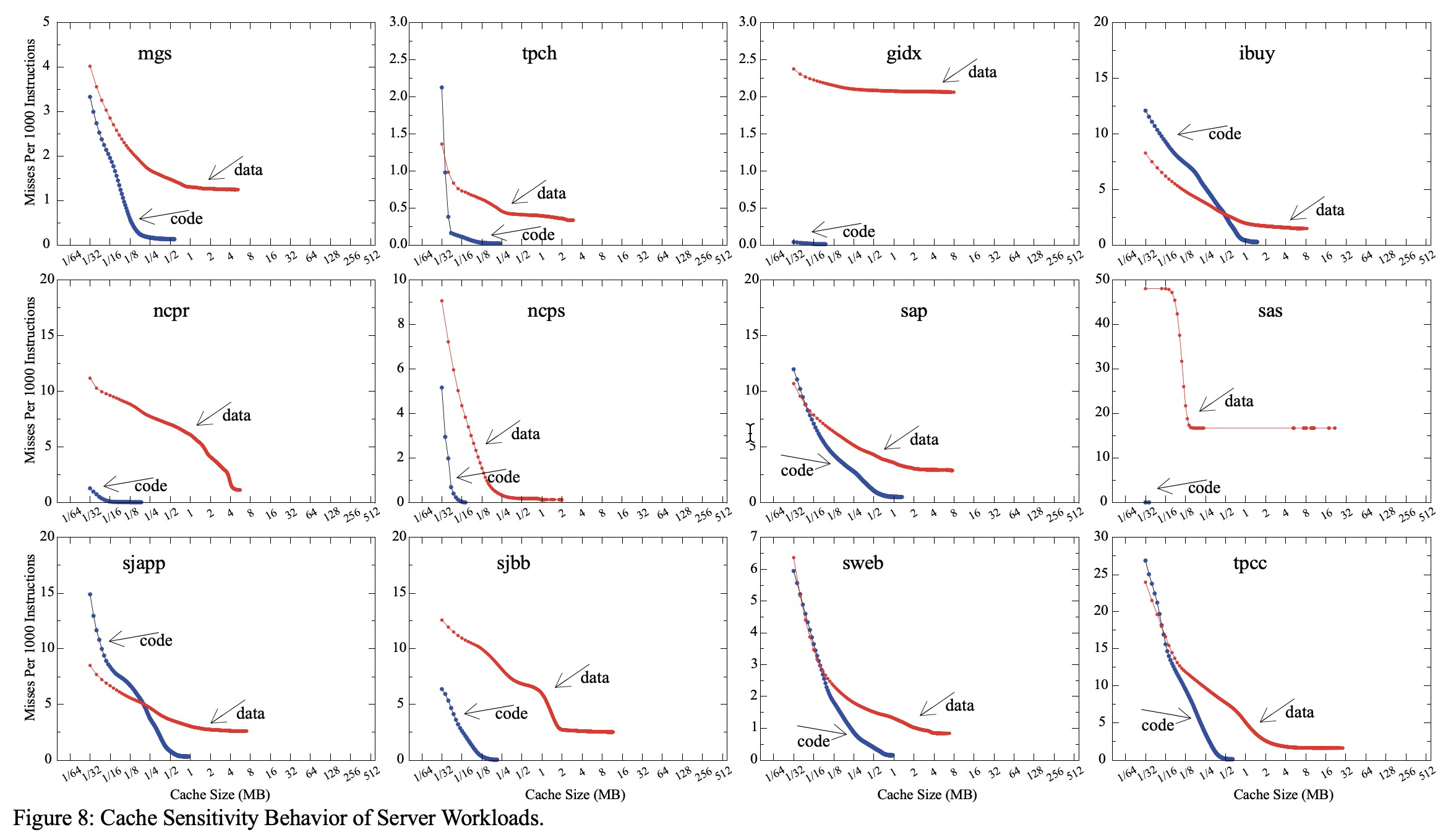
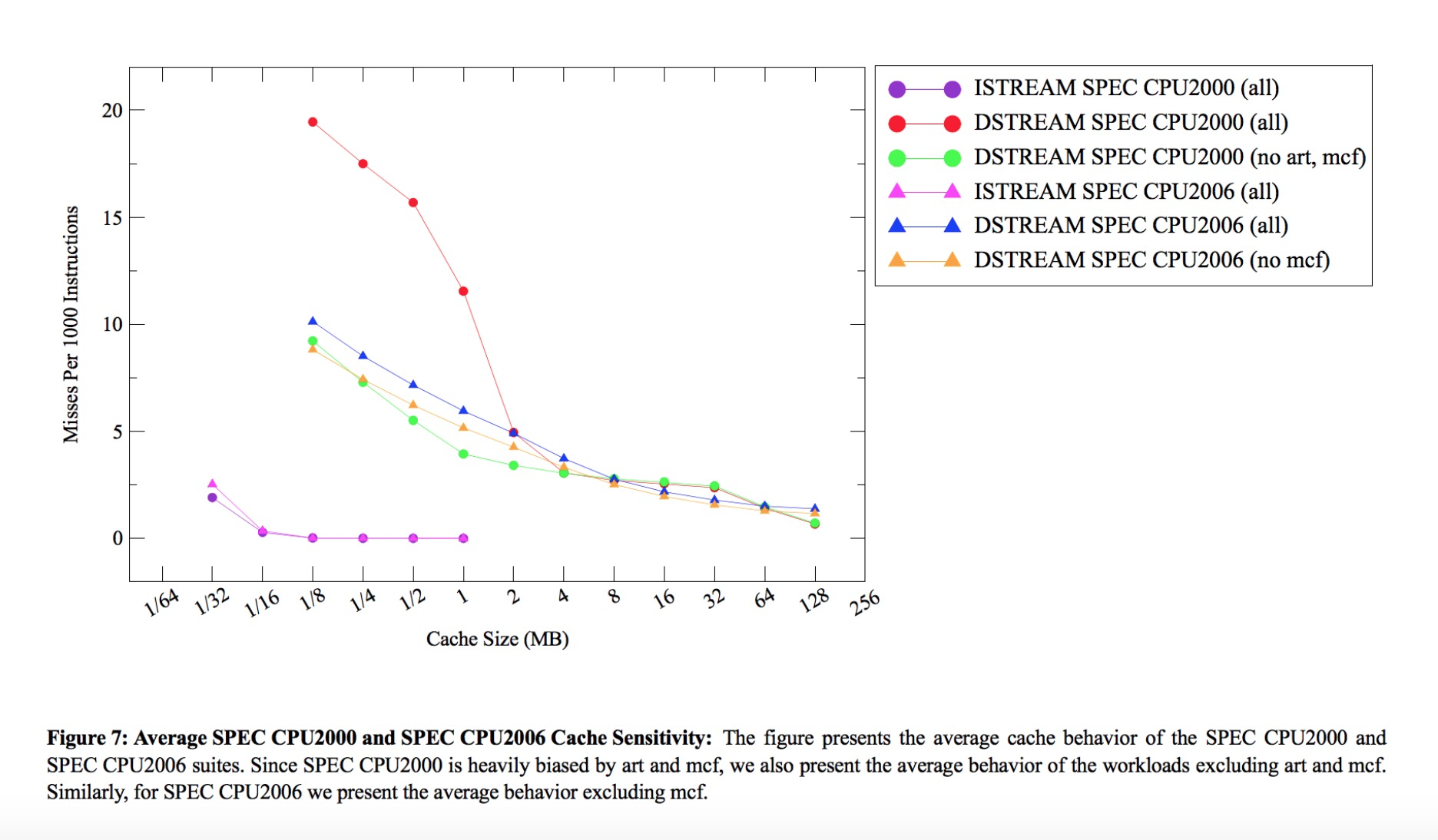

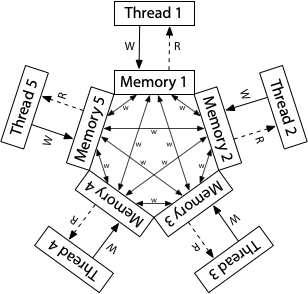

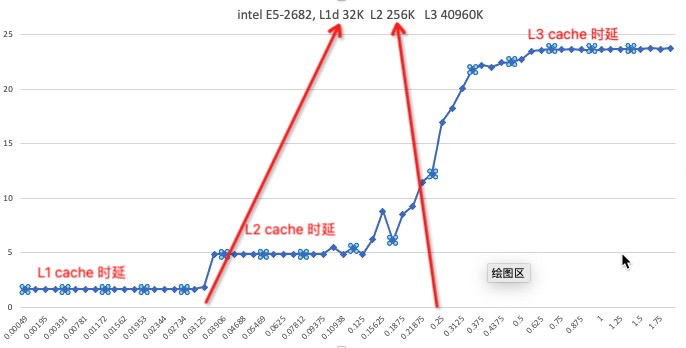

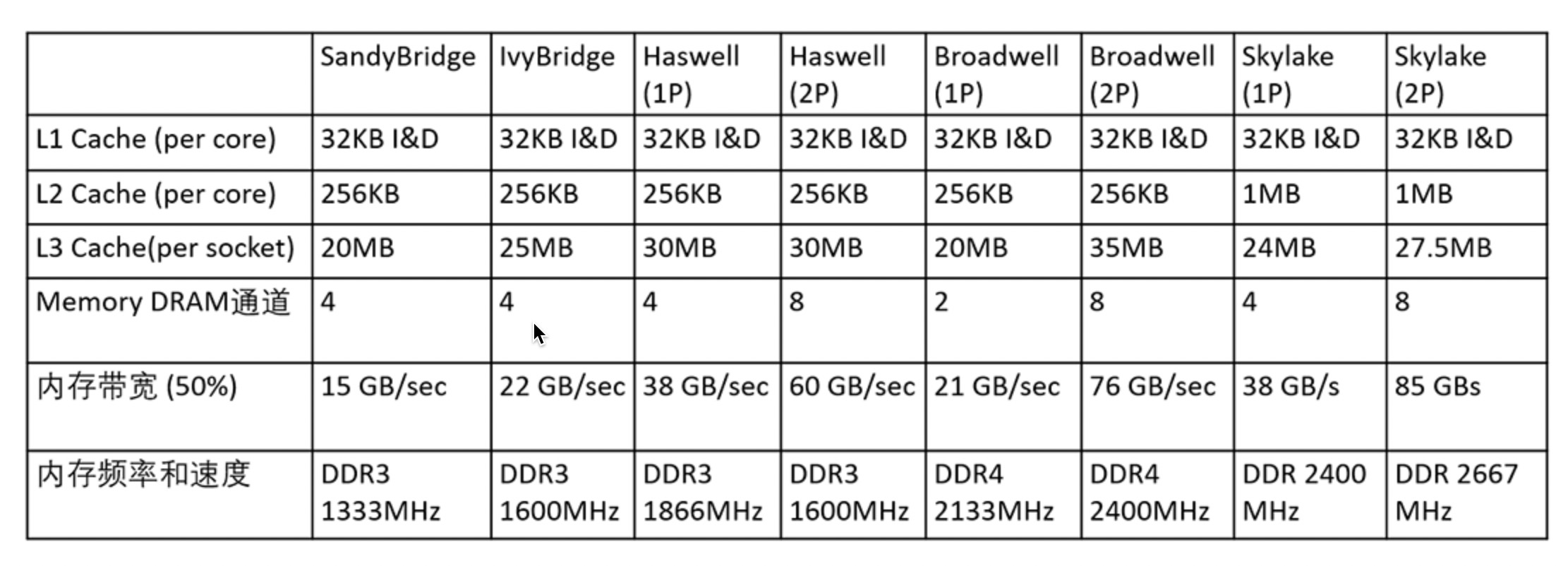
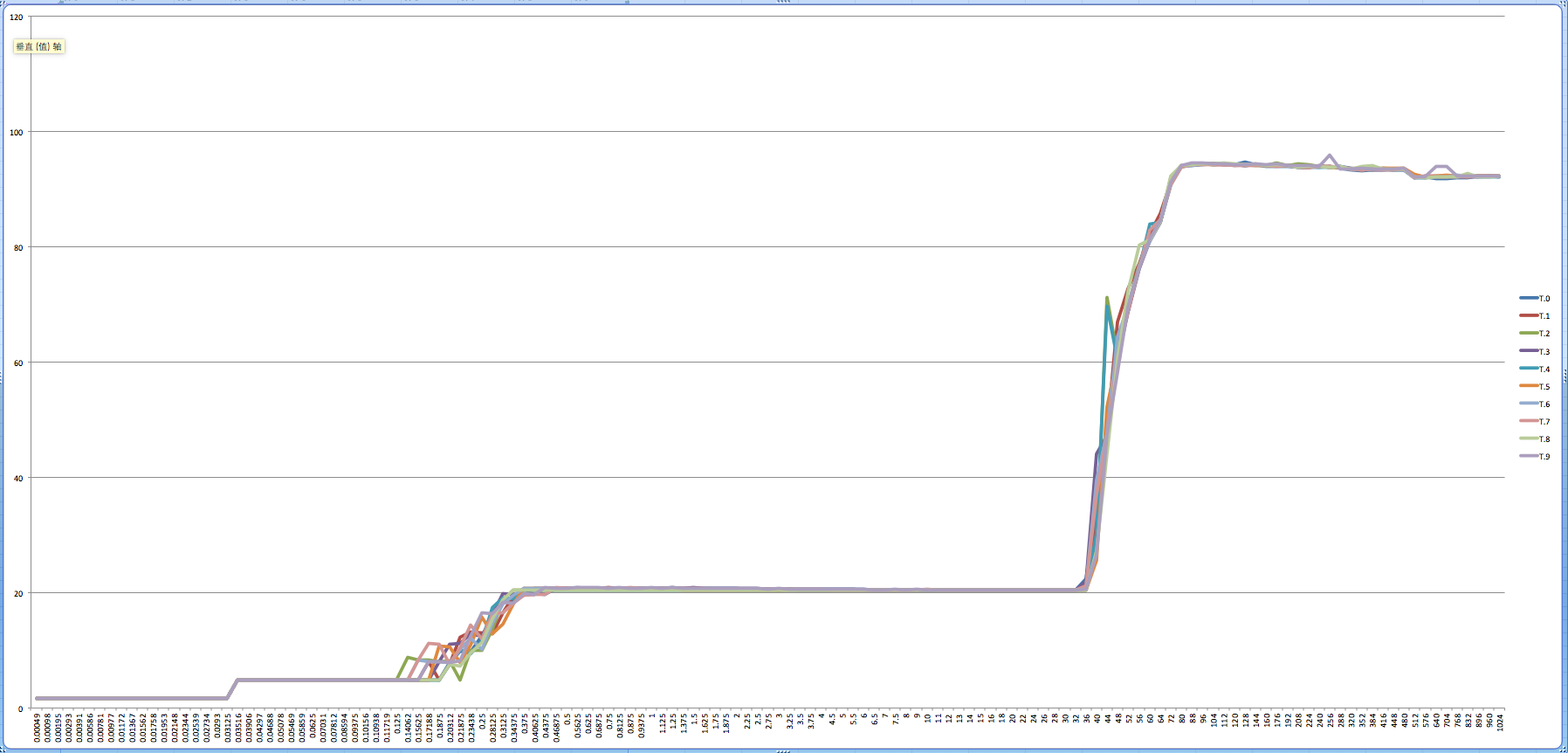

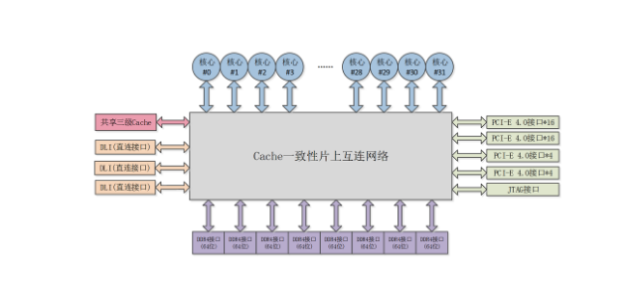
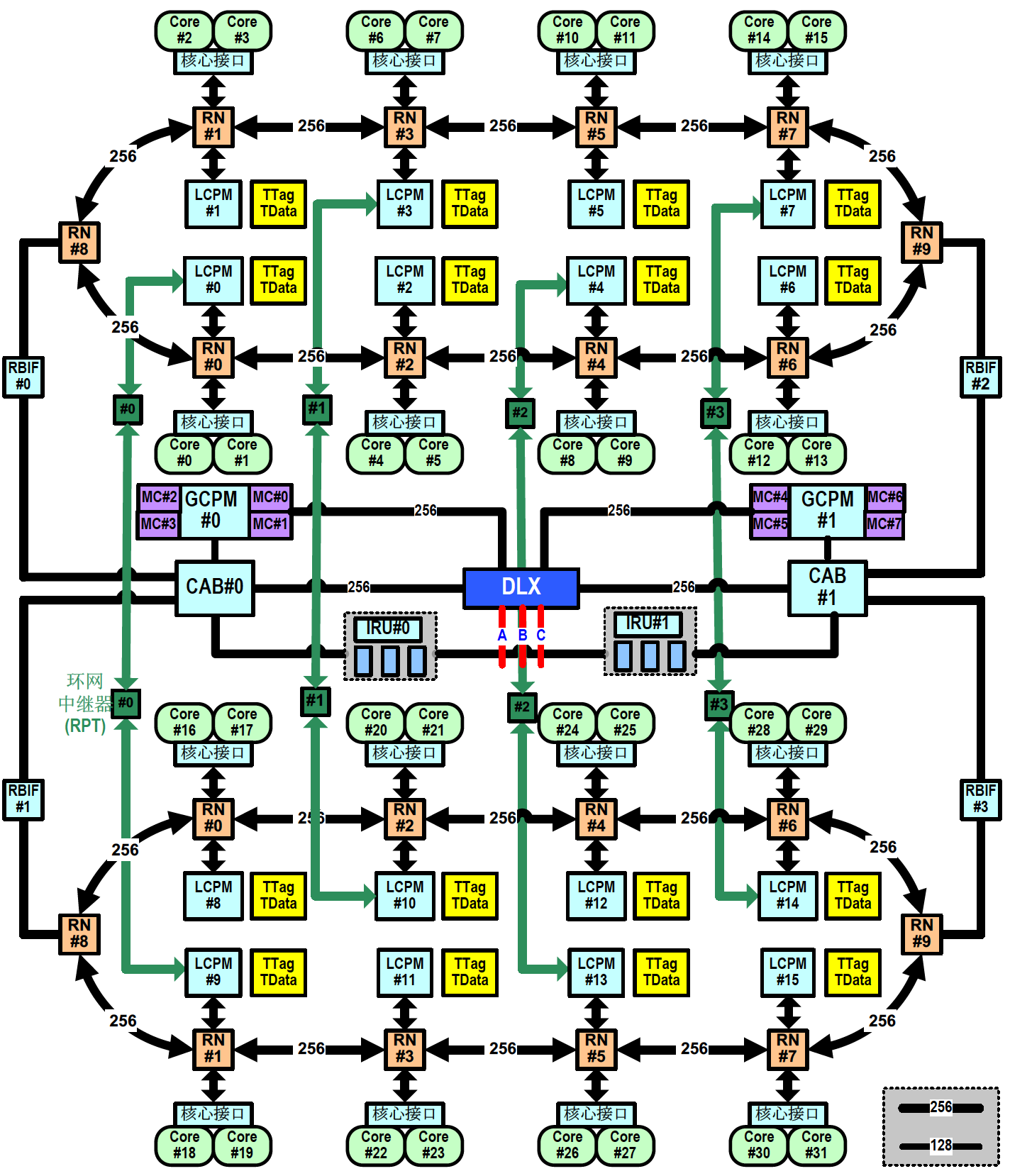
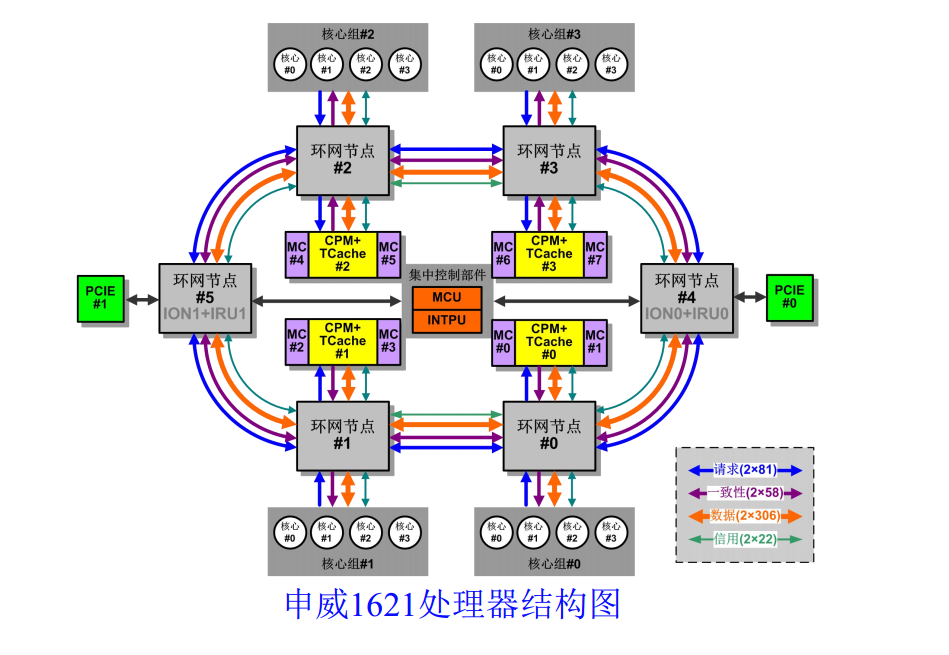 申威1621采用对称多核结构和SoC技术,单芯片集成了16个64位RISC结构的申威处理器核心,目标设计主频为2GHz。芯片还集成八路DDR3存储控制器和双路PCI-E3.0标准I/O接口。
申威1621采用对称多核结构和SoC技术,单芯片集成了16个64位RISC结构的申威处理器核心,目标设计主频为2GHz。芯片还集成八路DDR3存储控制器和双路PCI-E3.0标准I/O接口。