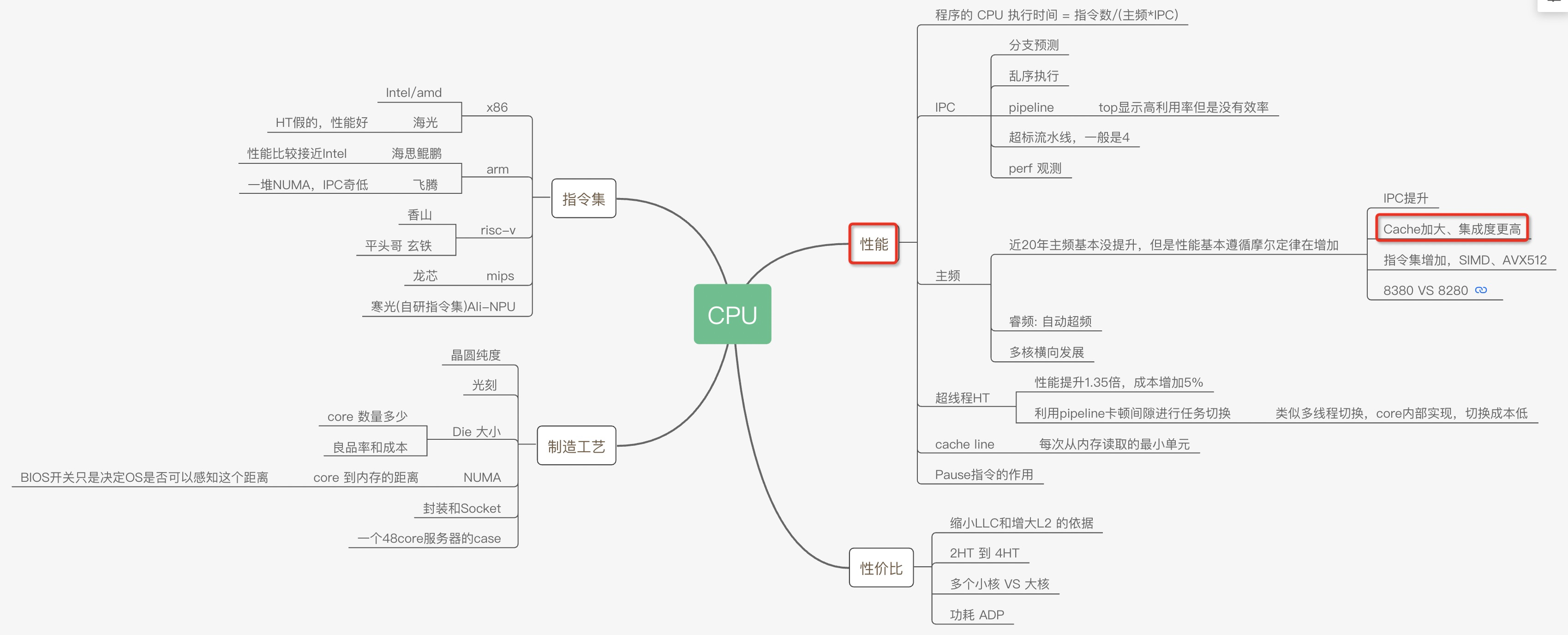
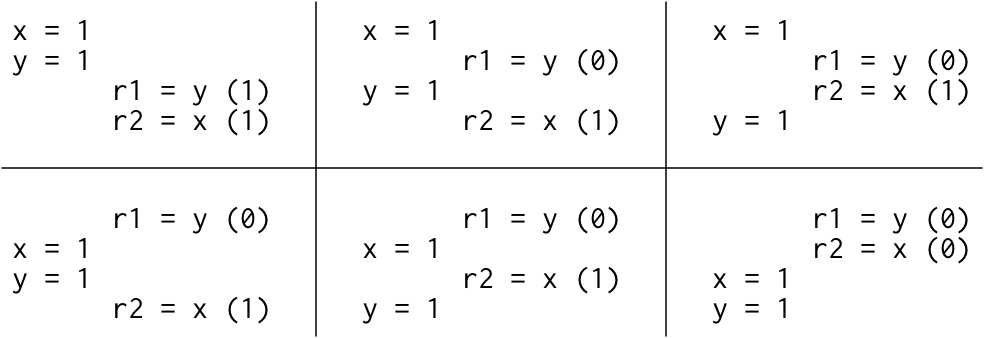CPU性能和CACHE 为了让程序能快点,特意了解了CPU的各种原理,比如多核、超线程、NUMA、睿频、功耗、GPU、大小核再到分支预测、cache_line失效、加锁代价、IPC等各种指标(都有对应的代码和测试数据)都会在这系列文章中得到答案。当然一定会有程序员最关心的分支预测案例、Disruptor无锁案例、cache_line伪共享案例等等。
这次让我们从最底层的沙子开始用8篇文章来回答各种疑问以及大量的实验对比案例和测试数据。
大的方面主要是从这几个疑问来写这些文章:
同样程序为什么CPU跑到800%还不如CPU跑到200%快?
IPC背后的原理和和程序效率的关系?
为什么数据库领域都爱把NUMA关了,这对吗?
几个国产芯片的性能到底怎么样?
系列文章 CPU的制造和概念
[Perf IPC以及CPU性能](/2021/05/16/Perf IPC以及CPU利用率/)
[CPU 性能和Cache Line](/2021/05/16/CPU Cache Line 和性能/)
十年后数据库还是不敢拥抱NUMA?
[Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的](/2019/12/16/Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的/)
Intel、海光、鲲鹏920、飞腾2500 CPU性能对比
一次海光物理机资源竞争压测的记录
飞腾ARM芯片(FT2500)的性能测试
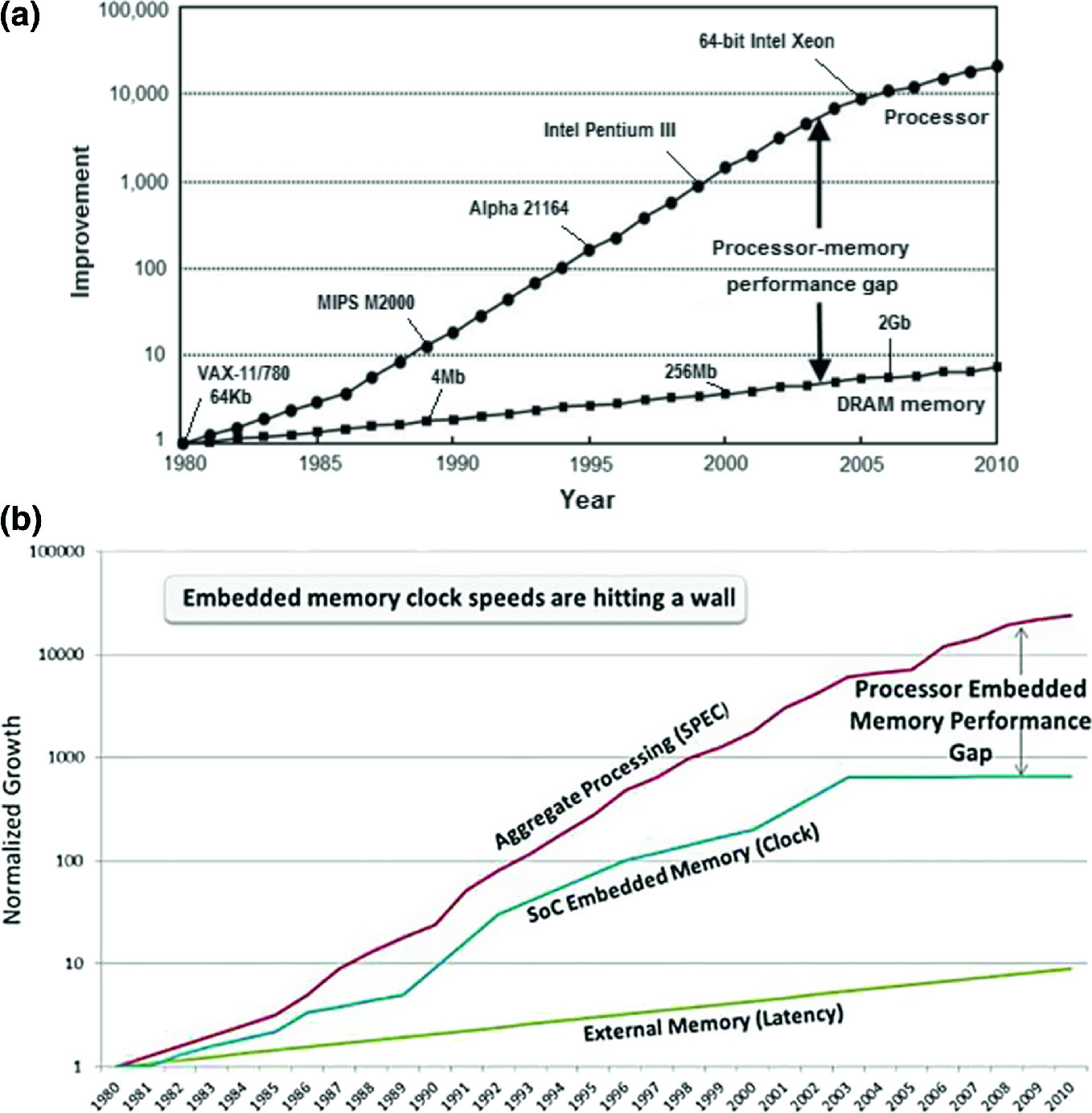
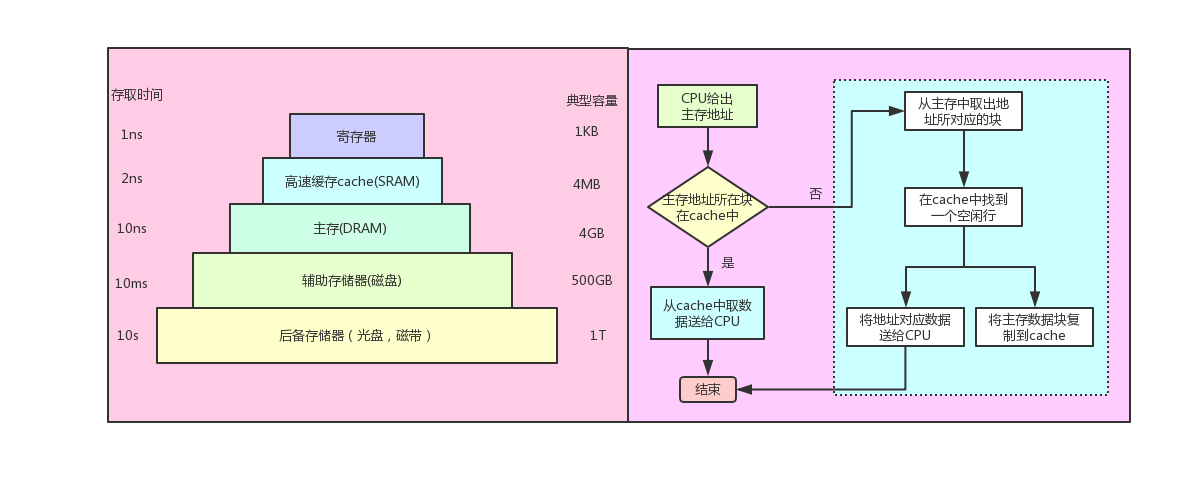
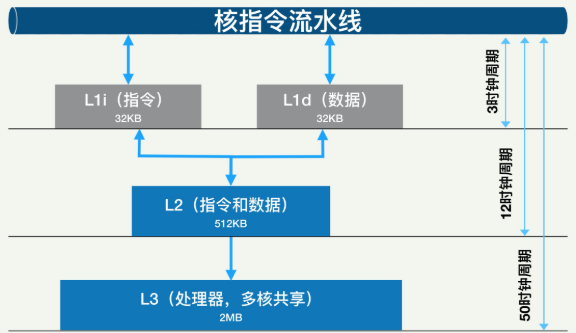
CPU中为什么要L1/L2等各级cache 因为CPU的速度和访问内存速度差异太大,导致CPU在计算的时候90%以上的时间花在等待从内存中取数据、写数据而此时CPU处于闲置状态,也就导致了所谓的 内存墙
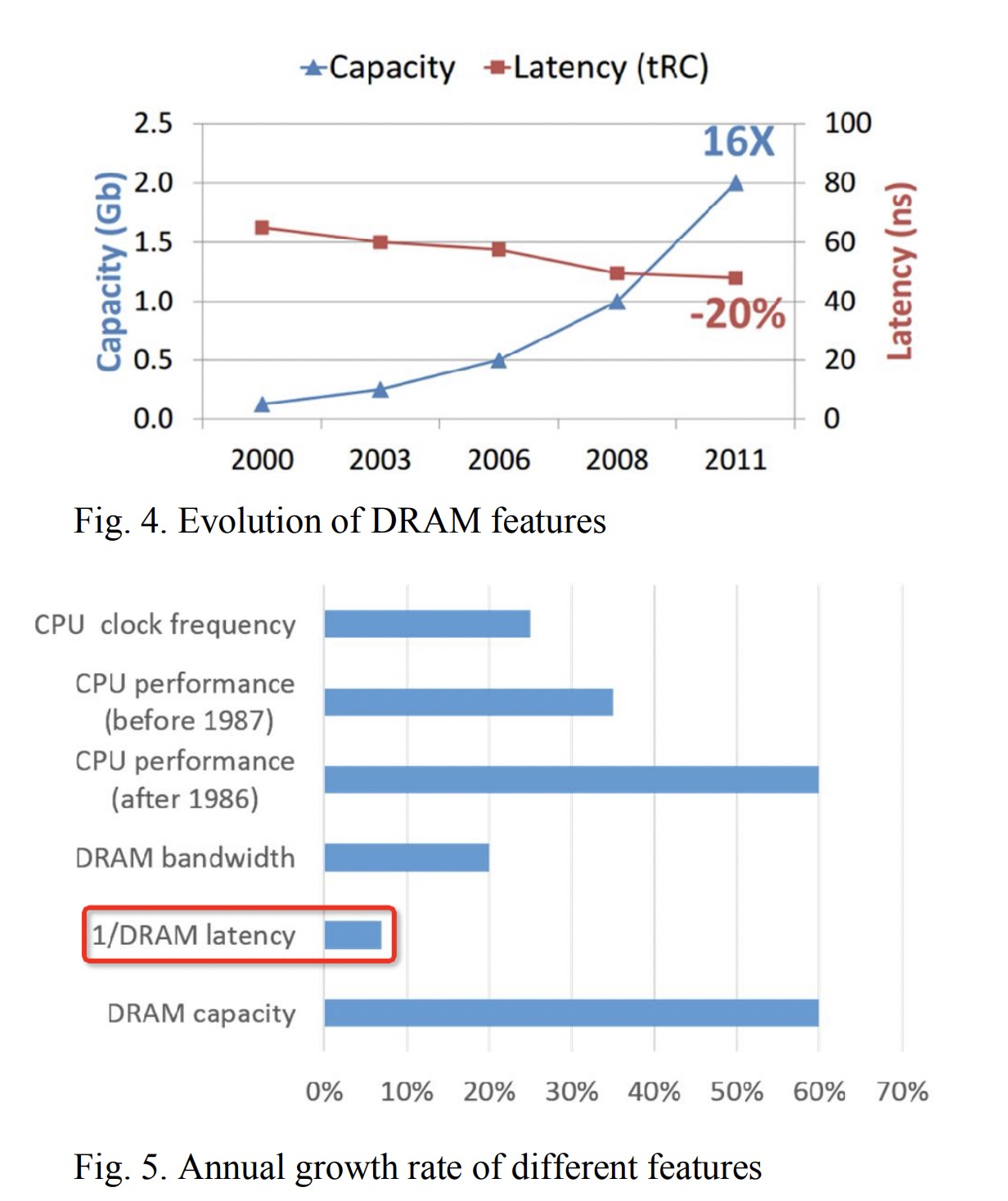
cpu的速度大概50-60%每年的增长率,内存只有7%每年增长率:
CPU访问内存慢的案例参考:Gallery of Processor Cache Effects
在数据使用前加载到CPU内更快的缓存中,最快的一级缓存等待时间是1~3个时钟周期。限制在于对于不在缓存中的数据,还是要等待数十上百个周期——按50周期算的话,不考虑并发和指令执行时间,缓存命中率达到98%,才能发挥一半的理论性能。然而实际情况中,大部分应用都无法达到这个命中率。
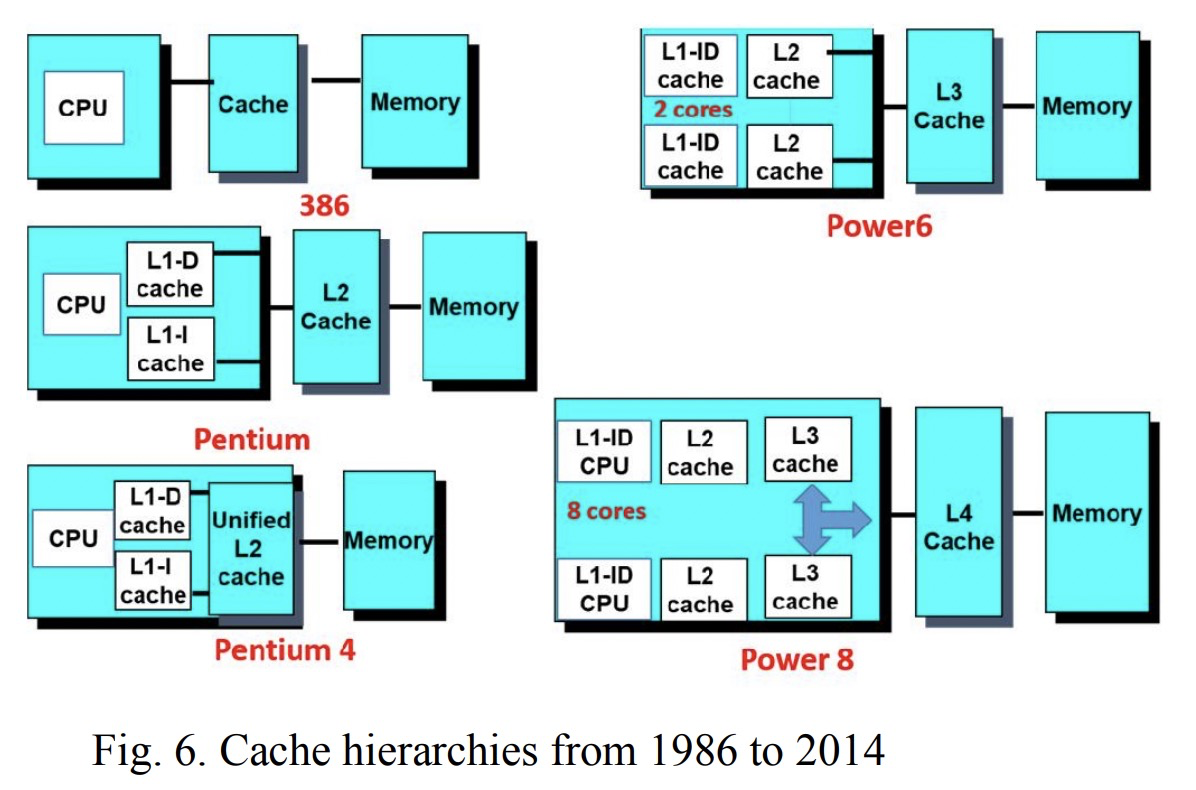
CPU中的cache变迁历史 80486(1989), 8K的L1 cache第一次被集成在CPU中:
80686 (1995) ,L2被放入到CPU的Package 上,但是是一个独立的Die,可以看到L2大小和一个Die差不多:
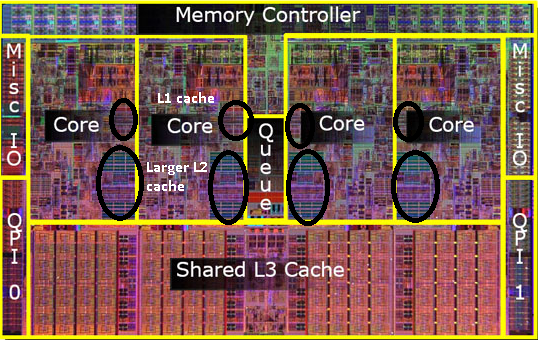
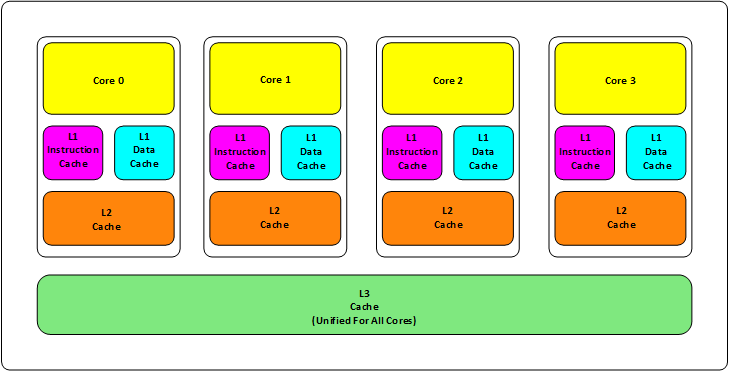
以酷睿为例,现在的CPU集成了L1/L2/L3等各级CACHE,CACHE面积能占到CPU的一半 :
从上图可以看到L3的大小快到die的一半,L1/L2由每个core独享,L3是所有core共享,3级CACHE总面积跟所有core差不多大了。
下图是目前一个主流的Die中CACHE的构成:
cache对速度的影响:
一个方面是物理速度,如果要更大的容量就需要更多的晶体管,除了芯片的体积会变大,更重要的是大量的晶体管会导致速度下降,因为访问速度和要访问的晶体管所在的位置成反比,也就是当信号路径变长时,通信速度会变慢。这部分是物理问题。
另外一个问题是,多核技术中,数据的状态需要在多个CPU中进行同步,并且,我们可以看到,cache和RAM的速度差距太大,所以,多级不同尺寸的缓存有利于提高整体的性能。
cache 大小查看
1 2 3 4 5 6 7 8 9 [root@bugu88 cpu0]# cd /sys/devices/system/ [root@bugu88 cpu0]# cat cache/index0/size 32K [root@bugu88 cpu0]# cat cache/index1/size 32K [root@bugu88 cpu0]# cat cache/index2/size 512K [root@bugu88 cpu0]# cat cache/index3/size 32768K
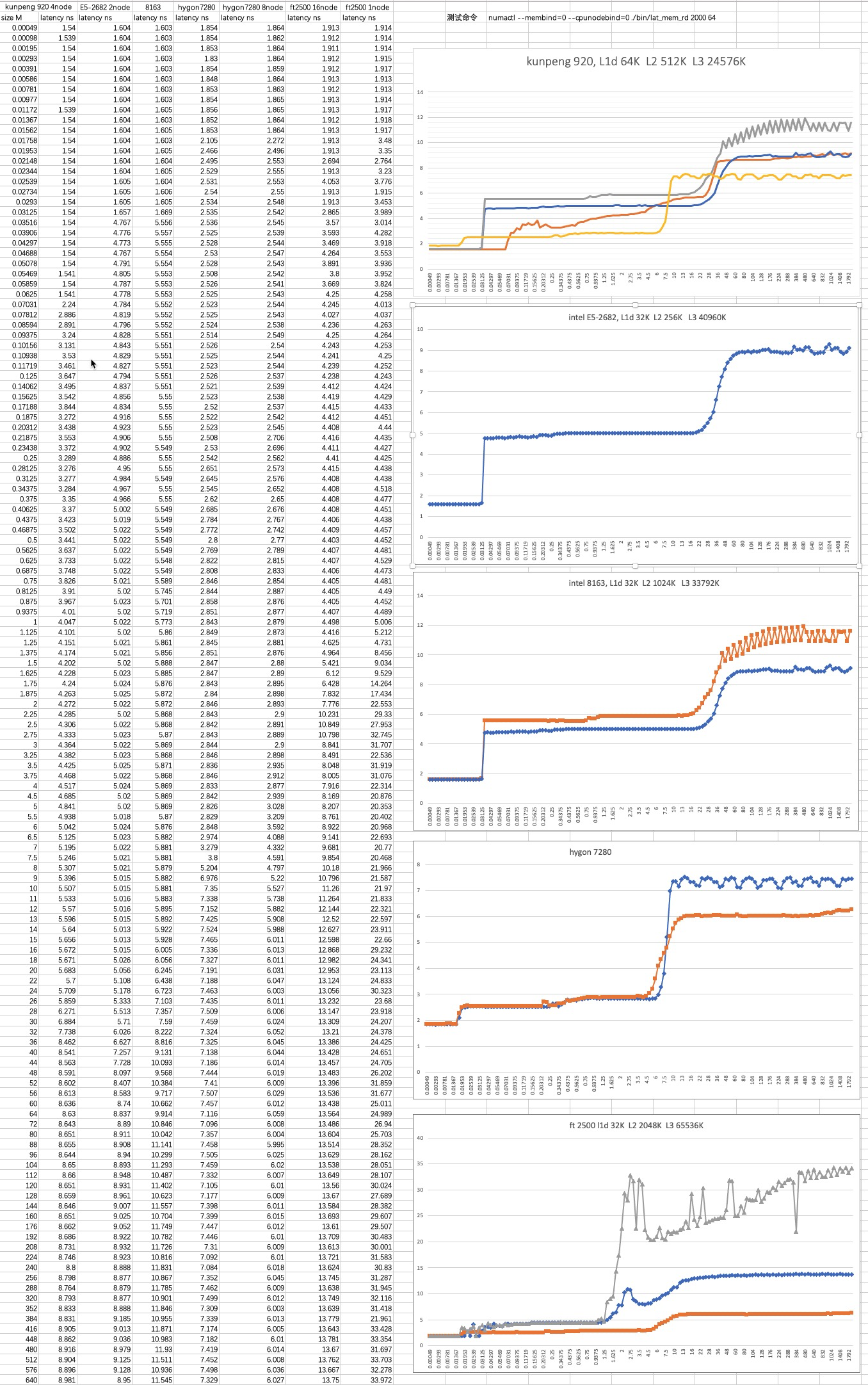
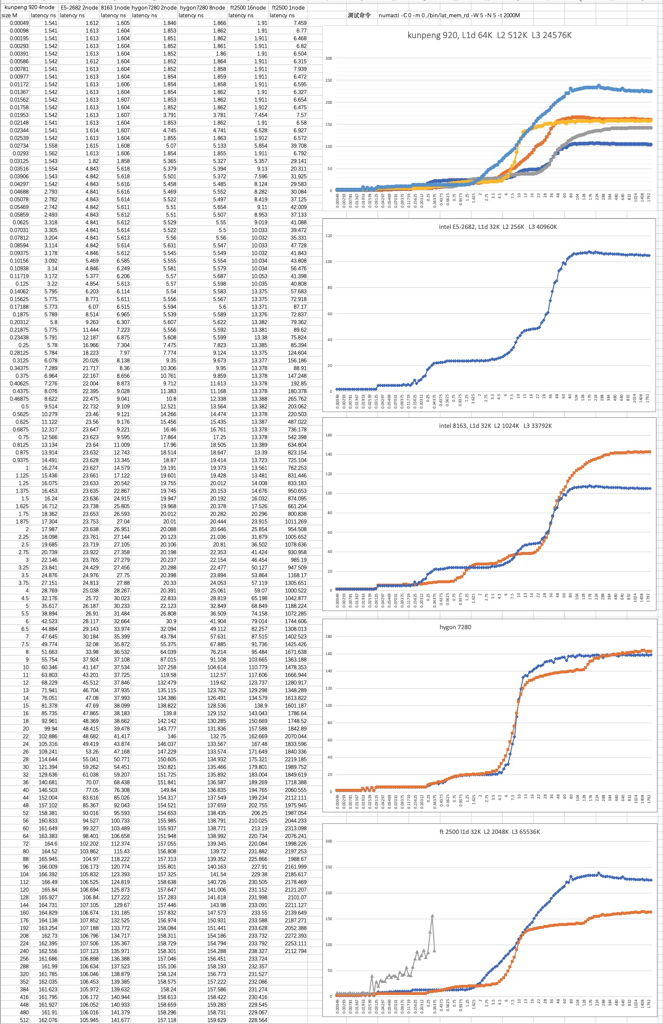
不同型号CPU的cache、内存时延 测试命令:
1 numactl --membind=0 --cpunodebind=0 ./bin/lat_mem_rd 2000 64 //从结果看L3/memory latency不符合常识
调整测试参数,增加 -t 参数
1 numactl -C 0 -m 0 ./bin/lat_mem_rd -W 5 -N 5 -t 2000M
内存基准测试命令 lat_mem_rd 的 -t 参数指定测试集以制造 TLB miss, Cache miss的压力场景,以测试 TLB miss,Cache miss对内存访问延迟的影响
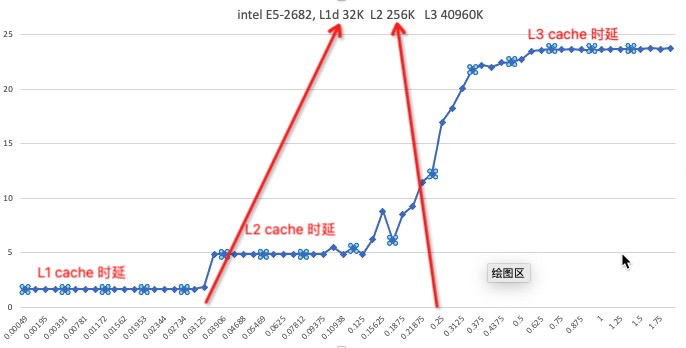
从上图可以看到的一些测试结论
添加 -t 后(第二组测试),L2和L3的延时比较正常了
倒数第三图hygon 7280 2node VS 8node(橙色) , 可以看到8node 内存延时降低了25%
飞腾没开numa内存延时抖动非常大(倒数图二,灰色线),基本不可用,整体延时也比其它CPU高很多
hygon L3大小比较特殊,一个socket下多个Die之间没有共享
intel E5时延表现很优秀,intel E5 CPU开启numa后内存延时有30%以上的减少(图三)
鲲鹏数据比较中规中矩,接近intel
stride参数、-t参数对整体数据影响比较大,x86、arm不同参数下也不一样
E5机器内存速度为2133 MT/S, 8163和8269则是2666 MT/S, 所以说E5的时延表现很优秀
不做任何处理,最直白的矩阵乘法运算,在Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz 运行情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #cat simple.c #include <stdlib.h> #include <stdio.h> #include <emmintrin.h> #define N 2000 double res[N][N] __attribute__ ((aligned (64))); double mul1[N][N] __attribute__ ((aligned (64))); double mul2[N][N] __attribute__ ((aligned (64))); #define SM (CLS / sizeof (double)) //compile:gcc -o simd -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ./simd.c // int main (void) { // ... Initialize mul1 and mul2 int i, i2, j, j2, k, k2; for (i = 0; i < N; ++i) for (j = 0; j < N; ++j) for (k = 0; k < N; ++k) res[i][j] += mul1[i][k] * mul2[k][j]; //mul2[k][j]是先列后行,对cache不友好; // ... use res matrix return 0; }
如果现将矩阵转置一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <stdlib.h> #include <stdio.h> #include <emmintrin.h> #define N 2000 double res[N][N] __attribute__ ((aligned (64))); double mul1[N][N] __attribute__ ((aligned (64))); double mul2[N][N] __attribute__ ((aligned (64))); double tmp[N][N] __attribute__ ((aligned (64))); #define SM (CLS / sizeof (double)) //compile:gcc -o simd -DCLS=$(getconf LEVEL1_DCACHE_LINESIZE) ./simd.c // int main (void) { // ... Initialize mul1 and mul2 int i, i2, j, j2, k, k2; for (i = 0; i < N; ++i) for (j = 0; j < N; ++j) tmp[i][j] = mul2[j][i]; //先转置 for (i = 0; i < N; ++i) for (j = 0; j < N; ++j) for (k = 0; k < N; ++k) res[i][j] += mul1[i][k] * tmp[j][k]; //转置后按行访问,对内存友好 // ... use res matrix return 0; }
执行结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 //未做任何优化,直接矩阵乘法 #taskset -c 1 perf stat ./simple 47192.640339 task-clock (msec) # 1.001 CPUs utilized 88 context-switches # 0.002 K/sec 1 cpu-migrations # 0.000 K/sec 31,392 page-faults # 0.665 K/sec 117,866,224,774 cycles # 2.498 GHz <not supported> stalled-cycles-frontend <not supported> stalled-cycles-backend 264,254,238,724 instructions # 2.24 insns per cycle 8,052,145,218 branches # 170.623 M/sec 4,573,572 branch-misses # 0.06% of all branches 47.151498977 seconds time elapsed //转置后都是按行取数据,但是需要额外的空间 #taskset -c 0 perf stat ./simp2 30457.259168 task-clock (msec) # 1.001 CPUs utilized 137 context-switches # 0.004 K/sec 7 cpu-migrations # 0.000 K/sec 86,081 page-faults # 0.003 M/sec 76,068,232,551 cycles # 2.498 GHz <not supported> stalled-cycles-frontend <not supported> stalled-cycles-backend 264,385,818,470 instructions # 3.48 insns per cycle 8,072,001,639 branches # 265.027 M/sec 4,414,867 branch-misses # 0.05% of all branches 30.437018792 seconds time elapsed //按cache line 运算 #taskset -c 1 perf stat ./s3 29767.847109 task-clock (msec) # 1.001 CPUs utilized 41 context-switches # 0.001 K/sec 1 cpu-migrations # 0.000 K/sec 31,454 page-faults # 0.001 M/sec 74,346,857,277 cycles # 2.498 GHz <not supported> stalled-cycles-frontend <not supported> stalled-cycles-backend 253,099,702,393 instructions # 3.40 insns per cycle 11,450,804,877 branches # 384.670 M/sec 16,043,642 branch-misses # 0.14% of all branches 29.742025067 seconds time elapsed //使用simd指令,按理应该最快,实际效果很差 :( #taskset -c 1 perf stat ./simd 140224.550539 task-clock (msec) # 1.001 CPUs utilized 243 context-switches # 0.002 K/sec 2 cpu-migrations # 0.000 K/sec 70,569 page-faults # 0.503 K/sec 350,218,614,852 cycles # 2.498 GHz <not supported> stalled-cycles-frontend <not supported> stalled-cycles-backend 717,191,577,191 instructions # 2.05 insns per cycle 25,161,922,136 branches # 179.440 M/sec 54,411,349 branch-misses # 0.22% of all branches 140.101635085 seconds time elapsed
On ARM Kunpeng 920-4826:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #taskset -c 1 perf stat ./simple 150,242.52 msec task-clock # 1.000 CPUs utilized 943 context-switches # 0.006 K/sec 0 cpu-migrations # 0.000 K/sec 31,289 page-faults # 0.208 K/sec 390,626,613,178 cycles # 2.600 GHz 432,396,482,134 instructions # 1.11 insn per cycle <not supported> branches 11,348,599 branch-misses 150.249408485 seconds time elapsed #taskset -c 1 perf stat ./simp2 69,008.66 msec task-clock # 1.000 CPUs utilized 426 context-switches # 0.006 K/sec 0 cpu-migrations # 0.000 K/sec 39,104 page-faults # 0.567 K/sec 179,417,225,187 cycles # 2.600 GHz 432,409,078,894 instructions # 2.41 insn per cycle <not supported> branches 11,122,131 branch-misses 69.014491453 seconds time elapsed #taskset -c 1 perf stat ./s3 50,251.34 msec task-clock # 1.000 CPUs utilized 315 context-switches # 0.006 K/sec 0 cpu-migrations # 0.000 K/sec 31,289 page-faults # 0.623 K/sec 130,652,187,736 cycles # 2.600 GHz 291,261,746,765 instructions # 2.23 insn per cycle <not supported> branches 160,585,583 branch-misses 50.254025852 seconds time elapsed
如果在aarch编译开启gcc -O3 优化选项:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 //aarch gcc -O3 on #taskset -c 1 perf stat ./simple //开O3后 优化器走了simd指令 67,897.93 msec task-clock # 1.000 CPUs utilized 414 context-switches # 0.006 K/sec 0 cpu-migrations # 0.000 K/sec 31,289 page-faults # 0.461 K/sec 176,532,812,062 cycles # 2.600 GHz 28,214,139,367 instructions # 0.16 insn per cycle <not supported> branches 3,250,598 branch-misses #perf stat ./s2 //s2代码直接按行访问mul2,不考虑结果对错,运算量一样,相当于整体转置 15,963.30 msec task-clock # 1.000 CPUs utilized 20 context-switches # 0.001 K/sec 0 cpu-migrations # 0.000 K/sec 31,288 page-faults # 0.002 M/sec 41,504,239,031 cycles # 2.600 GHz 56,108,176,644 instructions # 1.35 insn per cycle <not supported> branches 4,586,197 branch-misses #taskset -c 1 perf stat ./s3 5,695.85 msec task-clock # 1.000 CPUs utilized 35 context-switches # 0.006 K/sec 0 cpu-migrations # 0.000 K/sec 31,289 page-faults # 0.005 M/sec 14,808,977,314 cycles # 2.600 GHz 24,281,358,553 instructions # 1.64 insn per cycle <not supported> branches 2,006,221 branch-misses s3.c反编译后的汇编: bc: 913a0060 add x0, x3, #0xe80 c0: eb04001f cmp x0, x4 c4: 1f584010 fmadd d16, d0, d24, d16 c8: 1f571c07 fmadd d7, d0, d23, d7 //参数 d7-精度,d0 cc: 1f561806 fmadd d6, d0, d22, d6 d0: 1f551405 fmadd d5, d0, d21, d5 d4: 1f541004 fmadd d4, d0, d20, d4 d8: 1f530c03 fmadd d3, d0, d19, d3 dc: 1f520802 fmadd d2, d0, d18, d2 e0: 1f510401 fmadd d1, d0, d17, d1 e4: 54fffd81 b.ne 94 <main+0x94> e8: 91400c22 add x2, x1, #0x3, lsl #12 ec: fd000030 str d16, [x1]
FMADD指令
Floating-point fused Multiply-Add (scalar). This instruction multiplies the values of the first two SIMD&FP source registers, adds the product to the value of the third SIMD&FP source register, and writes the result to the SIMD&FP destination register.
一些对比解释:
编译优化选项设置-O2 级别及以上时,Kunpeng 处理器将对连续的浮点数乘法、加法融 合为乘加运算,以提升性能和精度。在-O2 级以上编译选项,x86 处理器不会将乘法和 加法做融合乘加运算,因此两种处理器在连续的浮点数乘法、加法运算后,小数点后 16 位存在差异。
cache对CPU性能的影响 CPU访问内存是非常慢的,所以我们在CPU中增加了多级缓存来匹配 CPU和内存的速度。主频这20年基本都没怎么做高了,但是工艺提升了两个数量级,也就是集成的晶体管数量提升了2个数量级,工艺提升的能力主要给了cache,从而整体CPU性能提升了很多。
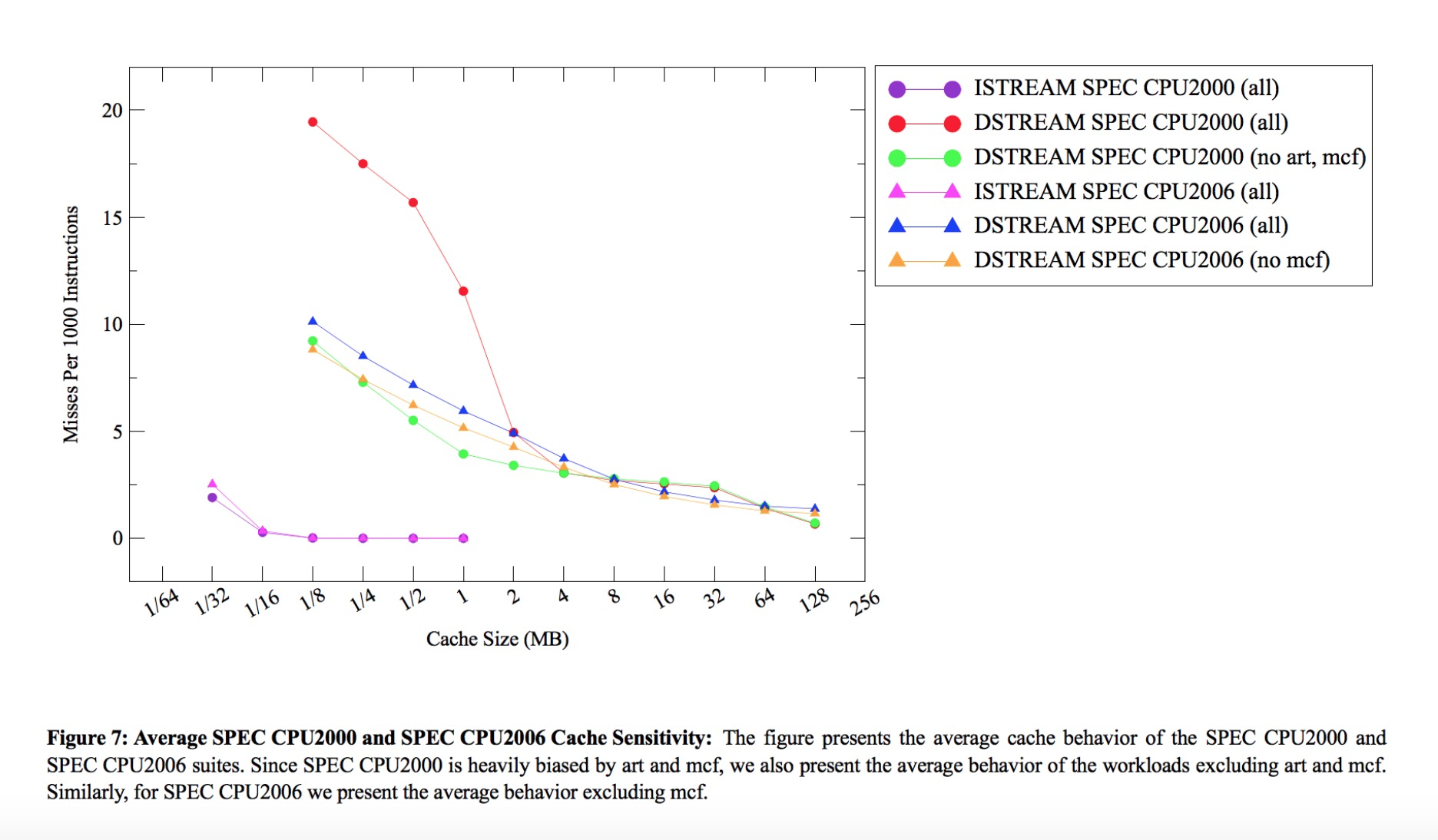
缓存对Oceanbase ,MySQL, ODPS的性能影响 以下测试数据主要来源于真实的业务场景:OB/MySQL/ODPS
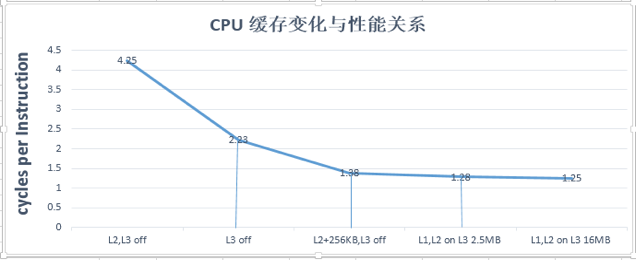
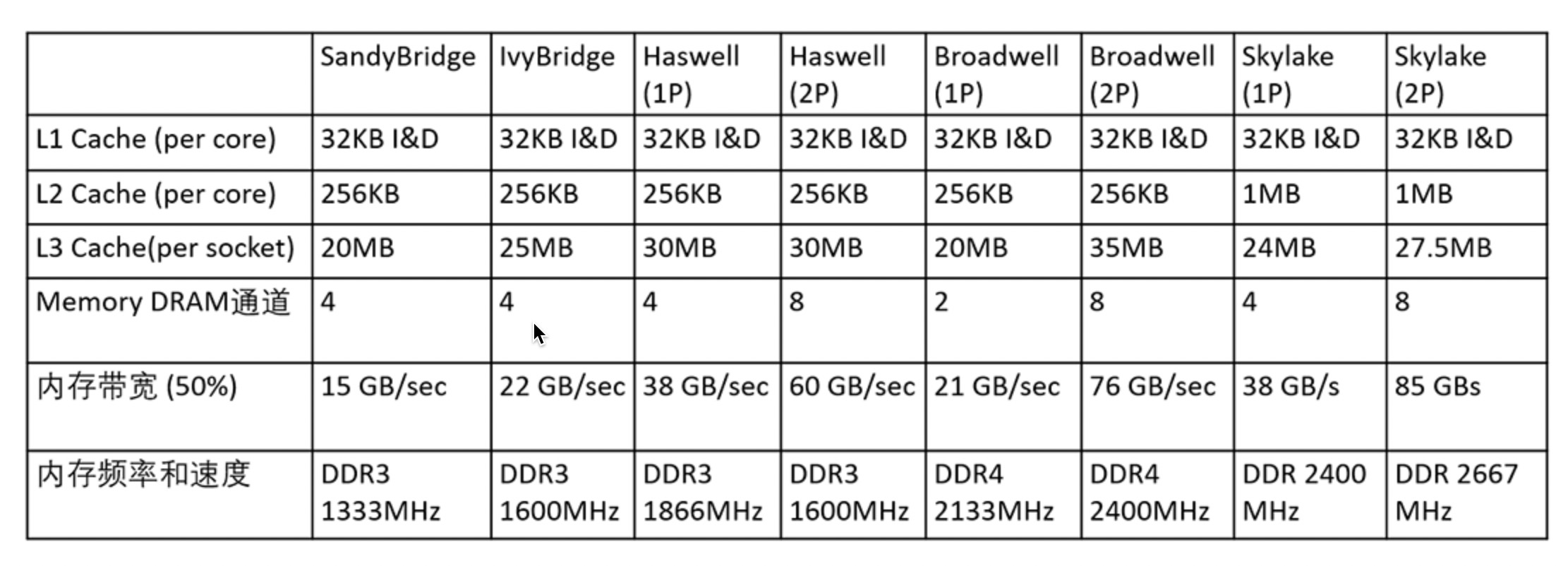
x86 Skylake之前,L1 I/D 32KB, L2 256KB, L3 2.5MB/core, 2.5MB/core的L3(LLC)芯片面积相当于1/2 CPU core 的尺寸
关闭L3(2.5MB),关闭L2(256KB),此时性能CPI(越小越好)是4.25
关闭L3,打开L2(256KB),此时性能CPI为2.23
关闭L3,打开L2同时增加256KB,L2尺寸到512KB,性能CPI为1.38
打开L3(2.5MB),打开L2(256KB),性能为1.28 ,该状态就是intel CPU出厂的状态
打开L3,增加到16MB,打开L2(256KB),性能为1.25
上面的数据显示当L3关闭之后,从case 3 开始,L2仅仅增加256KB,L2芯片面积相对于CPU core 增加 5%(0.5 /2.5M * 025M),性能相对于case 2 提升1.61倍(2.23/1.38),而使用case 4 ,L3 2.5MB打开,相对于case 3,增加2.3MB(2.5MB - 256KB),芯片面积相对于CPU core 增加 46%(0.5/2.5M * 2.3M), 而性能仅仅提升 1.07倍(1.38/1.28),所以14年给Intel提议需要增加L2尺寸降低L3尺寸,这些数据促使Intel开始重新考虑对于数据中心缓存新的设计。
2014年的 Broadwell 的第五代智能酷睿处理器,是 Haswell 的 14nm 升级版($1745.00 - $1749.00):
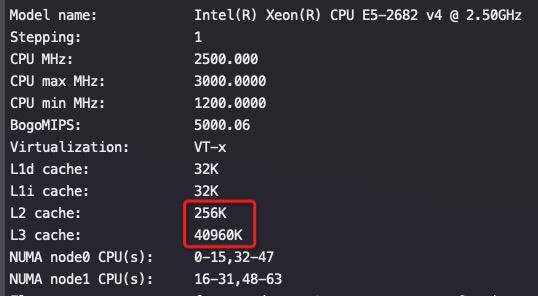
E5一个Die有16个物理core(上面截图是两个Socket, 每个Socket一个Die,每个物理core两个超线程),所以每core的L3大小:40M/16=2.5M/core
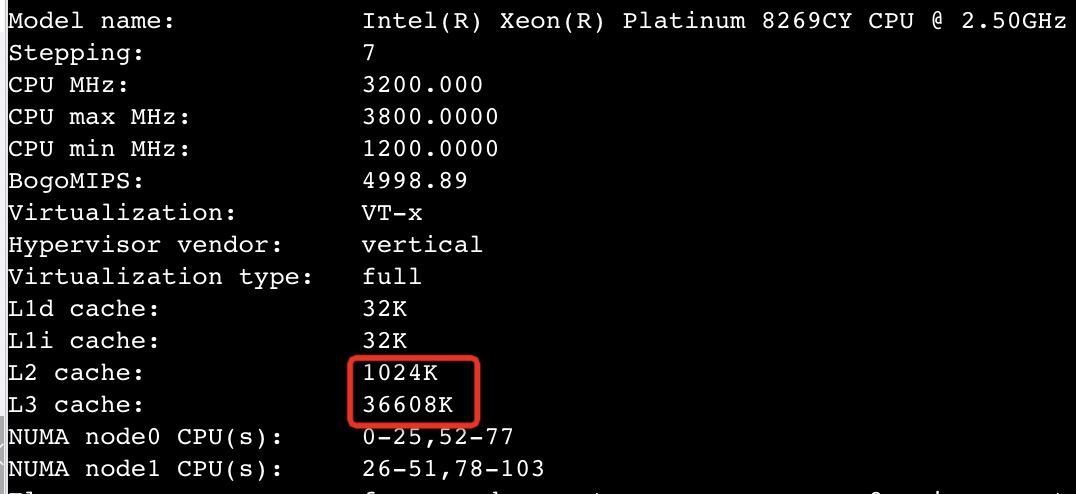
2015年则推出 SkyLake 架构的Platinum 8269CY($4702.00), 每core的L3大小:36M/26=1.38M/core:
Intel 2015年 发表论文《High Performing Cache Hierarchies for Server Workloads》 证明了阿里提出的建议的正确性,从Skylake架构开始将L2 cache 由 256KB 升级到 1MB, L3由2.5MB /core 压缩到 1.375MB / core, Intel之所以没有完全去掉L3的原因是希望这样设计的CPU对于 使用 CPU2006的workload性能仍然能够做到不受影响。
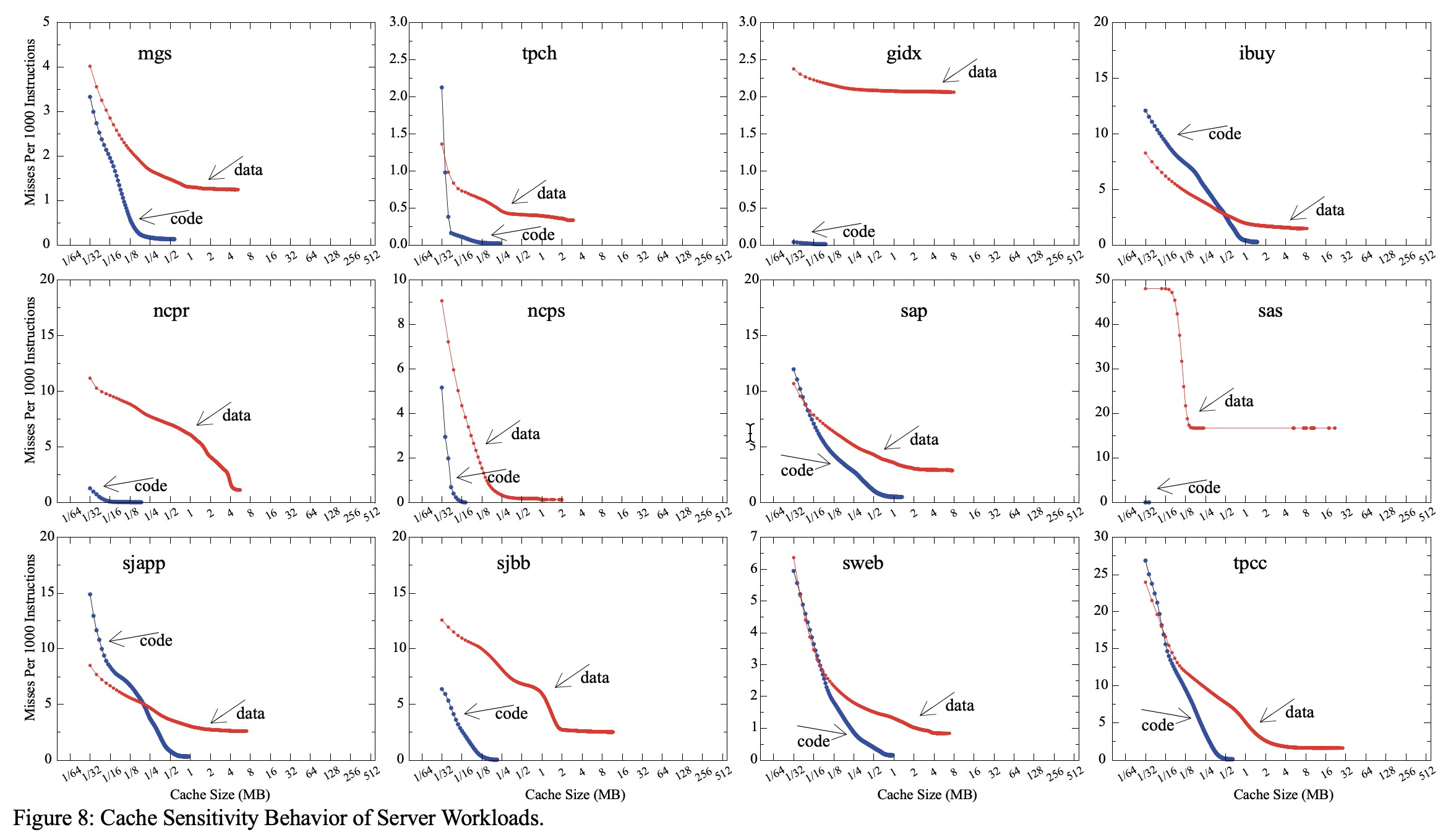
上图是不同业务场景下,CPI 随cache大小的变化,可以看到随着cache增加性能基本不增加了。
CPU L2, Last Level Cache (LLC) 缓存的演变 Last Level Cache(L3) 在2016年之前都是2MB/core 或者 2.5MB/core, 这个原因取决于在此之前行业都是使用CPU2006作为设计CPU的benchmark,如下图所示:
根据上图中CPU2006的MPKI数据显示如果LLC在4MB的时候非常好,LLC在2.5MB之后MKPI提升10%性能只有1~3%的提升,2.5MB LLC cache是 CPU core 1/2 的芯片面积,因此若将LLC 由2.5MB升级到4MB,换算成CPU core的芯片面积是增长30%(1/2 * 1.5M/2.5M),但性能仅仅提升最多3%,这就是为什么基于CPU2006的benchmark条件下,intel将LLC设定为2~2.5MB的原因。
Cache的缺点 缓存有两大缺点:
当数据集非常大的时候,时间空间局部性较低时缓存的工作效率很低;
当缓存工作效率高的时候,局部性非常高,这意味着,根据定义,大多数缓存在大多数时间都处于空闲状态。
对存储在内存中数据更改的可见性和一致性,所以这个契约被称为内存一致性模型(memory consistency model)或仅仅是内存模型(memory model)
r1/r2是线程本地变量,如下代码的可能结果是哪些?
1 2 3 4 5 6 Litmus Test: Message Passing Can this program see r1 = 1, r2 = 0? // Thread 1 // Thread 2 x = 1 r1 = y y = 1 r2 = x
如果该litmus test的执行顺序一致,则只有六种可能的交替:
因为没有交替执行的结果会产生r1 = 1, r2 = 0,所以这个结果是不允许的。也就是说,在顺序执行的硬件上,litmus test执行结果出现r1 = 1, r2 = 0是不可能的。
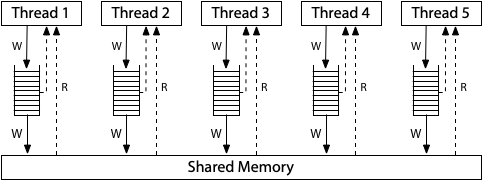
顺序一致性的一个很好的思维模型是想象所有处理器直接连接到同一个共享内存,它可以一次处理一个线程的读或写请求。 不涉及缓存,因此每次处理器需要读取或写入内存时,该请求都会转到共享内存。 一次使用一次的共享内存对所有内存访问的执行施加了顺序顺序:顺序一致性。
所有处理器仍然连接到一个共享内存,但是每个处理器都将对该内存的写入(write)放入到本地写入队列中。处理器继续执行新指令,同时写操作(write)会更新到这个共享内存。一个处理器上的内存读取在查询主内存之前会查询本地写队列,但它看不到其他处理器上的写队列。其效果就是当前处理器比其他处理器会先看到自己的写操作。但是——这一点非常重要——==所有处理器都保证写入(存储store)到共享内存的(总)顺序,所以给这个模型起了个名字:总存储有序,或TSO==。当一个写操作到达共享内存时,任何处理器上的任何未来读操作都将看到它并使用该值(直到它被以后的写操作覆盖,或者可能被另一个处理器的缓冲写操作覆盖)。
针对前文的litmus test案例,写队列保证线程1在y之前将x写入内存,关于内存写入顺序(总存储有序)的系统级协议保证线程2在读y的新值之前读x的新值。因此,r1 = y在r2 = x看不到新的x之前不可能看到新的y。存储顺序至关重要:线程1在写入y之前先写入x,因此线程2在看到x的写入之前不可能看到y的写入。
但是对于TSO系统下,以下case能看到r1 = 0, r2 = 0, 如果在顺序一致性的协议下这是不可能发生的
1 2 3 4 5 6 7 8 Litmus Test: Write Queue (also called Store Buffer) Can this program see r1 = 0, r2 = 0? // Thread 1 // Thread 2 x = 1 y = 1 r1 = y r2 = x On sequentially consistent hardware: no. On x86 (or other TSO): yes!
为了让TSO和顺序一致性协议保持一致,我们需要依赖于更强的内存排序,非顺序一致的硬件提供了称为内存屏障(或栅栏)的显式指令,可用于控制排序。我们可以添加一个内存屏障,以确保每个线程在开始读取之前都会刷新其先前对内存的写入:
1 2 3 4 // Thread 1 // Thread 2 x = 1 y = 1 barrier barrier r1 = y r2 = x
加上正确的障碍,r1 = 0,r2 = 0也是不可能的了。内存屏障有很多种,它的存在给了程序员或语言实现者一种在程序的关键时刻强制顺序一致行为的方法。
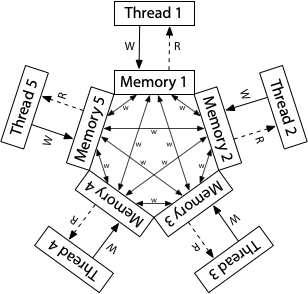
ARM和POWER系统的概念模型是,每个处理器从其自己的完整内存副本中读取和向其写入,每个写入独立地传播到其他处理器,随着写入的传播,允许重新排序。
这里没有总存储顺序。虽然没有描述,但是每个处理器都被允许推迟读取(read),直到它等到它需要结果:读取(read)可以被延迟到稍后的写入(write)之后。在这个宽松的(relaxed)模型中,我们迄今为止所看到的每一个litmus test的答案都是“yes,这真的可能发生。”
在这个内存模型下,对于前文中的 Litmus Test: Message Passing case是可以看到r1=1,r2=0的(TSO保证不会),但是可以保证 Litmus Test: Store Buffering case 和TSO一致。
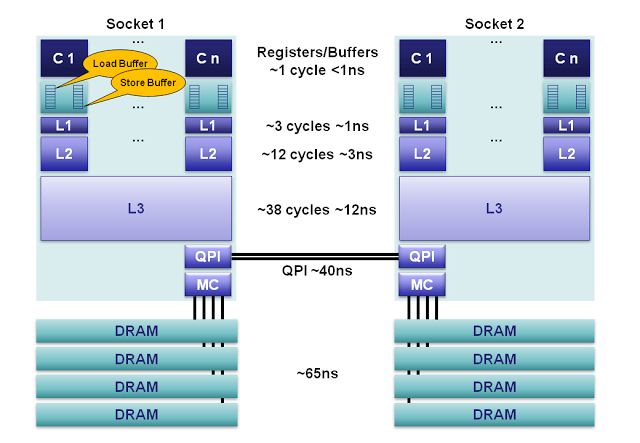
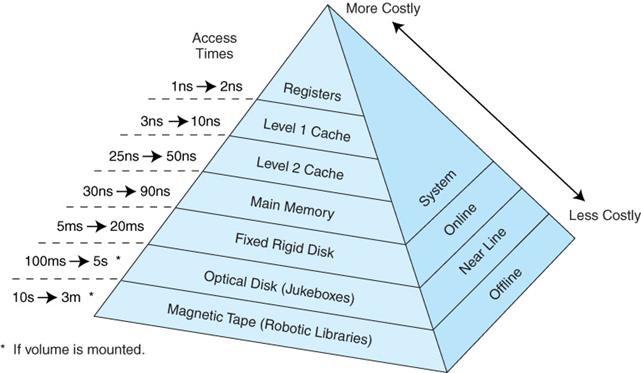
最后再附加几个Latency数据,让大家比较起来更有体感一些
各级IO延迟数字 Cache、内存、磁盘、网络的延迟比较 假设主频2.6G的CPU,每个指令只需要 0.38ns
每次内存寻址需要 100ns
一次 CPU 上下文切换(系统调用)需要大约 1500ns,也就是 1.5us(这个数字参考了这篇文章 ,采用的是单核 CPU 线程平均时间)
SSD 随机读取耗时为 150us
从内存中读取 1MB 的连续数据,耗时大约为 250us
同一个数据中心网络上跑一个来回需要 0.5ms
从 SSD 读取 1MB 的顺序数据,大约需要 1ms (是内存速度的四分之一)
磁盘寻址时间为 10ms
从磁盘读取 1MB 连续数据需要 20ms
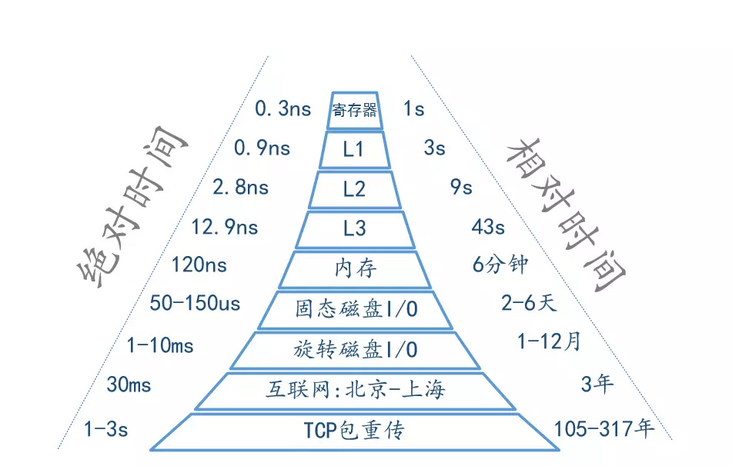
如果 CPU 访问 L1 缓存需要 1 秒,那么访问主存需要 3 分钟、从 SSD 中随机读取数据需要 3.4 天、磁盘寻道需要 2 个月,网络传输可能需要 1 年多的时间。
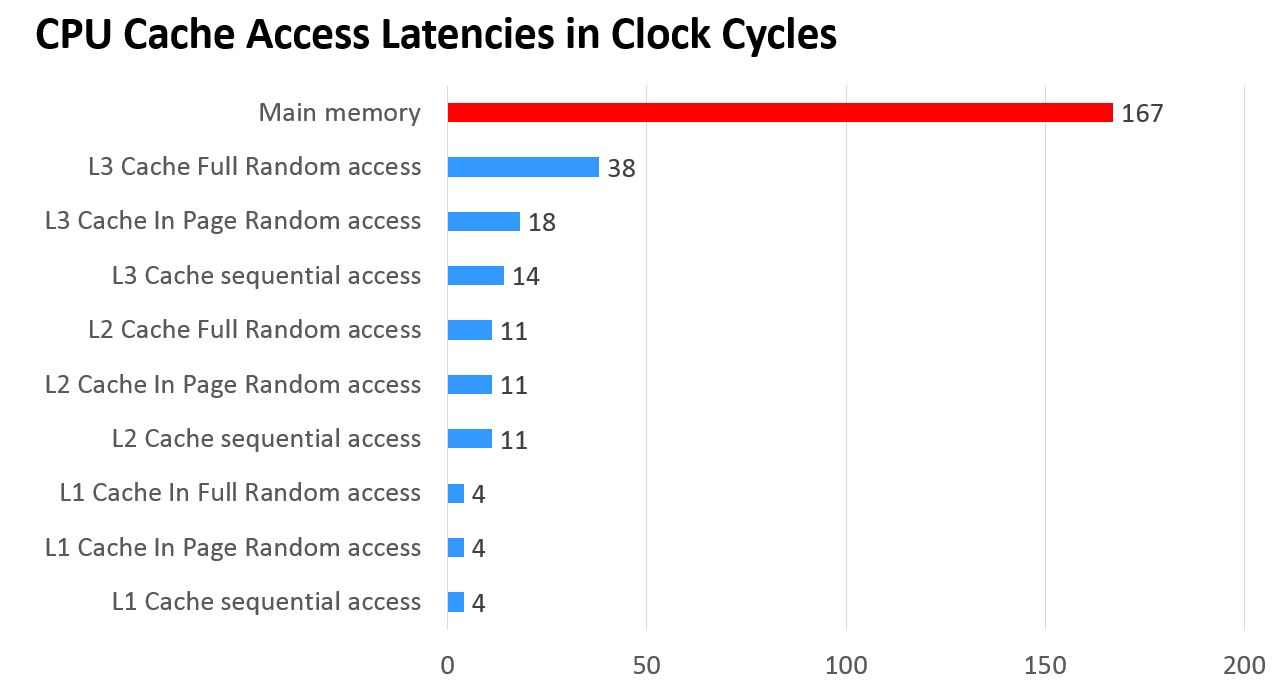
内存和cache的latency对比
各级cache的Latency :
2012 年延迟数字对比表:
Work
Latency
L1 cache reference
0.5 ns
Branch mispredict
5 ns
L2 cache reference
7 ns
Mutex lock/unlock
25 ns
Main memory reference
100 ns
持久内存
300 ns
Compress 1K bytes with Zippy
3,000 ns
Send 1K bytes over 1 Gbps network
10,000 ns
Read 4K randomly from SSD*
150,000 ns
Read 1 MB sequentially from memory
250,000 ns
Round trip within same datacenter
500,000 ns
Read 1 MB sequentially from SSD*
1,000,000 ns
Disk seek
10,000,000 ns
Read 1 MB sequentially from disk
20,000,000 ns
Send packet CA->Netherlands->CA
150,000,000 ns
一个比较有体感的比较:如果 CPU 访问 寄存器需要 1 秒,那么访问主存需要 3 分钟、从 SSD 中随机读取数据需要 3.4 天、磁盘寻道需要 2 个月,网络传输可能需要 1 年多的时间。
当然更古老一点的年代给出来的数据可能又不一样一点,但是基本比例差异还是差不多的:
测试Inte E5 L1 、L2、L3的cache延时图来加深印象,可以看到在每级cache大小附近时延有个跳跃(纵坐标是纳秒,横坐标是大小 M):
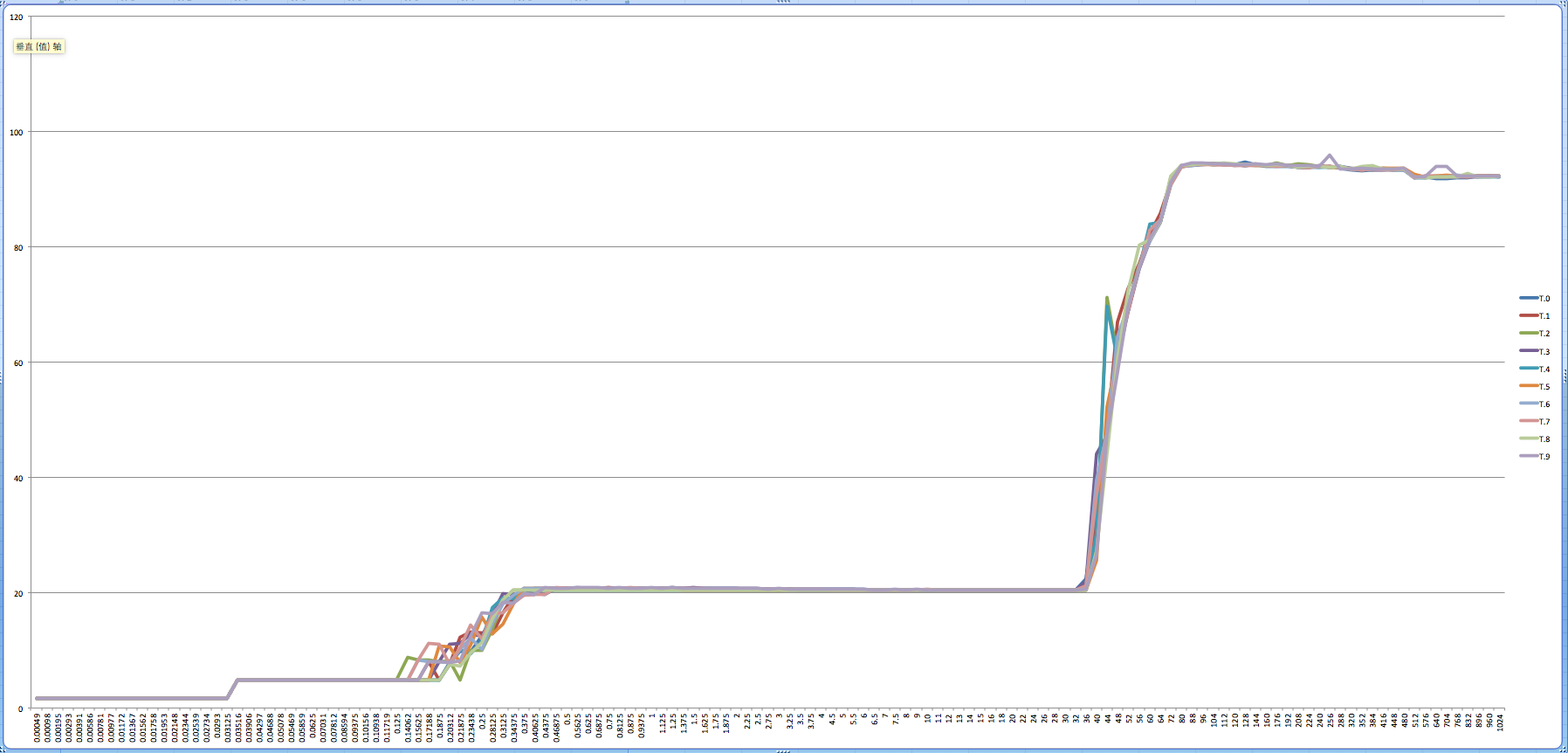
推荐从这里看延时,拖动时间轴可以看到随着技术、工艺的改变Latency每一年的变化
查看cpu cache数据
cat /proc/cpuinfo |grep -i cache
L1C、L2C、L3C、DDR 的Latency测试数据 下图从左至右响应时间分别是L1C、L2C、L3C、DDR ,可以看出这四个Latency变化还是非常明显的,泾渭分明。
测试memory latency memory latency逻辑 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 #include <sys/types.h> #include <stdlib.h> #include <stdio.h> #include <sys/mman.h> #include <sys/time.h> #include <unistd.h> #define ONE p = (char **)*p; #define FIVE ONE ONE ONE ONE ONE #define TEN FIVE FIVE #define FIFTY TEN TEN TEN TEN TEN #define HUNDRED FIFTY FIFTY static void usage() { printf("Usage: ./mem-lat -b xxx -n xxx -s xxx\n"); printf(" -b buffer size in KB\n"); printf(" -n number of read\n\n"); printf(" -s stride skipped before the next access\n\n"); printf("Please don't use non-decimal based number\n"); } int main(int argc, char* argv[]) { unsigned long i, j, size, tmp; unsigned long memsize = 0x800000; /* 1/4 LLC size of skylake, 1/5 of broadwell */ unsigned long count = 1048576; /* memsize / 64 * 8 */ unsigned int stride = 64; /* skipped amount of memory before the next access */ unsigned long sec, usec; struct timeval tv1, tv2; struct timezone tz; unsigned int *indices; while (argc-- > 0) { if ((*argv)[0] == '-') { /* look at first char of next */ switch ((*argv)[1]) { /* look at second */ case 'b': argv++; argc--; memsize = atoi(*argv) * 1024; break; case 'n': argv++; argc--; count = atoi(*argv); break; case 's': argv++; argc--; stride = atoi(*argv); break; default: usage(); exit(1); break; } } argv++; } char* mem = mmap(NULL, memsize, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON, -1, 0); // trick3: init pointer chasing, per stride=8 byte size = memsize / stride; indices = malloc(size * sizeof(int)); for (i = 0; i < size; i++) indices[i] = i; // trick 2: fill mem with pointer references for (i = 0; i < size - 1; i++) *(char **)&mem[indices[i]*stride]= (char*)&mem[indices[i+1]*stride]; *(char **)&mem[indices[size-1]*stride]= (char*)&mem[indices[0]*stride]; register char **p = (char **) mem; //char **p = (char **) mem; tmp = count / 100; gettimeofday (&tv1, &tz); for (i = 0; i < tmp; ++i) { HUNDRED; //trick 1 } gettimeofday (&tv2, &tz); char **touch = p; if (tv2.tv_usec < tv1.tv_usec) { usec = 1000000 + tv2.tv_usec - tv1.tv_usec; sec = tv2.tv_sec - tv1.tv_sec - 1; } else { usec = tv2.tv_usec - tv1.tv_usec; sec = tv2.tv_sec - tv1.tv_sec; } printf("Buffer size: %ld KB, stride %d, time %d.%06d s, latency %.2f ns\n", memsize/1024, stride, sec, usec, (sec * 1000000 + usec) * 1000.0 / (tmp *100)); munmap(mem, memsize); free(indices); }
分别在intel 8163和arm 鲲鹏920上执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 $cat run_mem_lat.sh #!/bin/sh #set -x work=./mem-lat buffer_size=1 node=$1 mem=$2 for i in `seq 1 15`; do #echo $i #echo $buffer_size taskset -ac 1 $work -b $buffer_size -s 64 buffer_size=$(($buffer_size*2)) done #sh run_mem_lat.sh Buffer size: 1 KB, stride 64, time 0.001682 s, latency 1.60 ns Buffer size: 2 KB, stride 64, time 0.001685 s, latency 1.61 ns Buffer size: 4 KB, stride 64, time 0.001687 s, latency 1.61 ns Buffer size: 8 KB, stride 64, time 0.001682 s, latency 1.60 ns Buffer size: 16 KB, stride 64, time 0.001688 s, latency 1.61 ns Buffer size: 32 KB, stride 64, time 0.001817 s, latency 1.73 ns Buffer size: 64 KB, stride 64, time 0.005842 s, latency 5.57 ns Buffer size: 128 KB, stride 64, time 0.005838 s, latency 5.57 ns Buffer size: 256 KB, stride 64, time 0.005838 s, latency 5.57 ns Buffer size: 512 KB, stride 64, time 0.005841 s, latency 5.57 ns Buffer size: 1024 KB, stride 64, time 0.006056 s, latency 5.78 ns Buffer size: 2048 KB, stride 64, time 0.006175 s, latency 5.89 ns Buffer size: 4096 KB, stride 64, time 0.006203 s, latency 5.92 ns Buffer size: 8192 KB, stride 64, time 0.006383 s, latency 6.09 ns Buffer size: 16384 KB, stride 64, time 0.007345 s, latency 7.01 ns [root@x86.170 /root] #lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 96 On-line CPU(s) list: 0-95 Thread(s) per core: 2 Core(s) per socket: 24 Socket(s): 2 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz Stepping: 4 CPU MHz: 2500.390 CPU max MHz: 3100.0000 CPU min MHz: 1000.0000 BogoMIPS: 4998.87 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 1024K L3 cache: 33792K NUMA node0 CPU(s): 0-95 //鲲鹏920 #sh run_mem_lat.sh Buffer size: 1 KB, stride 64, time 0.001628 s, latency 1.55 ns Buffer size: 2 KB, stride 64, time 0.001623 s, latency 1.55 ns Buffer size: 4 KB, stride 64, time 0.001613 s, latency 1.54 ns Buffer size: 8 KB, stride 64, time 0.001613 s, latency 1.54 ns Buffer size: 16 KB, stride 64, time 0.001622 s, latency 1.55 ns Buffer size: 32 KB, stride 64, time 0.001613 s, latency 1.54 ns Buffer size: 64 KB, stride 64, time 0.001637 s, latency 1.56 ns Buffer size: 128 KB, stride 64, time 0.003749 s, latency 3.58 ns Buffer size: 256 KB, stride 64, time 0.003320 s, latency 3.17 ns Buffer size: 512 KB, stride 64, time 0.003779 s, latency 3.60 ns Buffer size: 1024 KB, stride 64, time 0.004310 s, latency 4.11 ns Buffer size: 2048 KB, stride 64, time 0.004655 s, latency 4.44 ns Buffer size: 4096 KB, stride 64, time 0.005032 s, latency 4.80 ns Buffer size: 8192 KB, stride 64, time 0.005721 s, latency 5.46 ns Buffer size: 16384 KB, stride 64, time 0.006470 s, latency 6.17 ns [root@ARM 15:58 /root] #lscpu Architecture: aarch64 Byte Order: Little Endian CPU(s): 96 On-line CPU(s) list: 0-95 Thread(s) per core: 1 Core(s) per socket: 48 Socket(s): 2 NUMA node(s): 4 Model: 0 CPU max MHz: 2600.0000 CPU min MHz: 200.0000 BogoMIPS: 200.00 L1d cache: 64K L1i cache: 64K L2 cache: 512K L3 cache: 24576K NUMA node0 CPU(s): 0-23 NUMA node1 CPU(s): 24-47 NUMA node2 CPU(s): 48-71 NUMA node3 CPU(s): 72-95
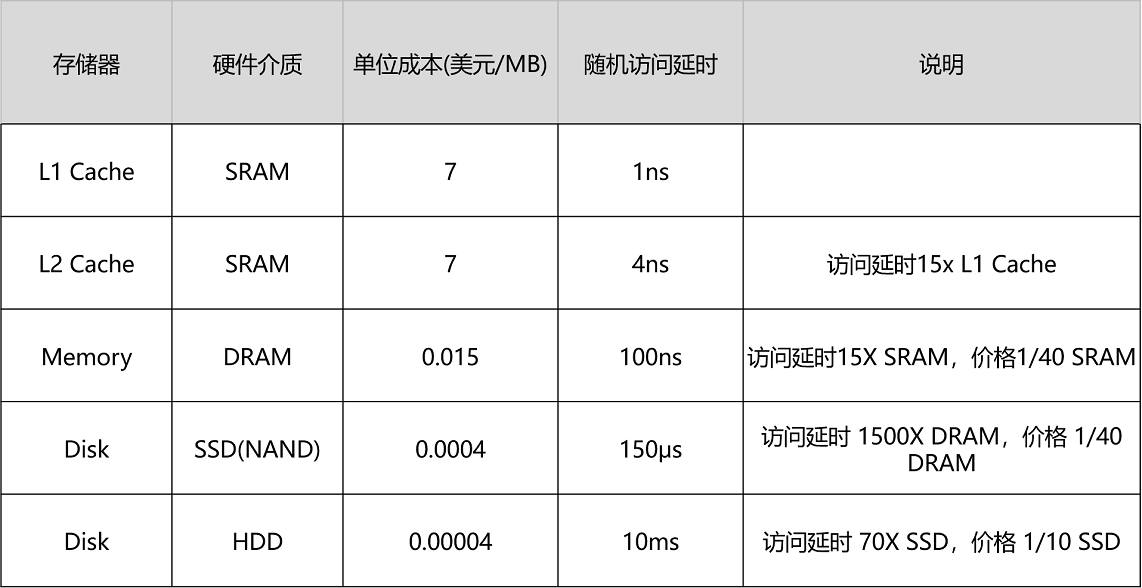
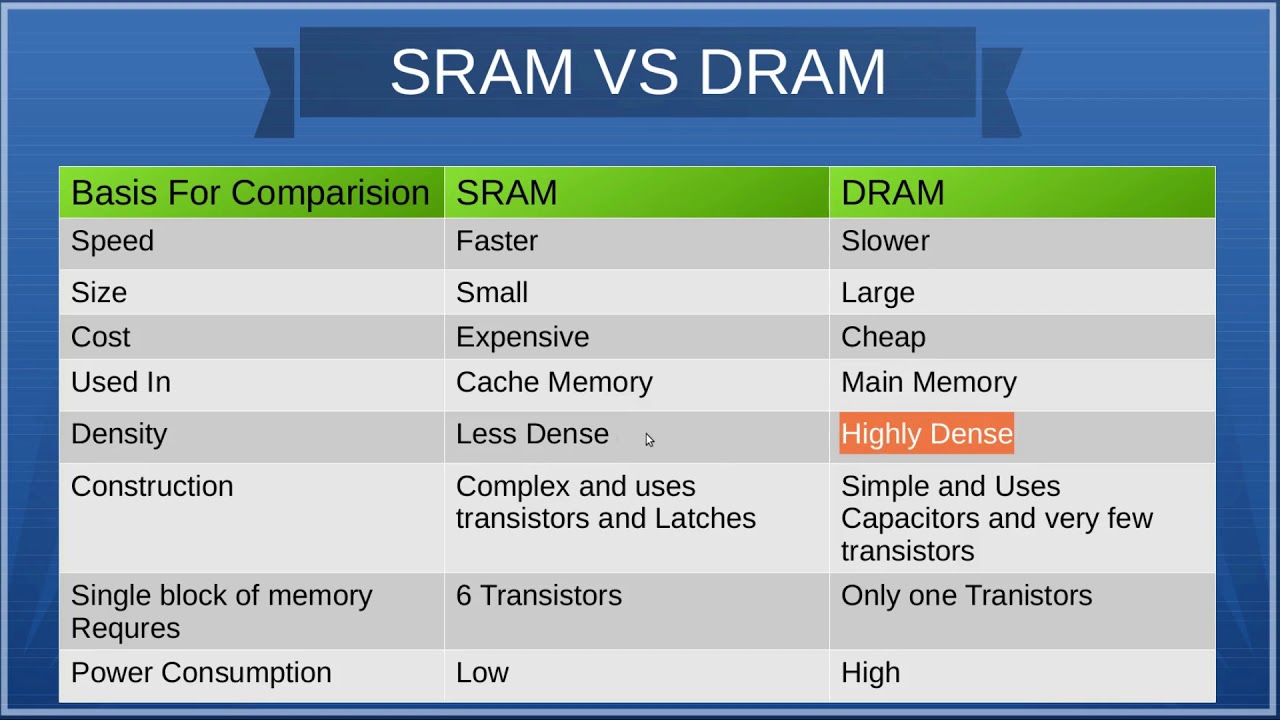
为什么CACHE比内存快? 首先肯定是距离的原因,另外这两种存储结构的制造工艺不同导致的速度差异也很大,从上面可以看到一块4000刀的CPU有一半的面积是cache,也就是40M CACHE花了2000刀,如果用来买内存条能卖一大堆吧。
接下来说下CACHE(SRAM) 和内存(DRAM)制造的工艺差异
SRAM(Static Random-Access Memory,静态随机存取存储器)的芯片 CPU Cache 用的是一种叫作 SRAM(Static Random-Access Memory,静态随机存取存储器)的芯片。
SRAM 之所以被称为”静态”存储器,是因为只要处在通电状态,里面的数据就可以保持存在。而一旦断电,里面的数据就会丢失了。在 SRAM 里面,一个比特的数据,需要 6~8 个晶体管。所以 SRAM 的存储密度不高。同样的物理空间下,能够存储的数据有限。不过,因为 SRAM 的电路简单,所以访问速度非常快。
L1和L2一般是SRAM, L1的容量通常比L2小,容量大的SRAM访问时间就越长,同样制程和设计的情况下,访问延时与容量的开方大致是成正比 的。
另外工作原理不同速度差异也不一样,L1就是讲究快,比如L1是N路组相联,N路阻相联的意思就是N个Cache单元同时读取数据(有点类似RAID0)。
L3用的还是SRAM,但是在考虑换成STT-MRAM,这样容量更大。
DRAM(Dynamic Random Access Memory,动态随机存取存储器)的芯片 为磁芯存储器画上句号的是集成电路随机存储器件。1966年,IBM Thomas J. Watson研究中心的Dr. Robert H. Dennard开发出了单个单元的动态随机存储器DRAM,DRAM每个单元包含一个开关晶体管和一个电容,利用电容中的电荷存储数据。因为电容中的电荷会泄露,需要每个周期都进行刷新重新补充电量,所以称其为动态随机存储器。
内存用的芯片和 Cache 有所不同,它用的是一种叫作 DRAM(Dynamic Random Access Memory,动态随机存取存储器)的芯片,比起 SRAM 来说,它的密度更高,有更大的容量,而且它也比 SRAM 芯片便宜不少。
动态随机存取存储器(DRAM)是一种半导体存储器,主要的作用原理是利用电容内存储电荷的多寡来代表一个二进制比特(bit)是1还是0。由于在现实中晶体管会有漏电电流的现象 ,导致电容上所存储的电荷数量并不足以正确的判别数据,而导致数据毁损。因此对于DRAM来说,周期性地充电是一个无可避免的要件。由于这种需要定时刷新的特性,因此被称为“动态”存储器。相对来说,静态存储器(SRAM)只要存入数据后,纵使不刷新也不会丢失记忆。
DRAM 的一个比特,只需要一个晶体管和一个电容就能存储。所以,DRAM 在同样的物理空间下,能够存储的数据也就更多,也就是存储的”密度”更大。DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问延时也就更长。
SRAM是比DRAM 更为昂贵,但更为快速、非常低功耗(特别是在空闲状态)。 因此SRAM 首选用于带宽要求高,或者功耗要求低,或者二者兼而有之。 SRAM 比起DRAM 更为容易控制,也更是随机访问。 由于复杂的内部结构,SRAM 比DRAM 的占用面积更大,因而不适合用于更高储存密度低成本的应用,如PC内存。
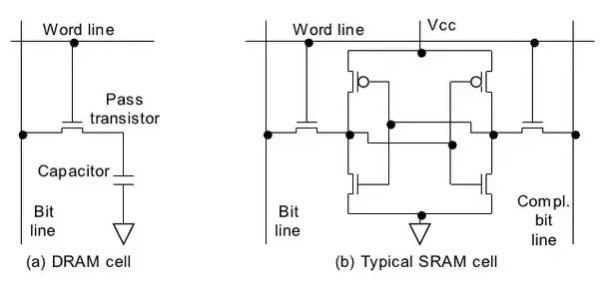
SRAM和DRAM原理比较 简单说DRAM只有一个晶体管和一个电容,SRAM就复杂多了,需要6个晶体管
图左边的 DRAM 的状态是保持在电容器C中。晶体管M用来控制访问。如果要读取状态,拉升访问线AL,这时,可能会有电流流到数据线DL上,也可能没有,取决于电容器是否有电。如果要写入状态,先设置DL,然后升起AL一段时间,直到电容器充电或放电完毕。
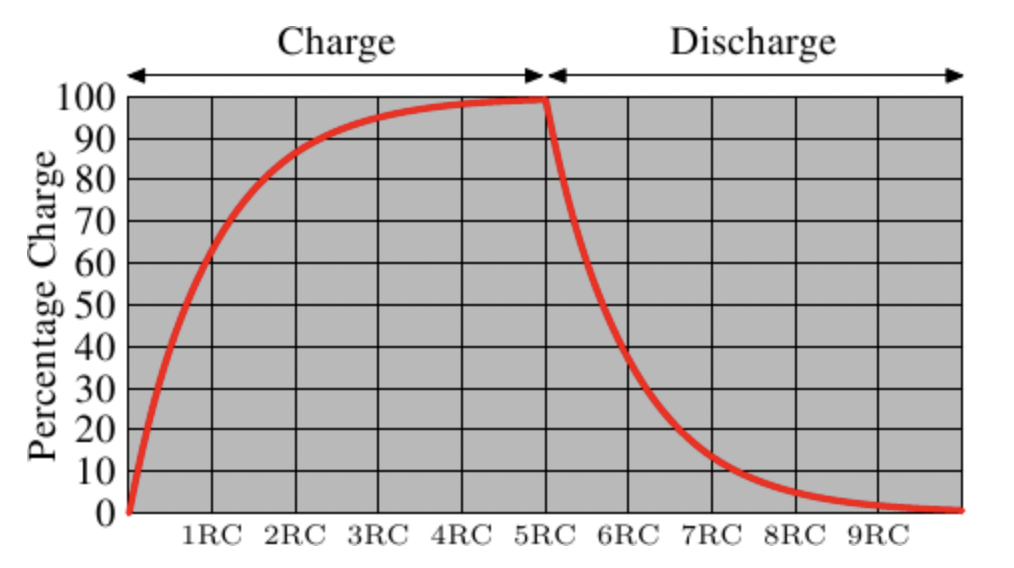
由于读取状态时需要对电容器放电,所以这一过程不能无限重复,不得不在某个点上对它重新充电。更糟糕的是,为了容纳大量单元(现在一般在单个芯片上容纳109以上的RAM单元),电容器的容量必须很小(0.000000000000001法拉以下)。这样,完整充电后大约持有几万个电子。即使电容器的电阻很大(若干兆欧姆),仍然只需很短的时间就会耗光电荷,称为「泄漏」。
这种泄露就是现在的大部分DRAM芯片每隔64ms就必须进行一次刷新的原因。在刷新期间,对于该芯片的访问是不可能的,这甚至会造成半数任务的延宕。(相关内容请察看【highperfdram】一章)
这个问题的另一个后果就是无法直接读取芯片单元中的信息,而必须通过信号放大器将0和1两种信号间的电势差增大,才能分辨出来。
DRAM 主要靠电容充放电来识别0和1,但是充放电是一个持续过程,需要耗时,这也是导致内存延时大的主要原因
不像SRAM可以即刻读取数据,当要读取DRAM的时候,必须花一点时间来等待电容的冲放电完全。这一点点的时间最终限制了DRAM的速度。
SRAM 需要注意以下问题:
一个单元需要6个晶体管。也有采用4个晶体管的SRAM,体积大、贵、结构复杂。
维持状态需要恒定的电源。
升起WL后立即可以读取状态 。信号与其它晶体管控制的信号一样,是直角的(快速在两个状态间变化)。
状态稳定,不需要刷新循环。
SRAM也有其它形式,不那么费电,但比较慢。由于我们需要的是快速RAM,因此不在关注范围内。这些较慢的SRAM的主要优点在于接口简单,比动态RAM更容易使用。
详细比较:
SRAM 也有其它形式,不那么费电,但比较慢。由于我们需要的是快速RAM,因此其它形式的 SRAM 不在关注范围内。这些较慢的SRAM的主要优点在于接口简单,比动态RAM更容易使用。CPU cache用的是快速 SRAM,本文提到的 SRAM 都是指快速 SRAM
DRAM 刷新 DRAM内存内部使用电容来存储数据,由于电容有漏电现象,经过一段时间电荷会泄放,导致数据不能长时间存储。因此需要不断充电,这个充电的动作叫做刷新。自动刷新是以“行”为单位进行刷新,刷新操作与读写访问无法同时进行,即刷新时会对内存的性能造成影响。同时温度越高电容泄放越快,器件手册通常要求芯片表面温度在0℃-85℃时,内存需要按照64ms的周期刷新数据,在85℃~95℃时,按照32ms的周期刷新数据。
BIOS中内存刷新速率选项提供了auto选项,可以根据工作温度自动调节内存刷新速率。相比默认32ms配置可以提升内存性能,同时确保工作温度在85℃~95℃时内存数据的可靠性。
DRAM 频率 内存实际有3种频率:
核心频率
时钟频率(IO控制器频率)
等效频率(有效数据传输频率)
核心频率就是内存的Cell阵列(内存电容)的刷新频率,只与内存本身物理特性有关,目前频率基本都在133MHz~200MH之间
我们俗称DDR4-2666实际指的是等效频率,是通过上升下降沿进行数据预取放大后的实际数据传输频率,DDR4 prefetch是8,通过bank group提升到核心频率的16倍,所以DDR4的最低起频是133.333MHz*16=2133MHz。DDR(Double Data Rate)因为是在一个时钟周期的上升沿和下降沿个执行预取,所以时钟频率=等效频率/2
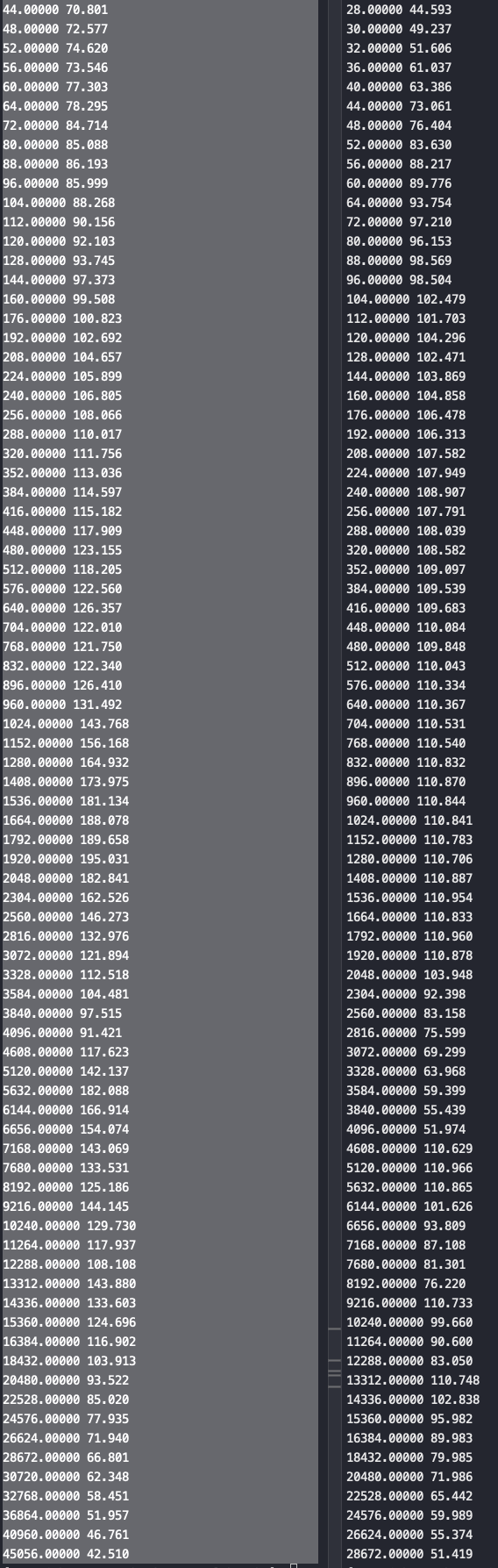
Persistence memory 左边是在32G物理内存的基础上挂了128G pmem, 然后系统通过free能看到 154G内存,用 lat_mem_rd 实际测试速度可以看到左边的机器抖动比较大
系列文章 CPU的制造和概念
[CPU 性能和Cache Line](/2021/05/16/CPU Cache Line 和性能/)
[Perf IPC以及CPU性能](/2021/05/16/Perf IPC以及CPU利用率/)
Intel、海光、鲲鹏920、飞腾2500 CPU性能对比
飞腾ARM芯片(FT2500)的性能测试
十年后数据库还是不敢拥抱NUMA?
一次海光物理机资源竞争压测的记录
[Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的](/2019/12/16/Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的/)
参考资料 Gallery of Processor Cache Effects
7个示例科普CPU CACHE
与程序员相关的CPU缓存知识
45-year CPU evolution: one law and two equations
揭秘 cache 访问延迟背后的计算机原理
业务与芯片垂直整合的一点思考
What Every Programmer Should Know About Main Memory by Ulrich Drepper 中文版:https://zhuanlan.zhihu.com/p/611133924