Netty和Disruptor的cache_line对齐实践
Netty和Disruptor的cache_line对齐实践
原理先看这篇:CPU 性能和Cache Line
写这篇文章的起因是这个 记一次 Netty PR 的提交,然后我去看了下这次提交,发现Netty的这部分代码有问题、这次提交也有问题
什么是 cache_line
CPU从内存中读取数据的时候是一次读一个cache_line到 cache中以提升效率,一般情况下cache_line的大小是64 byte,也就是每次读取64byte到CPU cache中,按照热点逻辑这个cache line中的数据大概率会被访问到。
cache 失效
假设CPU的两个核 A 和 B, 都在各自本地 Cache Line 里有同一个变量1的拷贝时,此时该 Cache Line 处于 Shared 状态。当 核A 在本地修改了变量2,除去把本地变量所属的 Cache Line 置为 Modified 状态以外,还必须在另一个 核B 读另一个变量2前,对该变量所在的 B 处理器本地 Cache Line 发起 Invaidate 操作,标记 B 处理器的那条 Cache Line 为 Invalidate 状态。随后,若处理器 B 在对变量做读写操作时,如果遇到这个标记为 Invalidate 的状态的 Cache Line,即会引发 Cache Miss,从而将内存中最新的数据拷贝到 Cache Line 里,然后处理器 B 再对此 Cache Line 对变量做读写操作。
上面这个过程也叫false-share, 即伪共享,因为变量1、2不是真的关联共享,本来变量1失效不应该导致变量2失效,但是因为cache line机制的存在导致 变量2也失效了,所以这里变量1、2叫false-share
Disruptor中对cache_line的使用
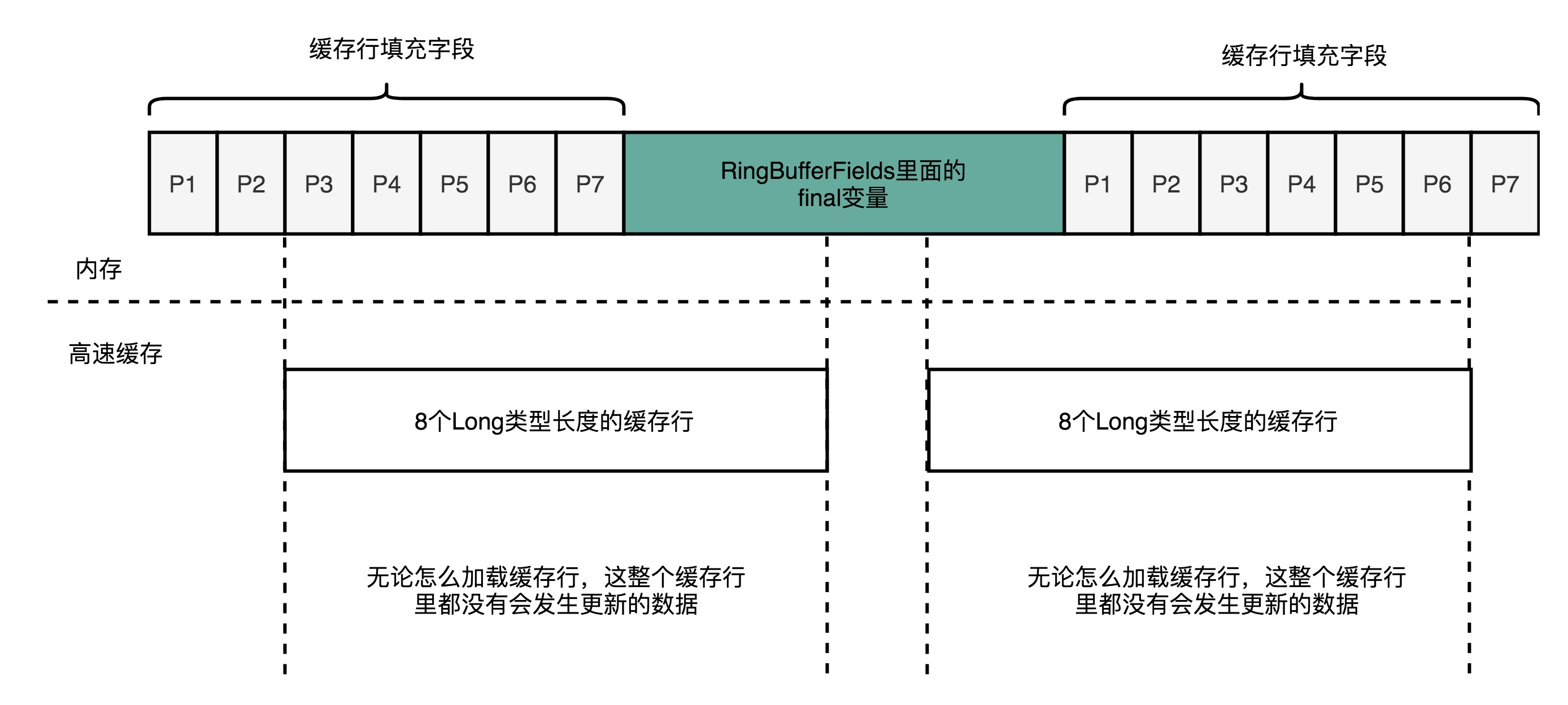
Disruptor中为了保护下面的那几个final 成员变量,前后都加了 p1-p7就是为了避免这4个final成员不要和别的变量放到同一个cache line中。
重点留意下面代码中的p1-p7这几个没有用的long变量,实际使用来占位,占住实际变量前后的位置,这样避免这些变量被其他变量的修改而失效。
1 | abstract class RingBufferPad |
结果如下图所示绿色部分很好地被保护起来一定是独占一个cache line,本来绿色部分都是final,也就是你理解成只读的,不会更改了,这样不会因为共享cache line的变量被修改导致他们所在的cache失效(完全没必要)
队列大部分时候都是空的(head挨着tail),也就导致head 和 tail在一个cache line中,读和写会造成没必要的cache ping-pong,一般可以通过将head 和 tail 中间填充其它内容来实现错开到不同的cache line中
数组(RingBuffer)基本能保证元素在内存中是连续的,但是Queue(链表)就不一定了,连续的话更利于CPU cache
Netty中cache line的对齐
注意下图12行的代码,重点也请注意下11行的注释
1 | // String-related thread-locals |
一看这里也和Disruptor一样想保护某个变量尽量少失效,可是这个实现我看不出来想要保护哪个变量,因为这种保护办法只对齐了一边,还有一边是和别的变量共享cache line。
另外这个代码之前是9个long rp来对齐,这个PR改成了8个,9个就实在是迷惑了(9个long占72bytes了)对齐也是64bytes就好了
还是按照11行注释所说去掉这个对齐的rp吧,要不明确要保护哪些变量,前后夹击真正保护起来,并且做好对比测试
总结
Netty的这段代码纸上谈兵更多一点,Donald E. Knuth 告诉我们不要提前优化
系列文章
[Perf IPC以及CPU性能](/2021/05/16/Perf IPC以及CPU利用率/)
[CPU 性能和Cache Line](/2021/05/16/CPU Cache Line 和性能/)
[Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的](/2019/12/16/Intel PAUSE指令变化是如何影响自旋锁以及MySQL的性能的/)