tcp会偶尔3秒timeout的分析以及如何用php规避这个问题
tcp会偶尔3秒timeout的分析以及如何用php规避这个问题
这是一篇好文章,随着蘑菇街的完蛋,蘑菇街技术博客也没了,所以特意备份一下这篇
作者:蚩尤
时间:May 27, 2014
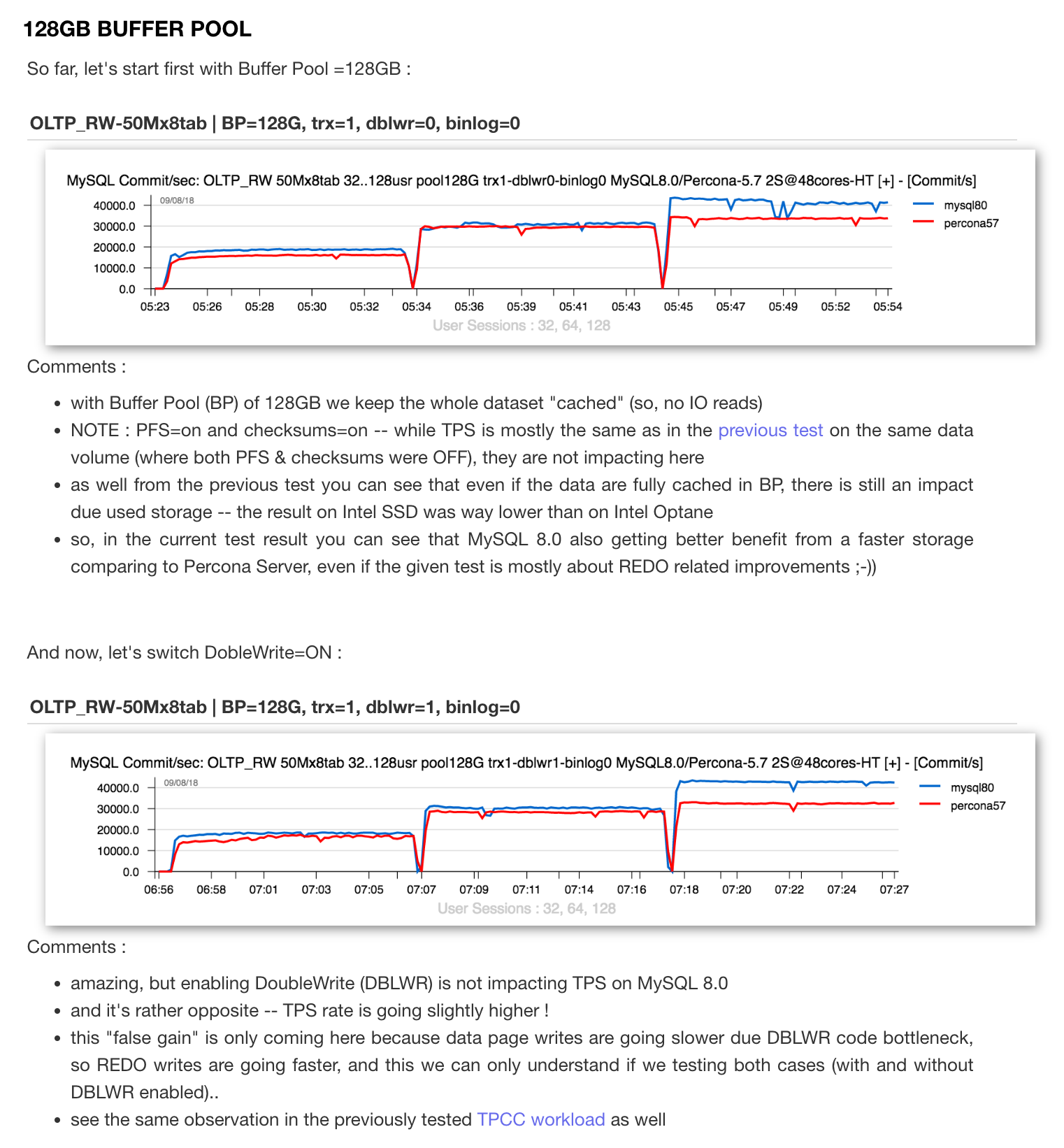
2年前做一个cache中间件调用的时候,发现很多通过php的curl调用一个的服务会出现偶尔的connect_time超时, 表现为get_curlinfo的connect_time在3秒左右, 本来没怎么注意, 因为客户端的curl_timeout设置的就是3秒, 某天, 我把这个timeout改到了5秒后, 发现了一个奇怪的现象, 很多慢请求依旧表现为connect_time在3秒左右..看来这个3秒并不是因为客户端设置的timeout引起的.于是开始查找这个原因.
首先, 凭借经验调整了linux内核关于tcp的几个参数
1 | net.core.netdev_max_backlog = 862144 |
经过观察发现依旧会有3秒超时, 而且数量并没有减少.
第二步, 排除是大并发导致的问题, 在一台空闲机器上也部署同样的服务, 仅让线上一台机器跑空闲机器的服务, 结果发现依旧会有报错.排除并发导致的问题.
最后, 通过查了大量的资料才发现并不是我们才遇到过这个问题, 而且这个问题并不是curl的问题, 它影响到所有tcp的调用, 网上各种说法, 但结论都指向linux内核对于tcp的实现.(某些版本会出现这些问题), 有兴趣的可以看下下面这两个资料.
资料1
资料2
一看深入到linux内核..不管怎样修改的成本一定很大..于是乎, 发挥我们手中的php来规避这个问题的时间到了.
原本的代码, 简单实现,常规curl调用:
1 | function curl_call($p1, $p2 ...) { |
可以看出, 如果用上面的代码, 无法避免3秒connect_time的问题..这种实现对curl版本会有要求(CURLOPT_CONNECTTIMEOUT_MS),主要的思路是,通过对链接时间进行毫秒级的控制(因为超时往往发生在connect的时候),加上失败重试机制,来最大限度保证调用的正确性。所以,下面的代码就诞生了:
1 | function curl_call($p1, $p2, $times = 1) { |
上面这段代码只是一个规避的简单实例, 一些小细节并没有可以完善..比如抛出异常常以后curl资源的手动释放等等..这里不做讨论..当然还漏了一点要说的是,对重试次数最好加上限制 :)
说明一下上面几个数字值的含义:
1 | 462850 //因为php的CURLOPT_CONNECTTIMEOUT_MS需要 curl_version 7.16.2,这个值就是这个版本的数字版本号,还需要注意的是, php版本要大于5.2.3 |
这样这个问题就这样通过php的代码来规避开了.
如果有对这个问题有更好的解决方法,欢迎指教.
总结
tcp connect 的流程是这样的:
1、tcp发出SYN建链报文后,报文到ip层需要进行路由查询
2、路由查询完成后,报文到arp层查询下一跳mac地址
3、如果本地没有对应网关的arp缓存,就需要缓存住这个报文,发起arp请求
4、arp层收到arp回应报文之后,从缓存中取出SYN报文,完成mac头填写并发送给驱动。
问题在于,arp层缓存队列长度默认为3。如果你运气不好,刚好赶上缓存已满,这个报文就会被丢弃。
TCP层发现SYN报文发出去3s(默认值)还没有回应,就会重发一个SYN。这就是为什么少数连接会3s后才能建链。
幸运的是,arp层缓存队列长度是可配置的,用 sysctl -a | grep unres_qlen 就能看到,默认值为3。